Answer to first question. tensor.detach() creates a tensor that shares the same storage with tensor that does not require grad.
But tensor.clone() will also give you original tensor’s requires_grad attributes. It is basically an exact copy including the computation graph.
Use detach() to remove a tensor from computation graph and use clone to copy the tensor while still keeping the copy as a part of the computation graph it came from.
The second answer about "the meaning of d / a " in 2.5.4.
“a.grad == (d / a)” is true because if you see how d is calculate using f(a). It is basically scaling a by some constant factor k. And if you were to do differentiate such a function say function d=k*a with respect to a then you would get that k. Hence these are true and obviously it won’t hold for b because d is a function of which scales a and not b.
Answer to third question.
As i suggested earlier and you probably did it, you can simply pip install d2l to import torch from d2l.
If you want to import the specific rename imtorch.py just add this to the start of your code before making the import. ->
Q1.
Does it mean that if I ‘clone’ a tensor or a Variable that has requires_grad attribute, then I don’t need to .requires_grad() for the new one?
Use detach() to remove a tensor? However, why can I still judge x.grad() == u.grad? “Remove” doesn’t mean that x will not exist? I think that x and u are just two different names for the same storage.
Can my code about 2.5.2’s Variable add to 2.5.2?
Q2.
I have understand that d is a function of which scales a. But what difference with f(b)?
Because, I think that f(b) = 2 * b.
First, b(formal parameter) =2 * a (argument b).
Then, not enter the loop. (b > 1000)
Then, True for if, return b(formal parameter) which is 2 * b(argument)
Q3.
Thanks. I will try it next time. I have did pip install d2l The specified module could not be found
Did the problem happen because the module doesn’t exist in my sys.path?
import numpy as np
from d2l import torch as d2l
x = np.linspace(- np.pi,np.pi,100)
x = torch.tensor(x, requires_grad=True)
y = torch.sin(x)
for i in range(100):
y[i].backward(retain_graph = True)
d2l.plot(x.detach(),(y.detach(),x.grad),legend = ((‘sin(x)’,“grad w.s.t x”)))
looks dummy since I compute the grad 100 times, is there any better way?
My understanding is that by default the framework will convert the actual output matrix into a vector based on a “gradient vector” that we passed in. The description of this “gradient vector” is
which specifies the gradient of the differentiated function w.r.t self.
What does it mean? Does “gradient of differentiated function” mean “second order gradient”?
My answers to the questions: please point out if I am misunderstood anything
Why is the second derivative much more expensive to compute than the first derivative?
Because instead of following the original computation graph, we need to construct a new one that corresponds to the calculation of first-order gradient?
After running the function for backpropagation, immediately run it again and see what happens.
RuntimeError: Trying to backward through the graph a second time, but the saved intermediate results have already been freed. Specify retain_graph=True when calling backward the first time.
In the control flow example where we calculate the derivative of d with respect to a , what would happen if we changed the variable a to a random vector or matrix. At this point, the result of the calculation f(a) is no longer a scalar. What happens to the result? How do we analyze this?
Directly changing would give the “blah blah … only scalar output” which is what 2.5.2 is talking about. I changed the code to
a = torch.randn(size=(3,), requires_grad=True)
d = f(a)
d.sum().backward()
and a.grad == d / a still gives true. This is because in the function, there is no cross-element operation. So each element of the vector is independent and doesn’t affect other element’s differentiation.
Redesign an example of finding the gradient of the control flow. Run and analyze the result.
SKIP
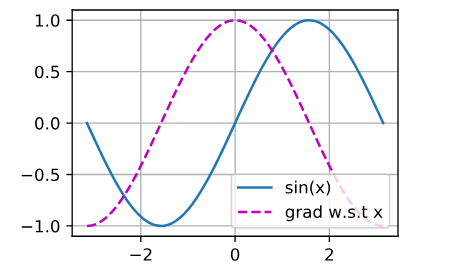
Let $f(x) = \sin(x)$. Plot $f(x)$ and $\frac{df(x)}{dx}$, where the latter is computed without exploiting that $f’(x) = \cos(x)$.
import numpy as np
from d2l import torch as d2l
x = np.linspace(- np.pi,np.pi,100)
x = torch.tensor(x, requires_grad=True)
y = torch.sin(x)
y.sum().backward()
d2l.plot(x.detach(),(y.detach(),x.grad),legend = (('sin(x)',"grad w.s.t x")))
Hi, May I confirm my understanding about the auto differentiation of Python control flow?
I assume, as long as the Python control flow is established by functions and variables from Pytorch, then the auto differentiation is doable. Am I right on this? No other functions should be involved such as sin() from math package(have to use sin() from Pytorch instead if I want auto differentiation).
Exercise 1. The second derivative is much more expensive because, for a function f with n variables, the Hessian Matrix has n² elements while the gradient vector has n elements. In other words, there are n² possible second order derivatives ( ∂²f/∂x1², ∂²f/∂x1∂x2, …) while there are n possible first order derivatives (∂f/∂x1, ∂f/∂x2, …, ∂f/∂xn).
Seems, in the text, by calculating y.backward(torch.ones(len(x))), we contract the Jacobian over the 4 components of y(x). The Jacobian is a 4x4 matrix. I can extract each column via y.backward(torch.tensor([1,0,0,0])), #where i shift the 1 to each of the 4 column slots.
Is this best way to calculate the Jacobian?