http://zh-v2.d2l.ai/chapter_natural-language-processing-pretraining/bert-pretraining.html
已经是一维,没必要再转一维。
1 Like
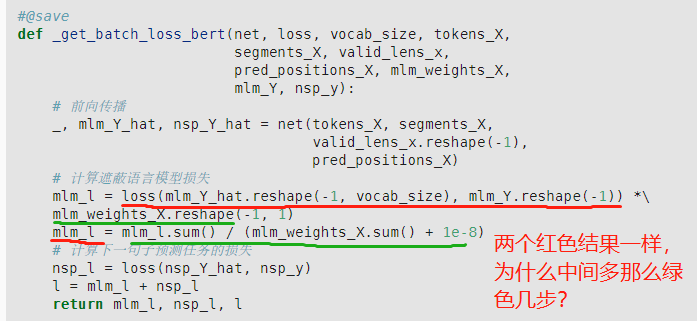
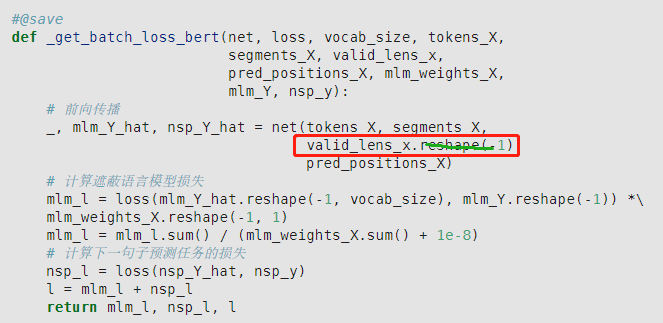
mlm其实用loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1))就可以了,用后面几步,有点多余,而且结果一样。这里我觉得写代码的人想把weight为0的过滤掉,但不是这么写的。这么写还是没有过滤掉。因为loss用的均值,是不行的,要么法1:应该用nn.CrossEntropyLoss(reduction=none),而不是nn.CrossEntropyLoss()。法2:去掉bert数据集中_pad_bert_inputs函数中的max_num_mlm_preds,即不预测max_len的15%, 而是实际有几个,就预测几个,省掉后面weight的麻烦。
2 Likes
法2可能会导致不能用矩阵进行批量计算(pred_positions的shape是[batch, num_pred_positions])
为什么cls编码后shape不一样,查了一下encode没发现对特殊词元的处理
第二问,我测试了一下保持batch_size=512的情况下,使用BERT_base或BERT_large都出现了CUDA_out of memory. 修改了batch_size的大小为128后,可以运行了,但随之train的loss的升高了0.5个百分点。
在用bert表示文本中,请问为什么我对相同语境相同单词进行表示,多次实验结果是不同的(同样的代码运行多次)?
1 Like
小白来自己回答自己的问题,是因为在使用bert生成词向量时,我没有加net.eval(),没进入评估模式,导致每次输入net内部的权重都会发生变化,希望其他小白引以为戒,不要和我犯相同的错误。 ![]()
2 Likes
这个net.eval()要设置在哪里呀,我看书上用BERT表示文本的时候也没有net.eval()呀?
要加在生成向量之前,不然每次生成都是不一样的向量
感觉应该是法一的方法,前面那期介绍MLM任务的时候的示例就是用的reduce=“None”
(1)
loss = nn.CrossEntropyLoss(reduction=“none”)
(2)
mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1))
mlm_l = torch.mul(mlm_l,mlm_weights_X.reshape(-1))
mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)
这样更正确?

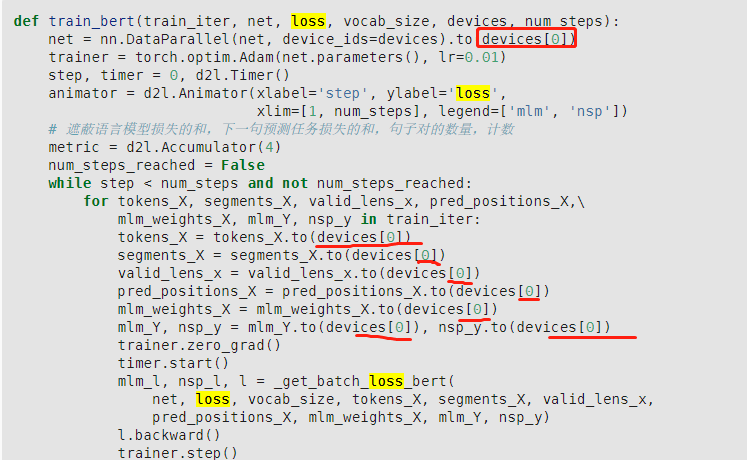
metric = d2l.Accumulator(4)
num_steps_reached = False
while step < num_steps and not num_steps_reached:
for tokens_X, segments_X, valid_lens_x, pred_positions_X,\
mlm_weights_X, mlm_Y, nsp_y in train_iter:
step和epoch的区别是什么?
为什么用step的时候 metric = d2l.Accumulator(4) 这句放在step循环外面?
用epoch的时候累加器是放在epoch循环里面的,这样就不会被上一个epoch的损失影响
因为在transformer编码器中词元已经经过自注意力计算,所以具有整个句子的信息
图一不是一样的吧,一个向量,一个标量,这里nsp_l又是一个向量,后面相加又要广播操作,很奇怪
只需要改两个地方:
(1)loss = nn.CrossEntropyLoss()改为loss = nn.CrossEntropyLoss(reduction=‘none’)
(2)nsp_l = loss(nsp_Y_hat, nsp_y)改为nsp_l = loss(nsp_Y_hat, nsp_y).mean()
why the original code is reasonable to me?
这么说<sep>也可以利用呀,right?