Win10环境,单GPU运行Jupyter以下有错:
- data_dir = d2l.download_extract(‘SNLI’),永远不能解压缩下载的SNLI数据
- class SNLIBERTDataset 中
def _preprocess(self, all_premise_hypothesis_tokens):
pool = multiprocessing.Pool(4) # 使用4个进程
out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)
pool.map函数貌似会卡死。
-
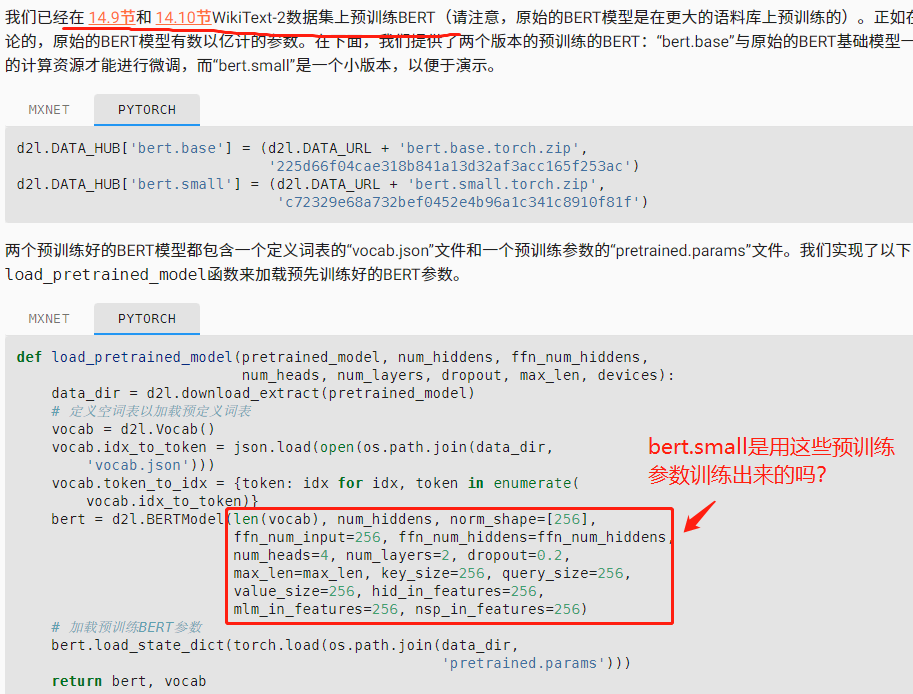
bert.small是用256给出的参数训练出来的吗,前面在14.9和14.10节中预训练bert是用的128训练,怎么这里改成了256?
-
代码里没有设置ignore_stale_grad=true,请问何来设置的呢?

完结撒花
BTW
这篇的代码有BUG,无论是’bert.base’还是’bert.small’,都有不同的BUG
解决方法:
- 关于李沐书籍中“15.7 自然语言推断:微调BERT”节代码问题总结-pudn.com
- 完整BERT存在BUG(网络结构与预训练文件不匹配)解决方法:
李沐动手学深度学习V2-BERT微调和代码实现_cv_lhp的博客-CSDN博客_bert微调代码
上面的方法亲测有效
微调以后的bert模型我应该如何正确保存呢,再次加载优势如何加载的呢
中文版居然比英文版少了7章内容,而且很多术语还不一致
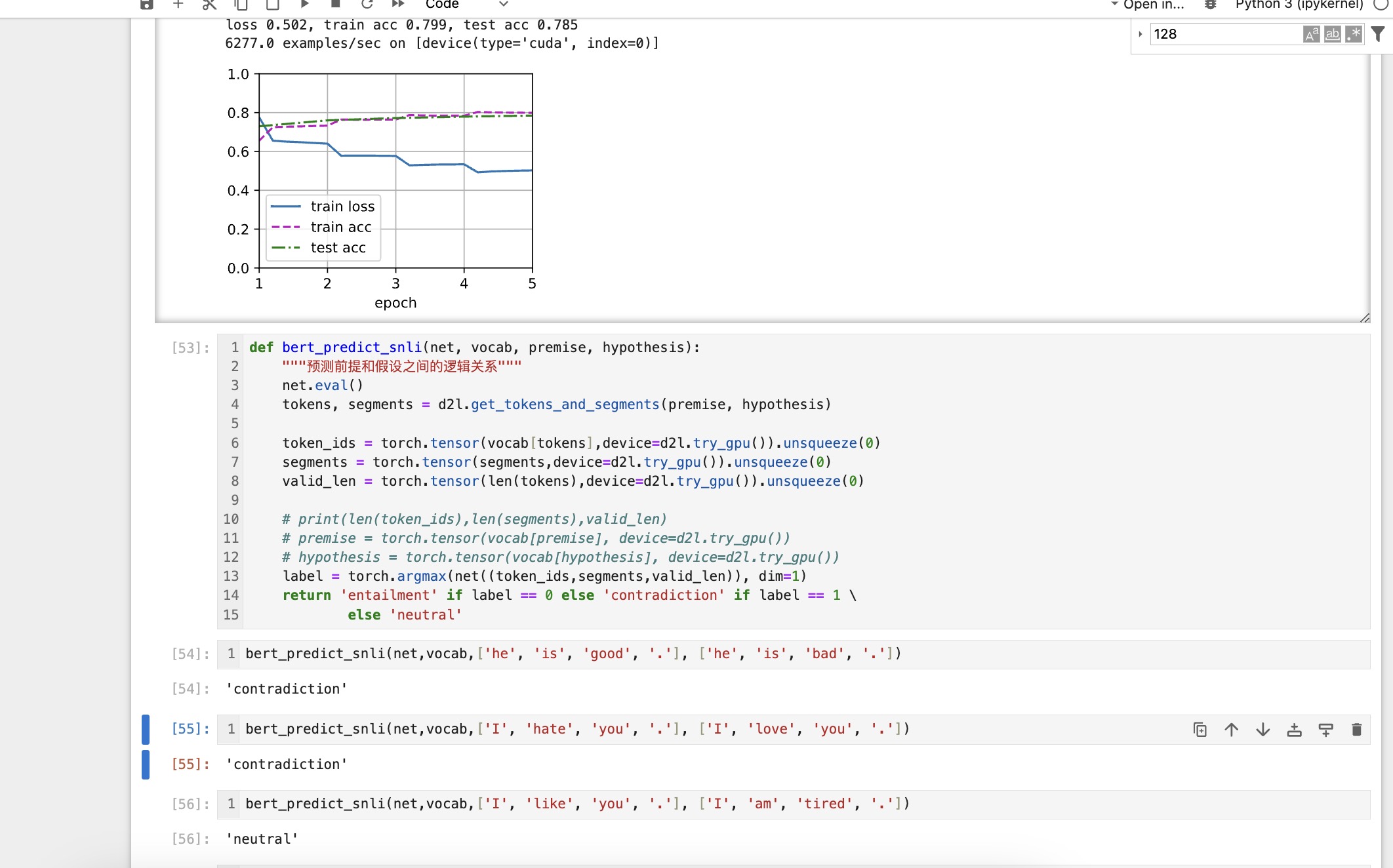
有人试过用这个bert模型实现自然语言推断的输入和输出判断吗
- windows 环境下默认字符集编码是 cp936,d2l 的源码里没有写明用 utf-8 来 open 文件,所以用的是操作系统默认字符集,与SNLI不一致导致打开失败
- 多进程执行的函数,需要从其他模块 import 进来才能使用
请问这个怎么解决呢,在网上没找到可行的解决办法
windows中的多进程几乎不可用,我在linux系统下面可以使用multiprocessing轻松实现多进程,但是同样的代码在windows中不可行,应该是__name__标识符相关的问题,但是依然没有一个优雅的解决方案。
查了一下, PyTorch 在计算梯度时会自动忽略那些没有参与当前计算图的参数,也就是说这些参数的梯度不会被更新。所以一般来说,你可能不需要手动设置 ignore_stale_grad。 这个地方的这个参数是对mxnet这个框架而言的,你可以回去翻一下,mxnet的实现中设置了这个参数
事实上pertained BERT 中涉及 MLM, nsp二个模块没有引入,理论上也不会更新weights。若果必要也可以手动disable:
bert.nsp.output.wieght.requires_grad=False
…
不过我尝试后没有明显变化,包括速度及效果。说明与推测是一样的。
效果看似是正确的。但不是正常的处理方式。。。
撒什么???掌握了多少,提出了多少疑问,有多少brand new ideas?
from multiprocessing.dummy import Pool as ThreadPool
pool = ThreadPool(4) # 使用4个进程
在windows系统中要把pool改成我这样子的线程池,否则会卡死
因为线程池不需要跨进程序列化 self._mp_worker,在 Windows 和 Notebook 中非常稳定