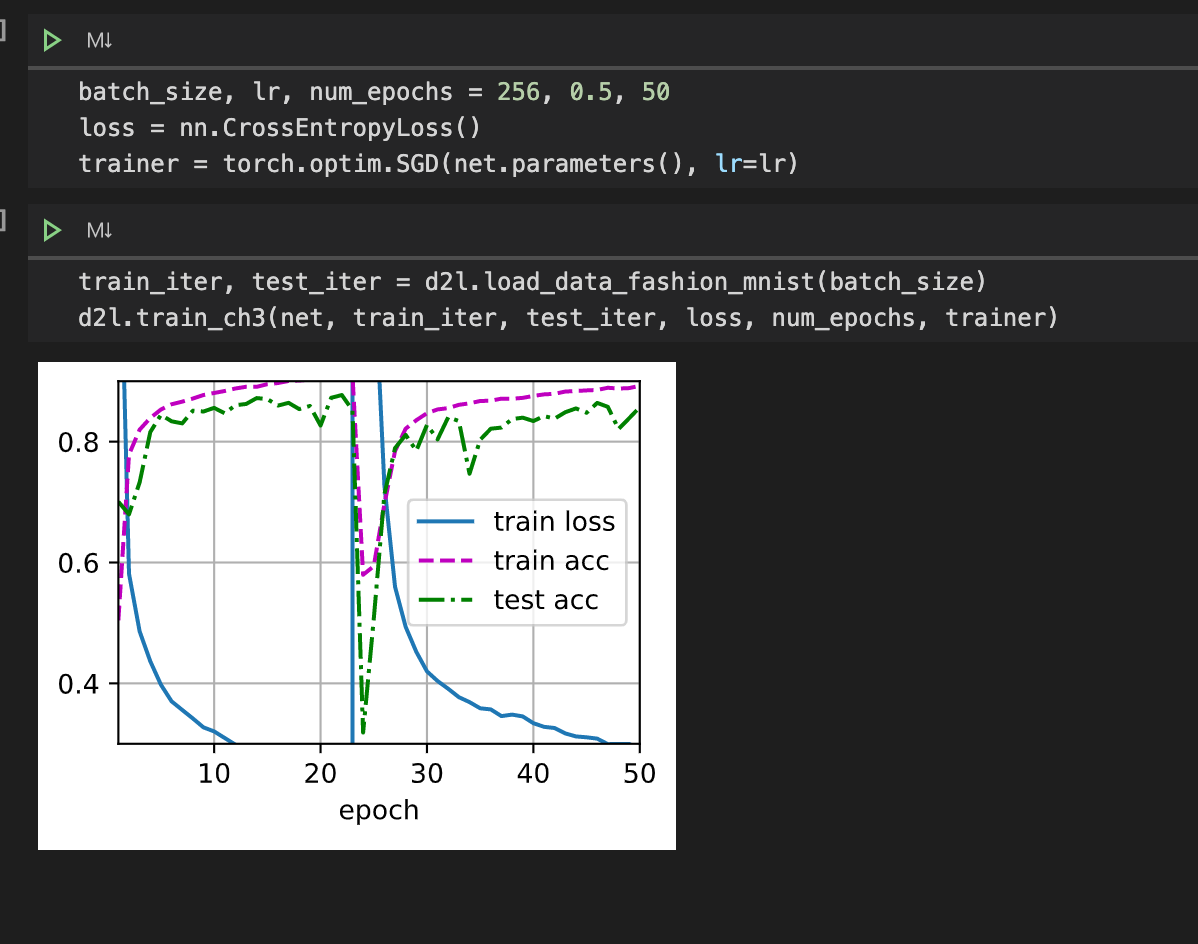
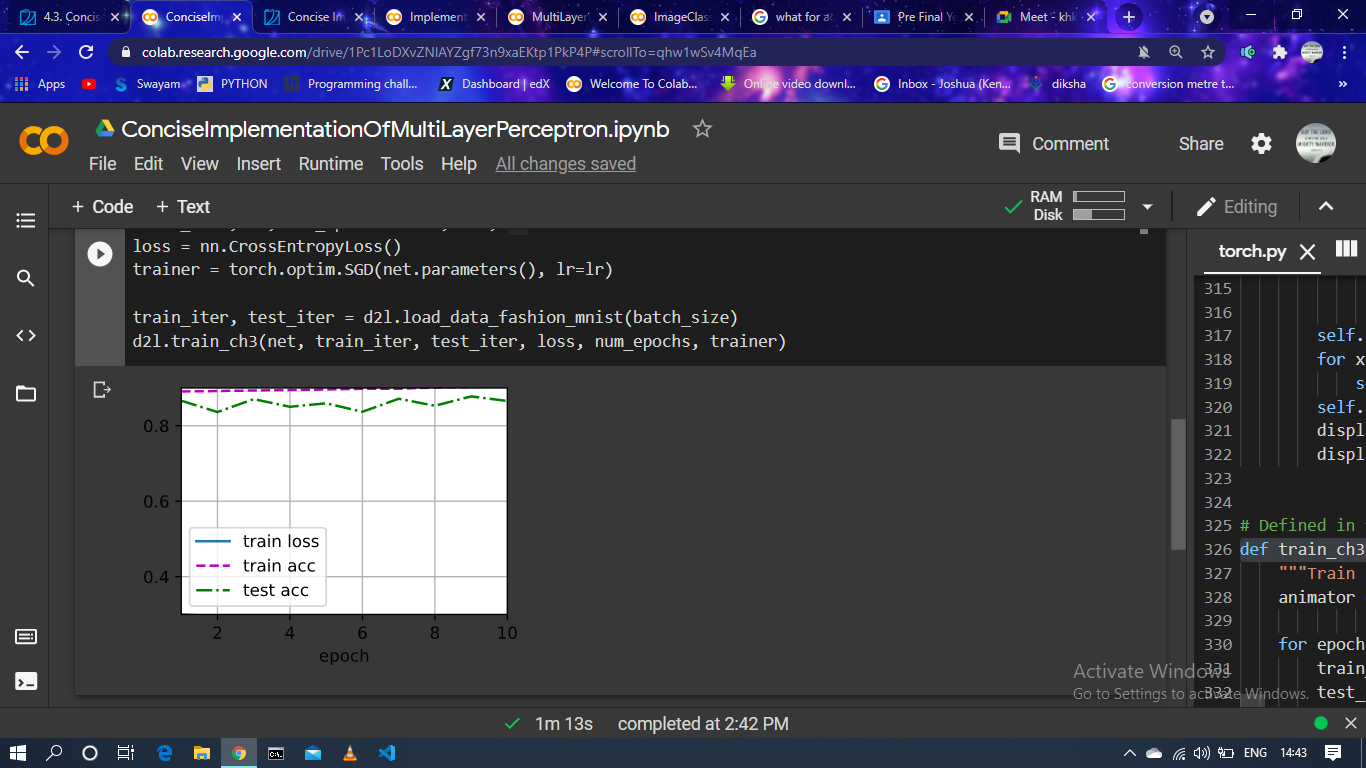
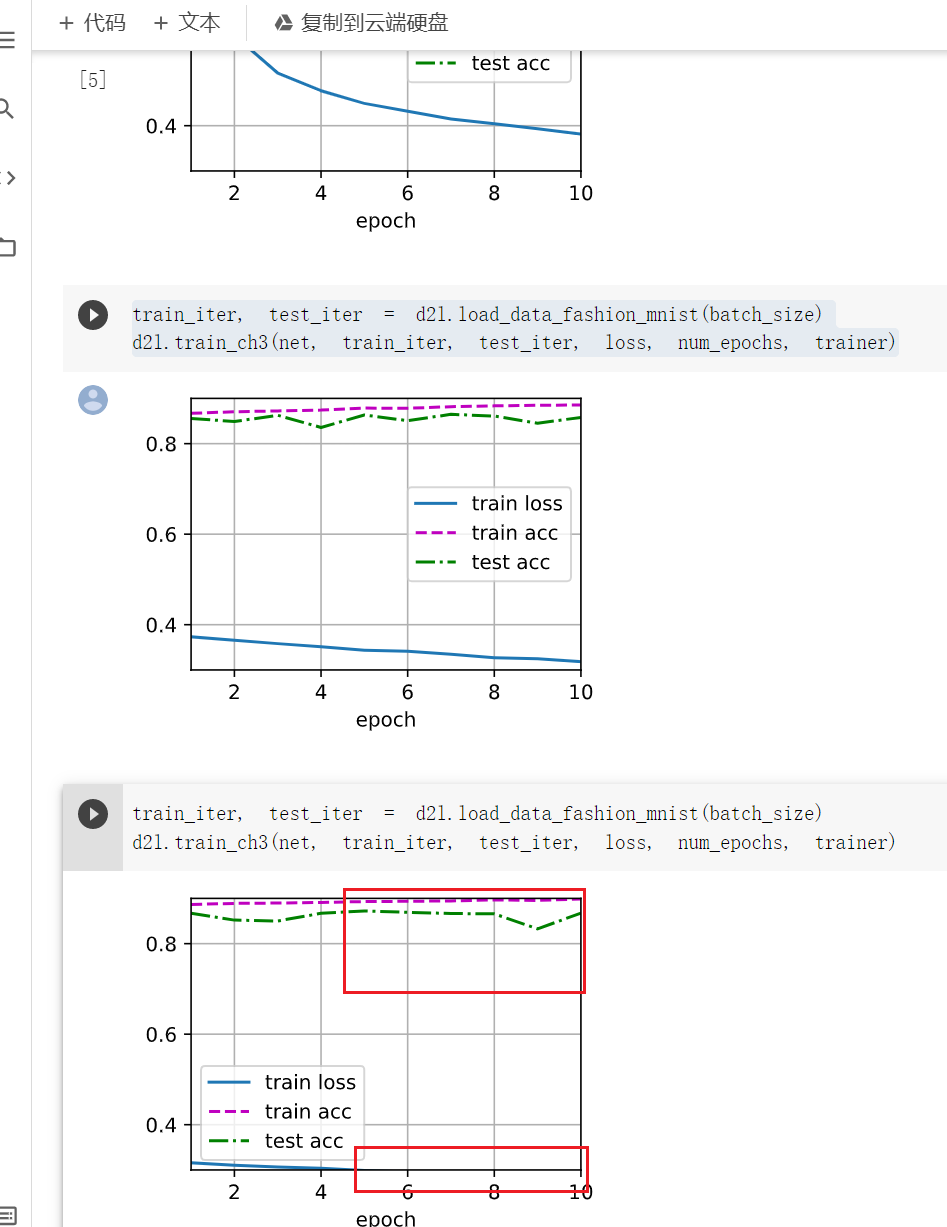
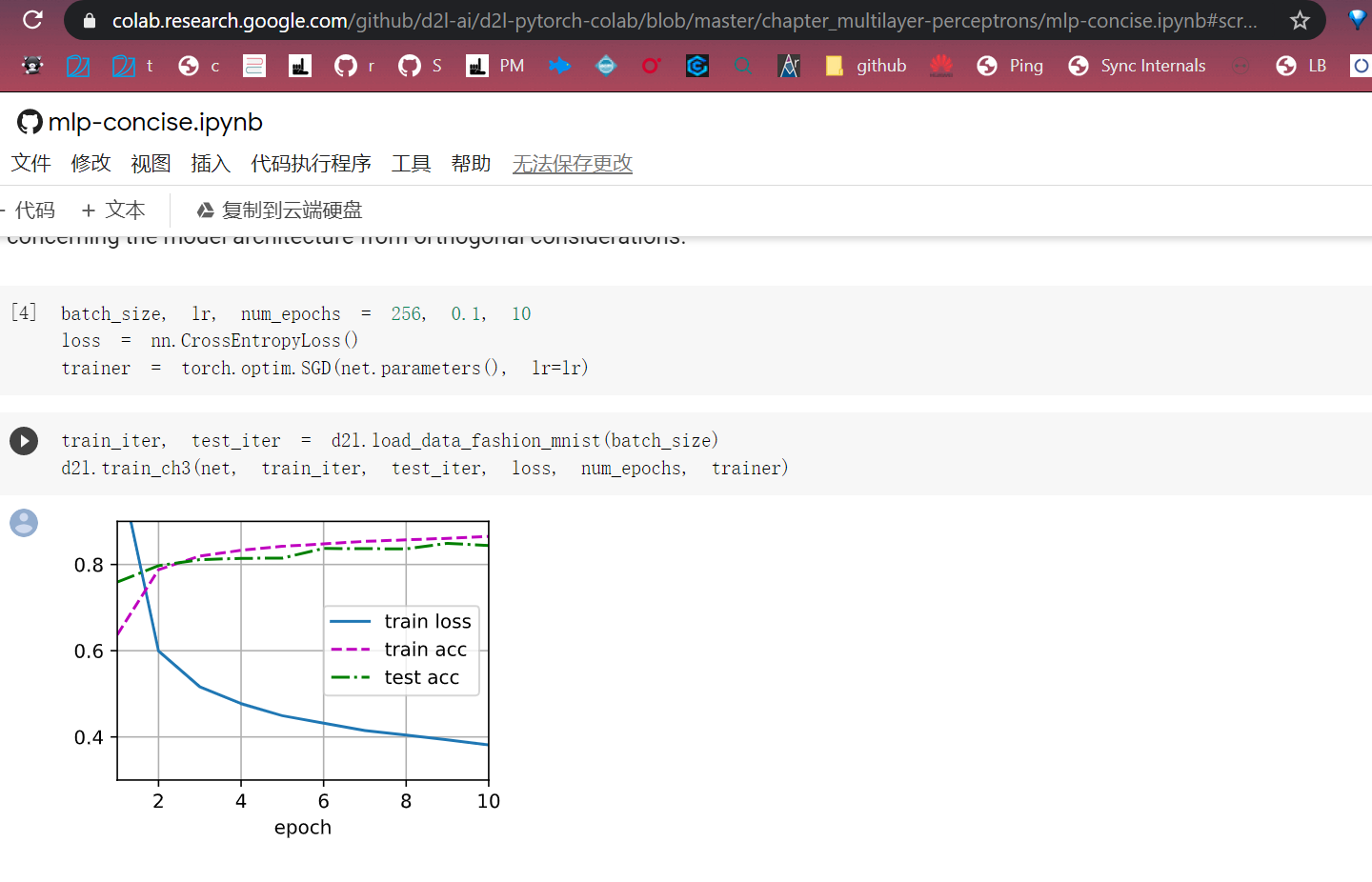
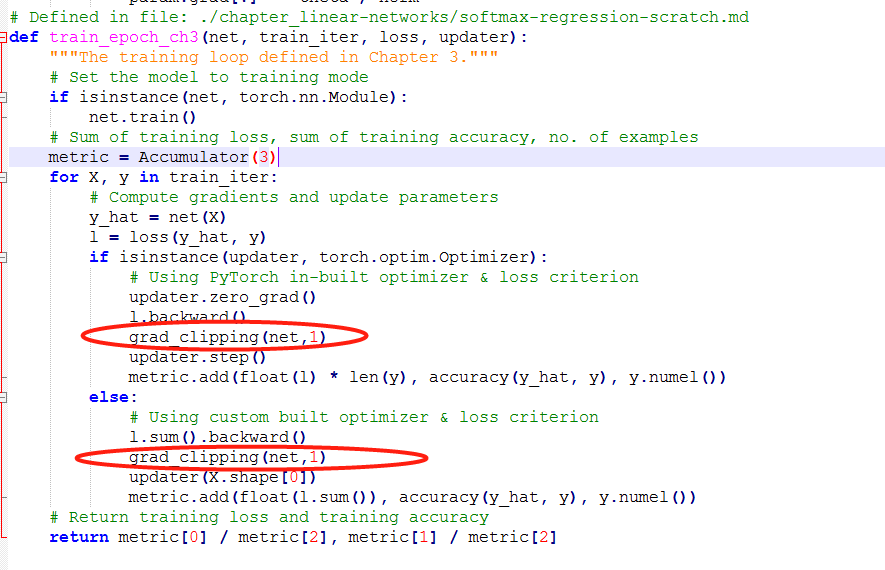
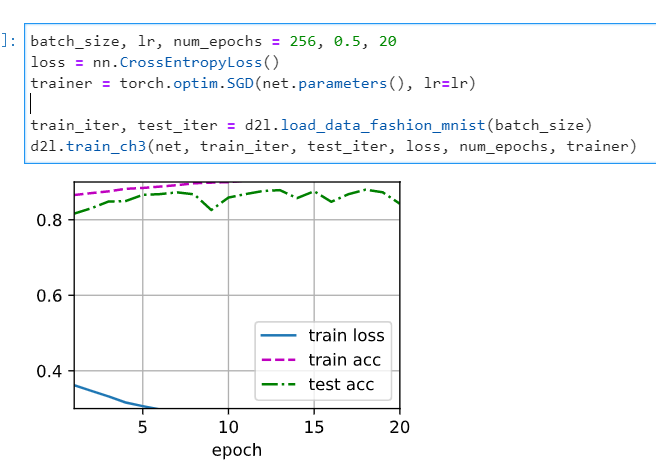
But I think this is normal phenomena as the learning rate increases. Since if the learning rate is too large, the gradient will skip the minimum-point. Such that, the curve will go wild.
@samyfr7
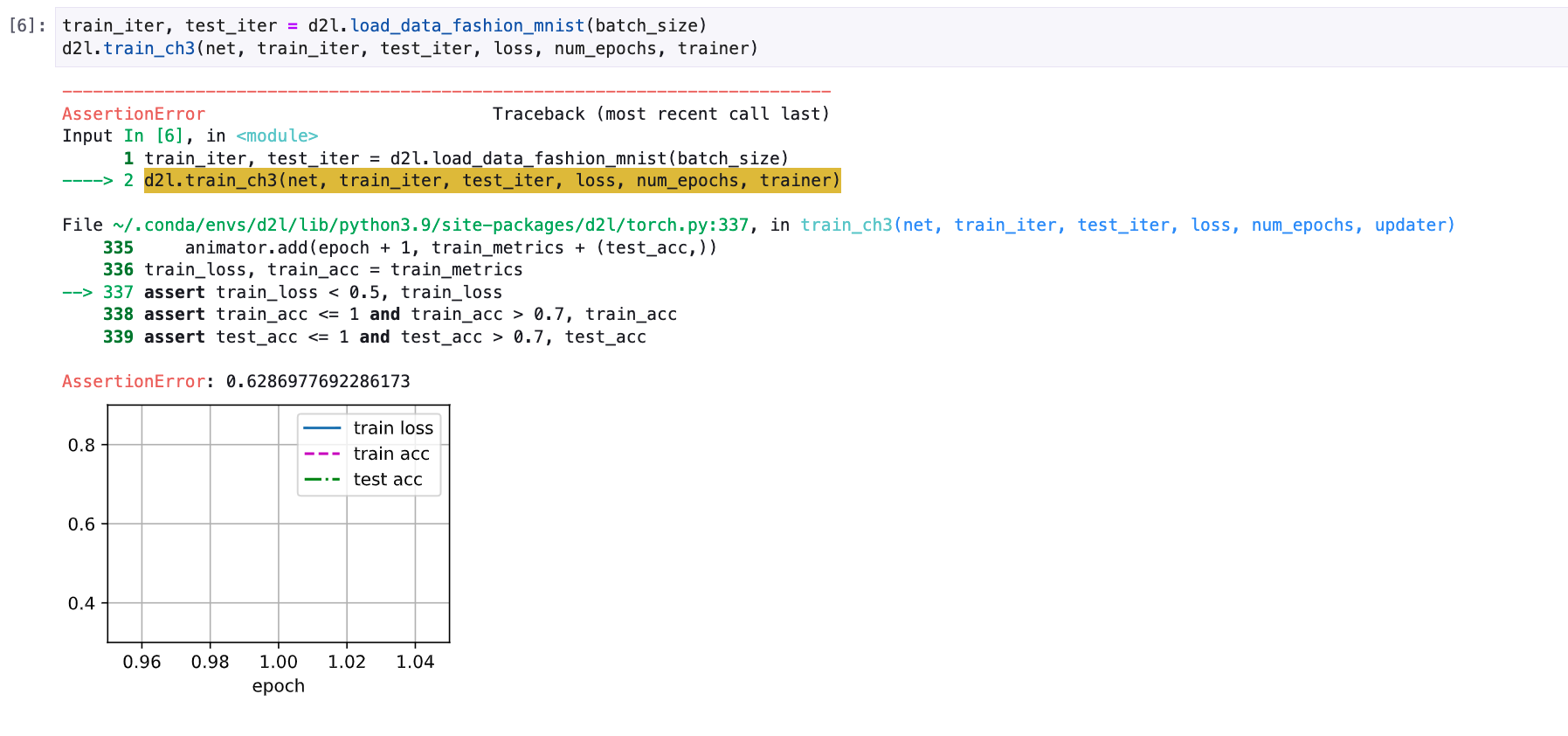
I guess it was caused by that the train loss is too small to show the figure ,which I guess it from high train accuracy.
Oh…You can get my point from my third train:
it looks like the grad_clipping can slove this problem, and beacuse the learning rate is bigger than normal, the learning process is faster than normal.
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
My doubt here is: We are initializing the weights but not passing any parameter to the function.
Morever, I could not find what is the use of net.apply