bilinear_kernel这个函数有没有大佬详细解释一样啊 
module ‘d2l.torch’ has no attribute ‘Image’
我在coalb上边运行,在读入图片那部分会显示这个错误,这需要怎么修改呢
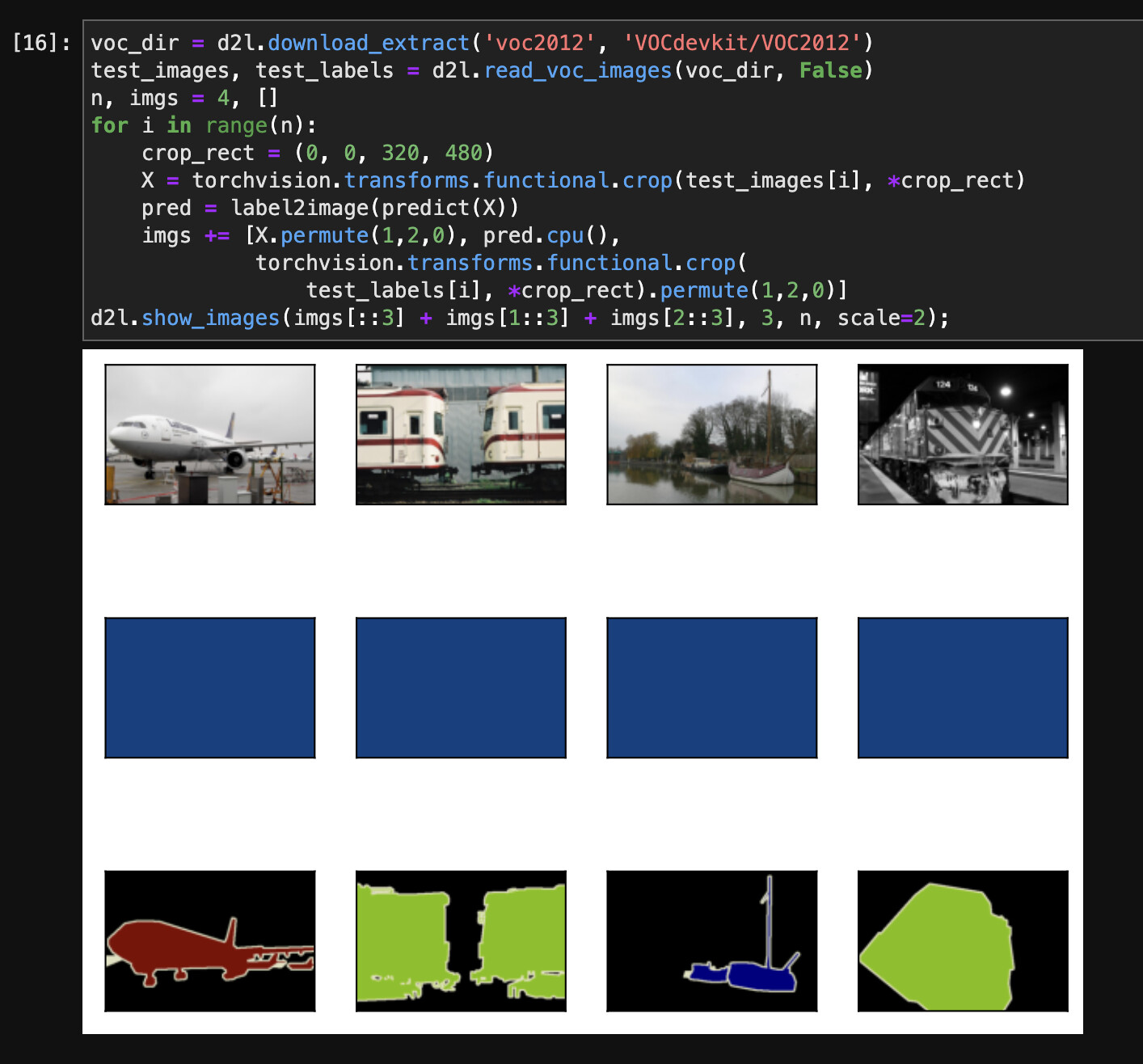
我也和你出现了一样的情况,甚至在训练后的训练图中,没有出现训练损失的曲线,请问您现在解决了吗?
PyTorch使用单GPU训练结果就是正确的,使用多GPU训练结果就会出错。
据此设计的卷积核形状如同“金字塔/四棱锥”,且只有k=2*s时才可以
也许是d2l的版本太老了,直接去下载d2l的源码。然后只要在自己项目下新建个d2l文件夹,把torch.py放进去就OK了。可以从这里下载https://github.com/d2l-ai/d2l-zh/tree/master/d2l
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
center = (kernel_size - 1) / 2
print(center)
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
filt = (1 - torch.abs(og[0] - center) / factor) * \
(1 - torch.abs(og[1] - center) / factor)
print(filt)
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
weight[range(in_channels), range(out_channels), :, :] = filt
return weight
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2,
bias=False)
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4));
这样或许更容易理解。
理解双线性插值的数学理论就可以了吧,代码 ![]()
什么不直接训练一个原图到样式的,损失函数直接设定成像素的统计函数就好了呀,这里为什么需要一个原图的特征抽取网络呀
改单GPU后,出现OUT OF MEMORY错误
CUDA out of memory,Tried to allocate 76.00 MiB (GPU 0; 8.00 GiB total capacity; 1.10 GiB already allocated; 5.78 GiB free; 1.11 GiB reserved in total by PyTorch) 内存是够的
batch_size = 8 ,solved
opencv学习中,关于图像的放大缩小原理,里面所使用到的“双线性插值法”,它希望图片在放大过程中,原像素点位置按比例放大后,利用“双线性插值法”在新的位置与位置之间,根据线性关系,计算像素点之间的过渡像素值。(在此处应该是小尺寸图像在放大过程中会引起区域像素值不连续,打个比方就是不希望反卷积得到的最终图像是个乱七八糟的马赛克图)