http://d2l.ai/chapter_multilayer-perceptrons/mlp-concise.html
Just ask for a clarification.
The nn.Linear() in pytorch will initialize bias with some non-zero values, hence the weights initialization for the bias terms in the section has a little bit differences from section 4.2.
Please let me know if my understanding has any problems. Thanks in advance.
Yes @Angryrou. You are right. There is a difference in bias term initialization in section 4.3 vs 4.2.
@Angryrou Section 4.2 implements everything from scratch and hence we initialize each parameter manually. On the other hand with Section 4.3 we are doing a concise implementation. Thus we just apply the initialization on pytorch linear layer parameters in the model.
Note: This step can be skipped as pytorch by default initializes the params in nn.Linear layer like here. But to make sure we use similar initialization for concise and scratch implementations we use the following to apply weights in pytorch section 4.3.
def init_weights(m):
if type(m) == nn.Linear:
torch.nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
Let me know of this helps 
4 Likes
I tried adding an additional layer and, just to see what happens, increasing the number of epochs we train for from 10 to 50. I would have expected this to cause overfitting - train loss to zero, train acc to 100%, test acc to start to fall. I was also wondering if I’d see ‘double descent’ here. But instead the graph just went wild:
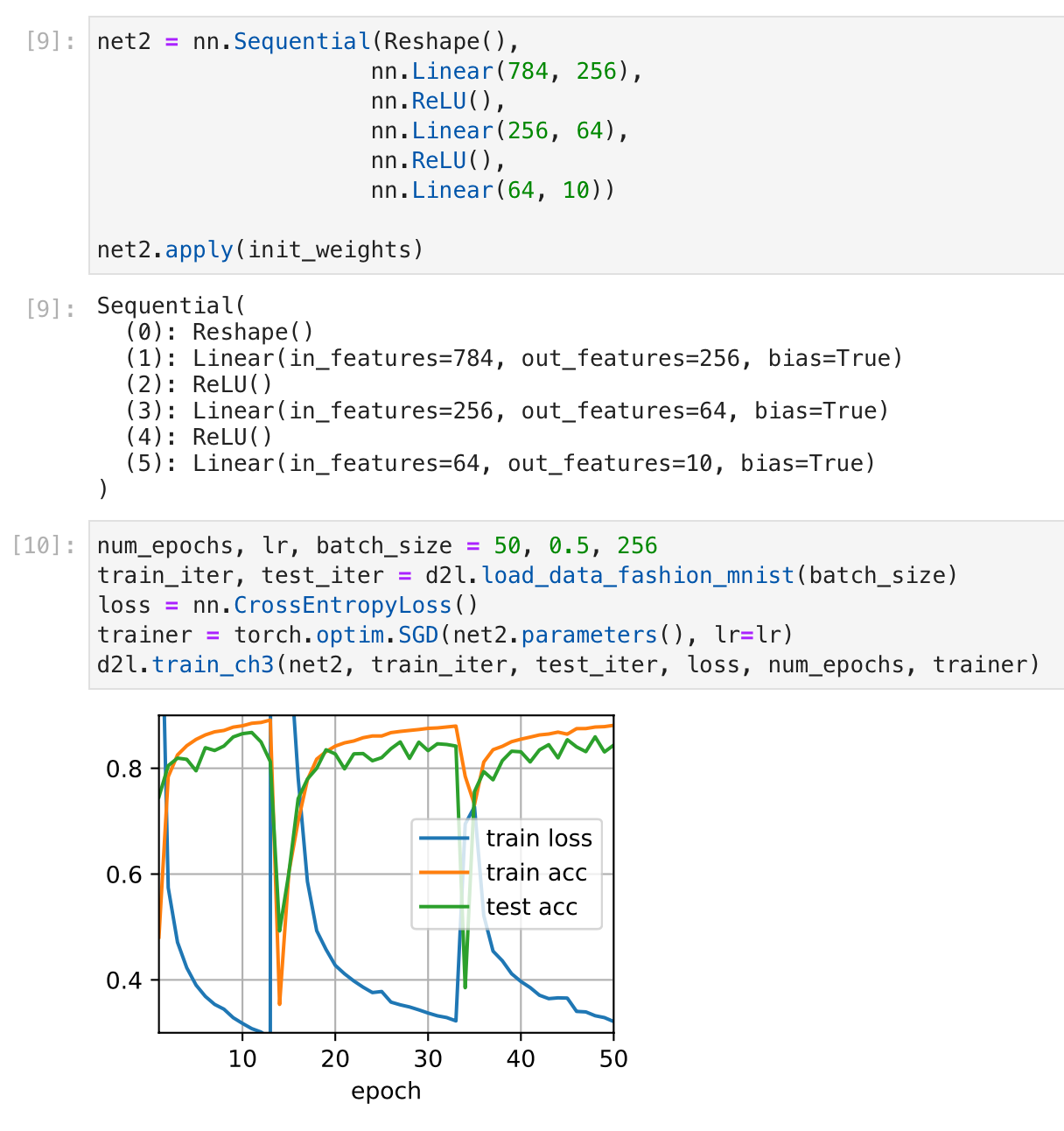
Any idea why this might have happened? Is there something under the hood that causes parameters to reset every so often?
It didn’t happen when I train.Cost me an hour.  (find some bugs and search on web)
(find some bugs and search on web)

Please let me know what you ran in the previous 8 code cells.
What is the function to find out what exactly happened in every layer. @anirudh
I can only post one image as a new user but, this is everything I ran before the cells I pasted before:
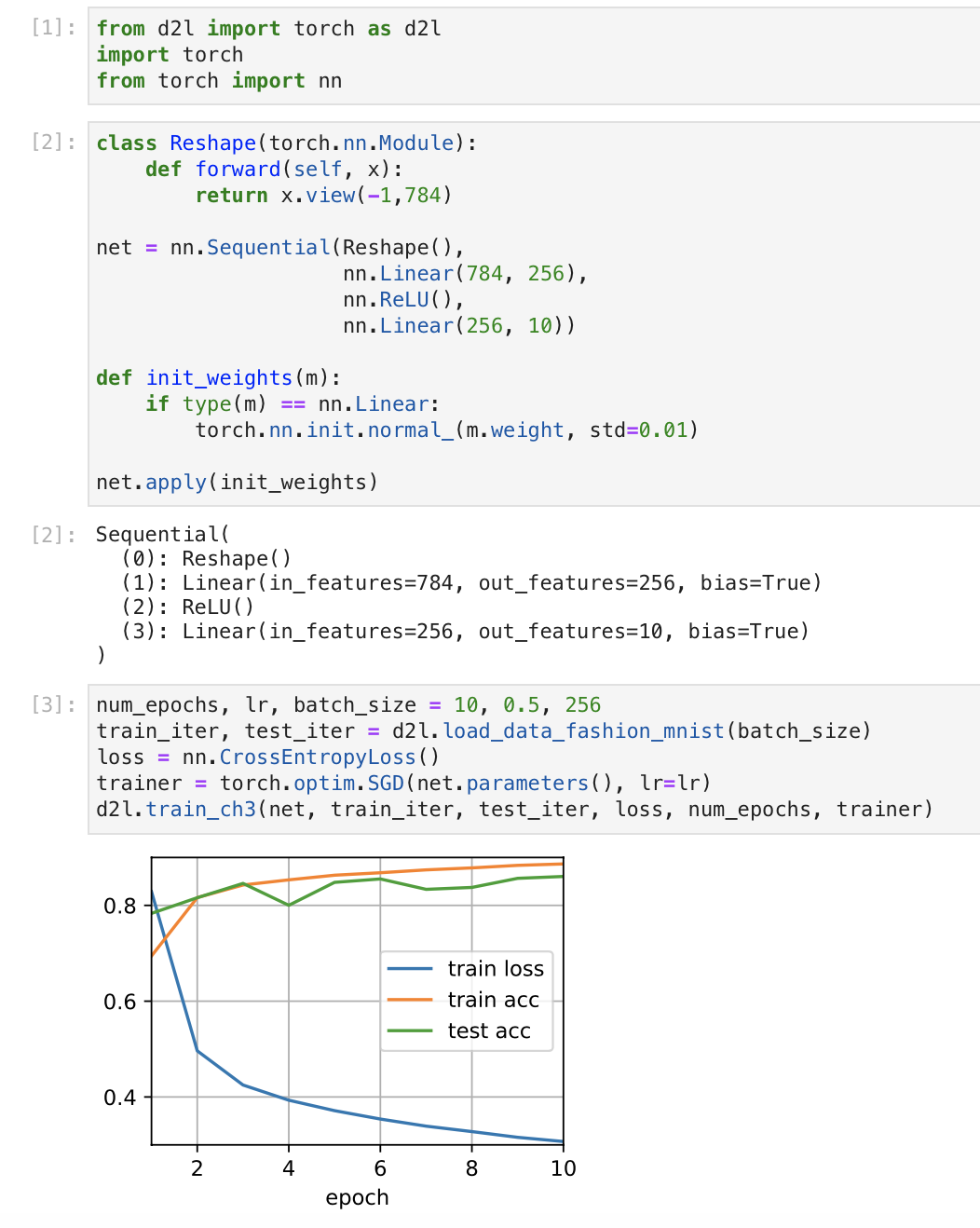
The cell number starts from 9 just because I ran some stuff earlier then deleted the cells. But I just ran it all again from scratch now and it still looks wild. Any idea what mistake I made?
I don’t know. You can post your all code on github. And give us URL to figure it out.
The random init still seems like metaphysics to me.
@Nish I can confirm that I find the same results containing sudden drops in plots with your approach in all the three MXNet, PyTorch and Tensorflow.
My first guess is that, this maybe an issue related to our plot function. Will look into this in detail. Thanks for pointing it out.
Can you please make a github issue on the d2l-en repo, so that it is easier tot track as suggested by @goldpiggy ?
Thanks for the feedback @goldpiggy and @anirudh , I submitted the issue at https://github.com/d2l-ai/d2l-en/issues/1123 - hope it looks alright. Didn’t realise it was an error with the plot function, I was sure I was doing something wrong!
Thanks @Nish , I’ll try to find the reason behind this and get back to you on the issue tracker. I’m not sure but as I said it maybe an error of our plotting function.
Hi @Nish, thanks for submitting the issue! I suspect it might be the “gradient exploding” problem. We haven’t talked about the “gradient clipping” strategy until chapter 8. Can you try grad_clipping here in http://preview.d2l.ai/d2l-en/master/chapter_recurrent-neural-networks/rnn-scratch.html#gradient-clipping to see if it can solve the issue?
If we happen to have multiple hidden layers, is it conventional to apply the same activation function on all the hidden layers or is it based on our neural network and its intended application?
Yes you are right @Kushagra_Chaturvedy. It is common to see “relu” been applied on varies of hidden layers. For example, in the later part of this book, you will see more advanced model (such as http://d2l.ai/chapter_convolutional-modern/nin.html#nin-blocks) where multiple relu are used!
This model on this dataset seems to be very sensitive to several design choices. Replacing relu with leakyrelu, for example, leads to horrible performance (loss=2.3), which is only somewhat alleviated by reducing the lr to .01. Using Adam instead of SGD has similarly bad performance using lr=.1 but improves with lr=.01.
I guess the “art” of DL comes from knowing how changing one hyperparameter will affect all the others 
1 Like
That’s why some deep learning researcher called themselves “alchemists”. ![]()
2 Likes
Great thoughts on this @StevenJokes! Hyperparameter are a set of parameters which you setup before the training, such as learning rate, layer size, layer number, etc. And yes, the AutoML is one of the techniques to optimize the hyperparameters.
1 Like
I was trying to tinker around with the number of layers and epochs. For example
net2 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)def init_weights(m):
if type(m) == nn.Linear:
torch.nn.init.normal_(m.weight, std=0.01)net2.apply(init_weights)
batch_size, lr, num_epochs = 256, 0.1, 100
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net2.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net2, train_iter, test_iter, loss, num_epochs, trainer)print(‘Train Accuracy’,d2l.evaluate_accuracy(net2,train_iter))
print('Test Accuracy ',d2l.evaluate_accuracy(net2,test_iter))d2l.predict_ch3(net2, test_iter)
Train accuracy comes around 0.87, Has anyone reached a training accuracy of close to 1.