应该是写错了。AlexNet 原论文,没有说要加 padding。
1 Like
LeNet 的 SGD 用的默认值 weight_decay=0 ,应该也是没有使用权重衰减吧
3 Likes
我是在回复那个在网络结构里找不到权重衰减的帖子。这是个超参数,可以调的不一定用0,
1 Like
RuntimeError: DataLoader worker (pid(s) 8172) exited unexpectedly
读取数据的时候的报错了,怎么解决呢?
batch_size = 64 lr, num_epochs = 0.05, 10
1 Like
AlexNet练习题
AlexNet对于Fashion-MNIST数据集来说可能太复杂了。设计一个更好的模型,可以直接在 28 * 28 图像上工作。
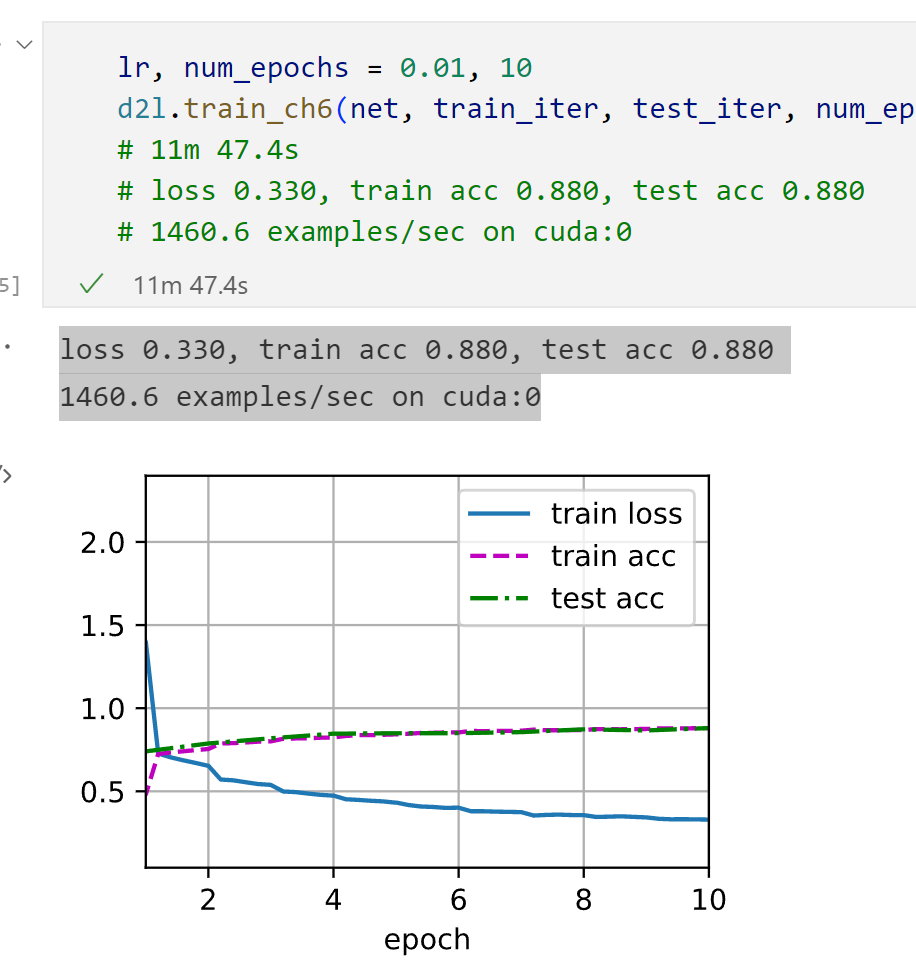
原始AlexNet网络:
loss 0.331, train acc 0.879, test acc 0.880
1457.9 examples/sec on cuda:0
读取28*28图像的网络
net28 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=5, stride=2, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=1),
# nn.Conv2d(64, 96, kernel_size=3, padding=2), nn.ReLU(),
# nn.MaxPool2d(kernel_size=2, stride=1),
nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(128, 96, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
nn.Linear(96 * 5 * 5, 2048), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1024, 10)
)
网络结构:
|Conv2d output shape:| torch.Size([1, 64, 13, 13])|
|ReLU output shape:| torch.Size([1, 64, 13, 13])|
|MaxPool2d output shape:| torch.Size([1, 64, 11, 11])|
|Conv2d output shape:| torch.Size([1, 128, 11, 11])|
|ReLU output shape:| torch.Size([1, 128, 11, 11])|
|Conv2d output shape:| torch.Size([1, 128, 11, 11])|
|ReLU output shape:| torch.Size([1, 128, 11, 11])|
|Conv2d output shape:| torch.Size([1, 96, 11, 11])|
|ReLU output shape:| torch.Size([1, 96, 11, 11])|
|MaxPool2d output shape:| torch.Size([1, 96, 5, 5])|
|Flatten output shape:| torch.Size([1, 2400])|
|Linear output shape:| torch.Size([1, 2048])|
|ReLU output shape:| torch.Size([1, 2048])|
|Dropout output shape:| torch.Size([1, 2048])|
|Linear output shape:| torch.Size([1, 1024])|
|ReLU output shape:| torch.Size([1, 1024])|
|Dropout output shape:| torch.Size([1, 1024])|
|Linear output shape:| torch.Size([1, 10])|
训练结果
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
lr, num_epochs = 0.02, 10
d2l.train_ch6(net28, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
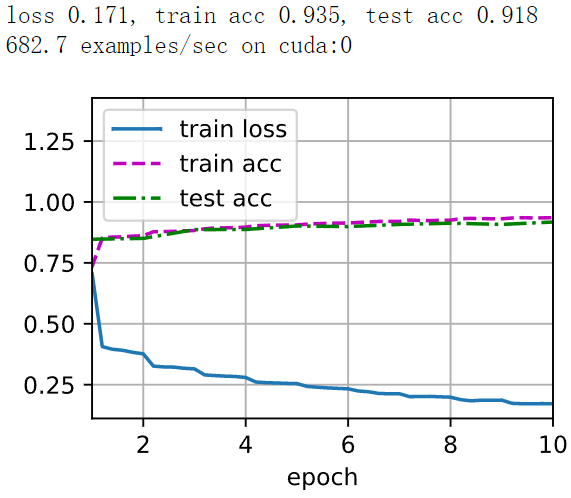
loss 0.356, train acc 0.869, test acc 0.871
12376.4 examples/sec on cuda:0
2 Likes
net = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=5,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=1, padding=1),
nn.Conv2d(96,256, kernel_size=5, padding=2),nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256,384,kernel_size=3, padding=1),nn.ReLU(),
nn.Conv2d(384,384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384,128, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
nn.Linear(4608, 256), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256,64), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(64, 10))
读取数据
batch_size = 64
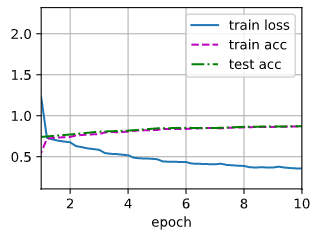
稍改了改,有点提升~
除了batchsize和通道数,其他就都展成一维
我也遇到了这个问题,我把batch_size改成了64就可以了,可能是因为cuda 虚拟环境的共享内存不足,改成更小的batch_size,我的GPU是1050ti,你可以对照自己的GPU改一下
将多维转化成二维,比如将(批量,通道,高度,宽度)转化成(批量,特征)
1 Like
有谁知道第四题的答案吗,主要是哪一部分需要更多的计算以及显存带宽情况
2023/04/01
給在google colab上運行不了的人
運行下面的代碼
然後把d2l.train_ch6改成指向本地的train_ch6
!pip install matplotlib_inline
!pip install matplotlib==3.0
from matplotlib_inline import backend_inline
from IPython import display
def use_svg_display():
"""Use the svg format to display a plot in Jupyter.
Defined in :numref:`sec_calculus`"""
backend_inline.set_matplotlib_formats('png')
def set_figsize(figsize=(3.5, 2.5)):
"""Set the figure size for matplotlib.
Defined in :numref:`sec_calculus`"""
use_svg_display()
d2l.plt.rcParams['figure.figsize'] = figsize
class Animator:
"""For plotting data in animation."""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
"""Defined in :numref:`sec_softmax_scratch`"""
# Incrementally plot multiple lines
if legend is None:
legend = []
use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# Use a lambda function to capture arguments
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# Add multiple data points into the figure
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
def evaluate_accuracy_gpu(net, data_iter, device=None):
"""Compute the accuracy for a model on a dataset using a GPU.
Defined in :numref:`sec_lenet`"""
if isinstance(net, nn.Module):
net.eval() # Set the model to evaluation mode
if not device:
device = next(iter(net.parameters())).device
# No. of correct predictions, no. of predictions
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# Required for BERT Fine-tuning (to be covered later)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), d2l.size(y))
return metric[0] / metric[1]
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""Train a model with a GPU (defined in Chapter 6).
Defined in :numref:`sec_lenet`"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
1 Like
代码上有注释,因为用的Fashion-MNIST数据集,所以改了模型输出
1 Like
电脑一万以下的同学,建议降低一些channel的数目后再训练,不然真的是跑不动。
1 Like
图里的图片展示的是原论文的网络输入,ImageNet三通道的彩色图片(3@224x224),书里的实验网络输入是MNIST,单通道图片(1@28x28)。书里有介绍图片尺寸也是用resize强行从28缩放到224,但是通道数没有变,所以还是1
1 Like
analyze the Computational Performance of AlexNet
torchsummary.summary(net, (1, 224, 224), 128, ‘cpu’)
optimizer, batch_size, lr = sgd, 64, 0.05
epoch 5, loss 0.261, train acc 0.902, test acc 0.903
epoch 6, loss 0.238, train acc 0.911, test acc 0.902
epoch 7, loss 0.219, train acc 0.918, test acc 0.895
epoch 8, loss 0.204, train acc 0.924, test acc 0.912
remove animator,print accuracy directly,test_acc decline at the epoch 6,7
optimizer, batch_size, lr = adam, 256, 0.001
epoch 5, loss 0.232, train acc 0.913, test acc 0.909
epoch 6, loss 0.216, train acc 0.919, test acc 0.911
epoch 7, loss 0.197, train acc 0.926, test acc 0.912
epoch 8, loss 0.186, train acc 0.930, test acc 0.919
epoch 9, loss 0.174, train acc 0.934, test acc 0.916
epoch 10, loss 0.162, train acc 0.939, test acc 0.922
test_acc decline at the epoch 9,regardless of the calculation cost, increasing the epoch can still improve the test acc
1 Like
The input image size should not be 224x224, but 227x227.
This leads to the output shape of the 1st conv layer become:
W = H = ((224 − 11 + 2(0)) / 4) + 1 = 54.25
Which is not a integer, See Zero-padding part in this link for more detials.
But one thing still confusing me:
The output shape of 1st conv layer would be 96x55x55, cuz the input shape is 227x227, which is OK.
But the output of 1st maxpool layer would be 96x27x27 in this case.
Is that correct still using kernel_size=3, stride=2 as param of this maxpool layer?
- 改动:
- 调整了图像尺寸从
224至AlexNet实际输入尺寸的227,修改全连接层尺寸以适配; - 添加了两个
LayerNorm层(其实没道理,CV分类任务应该用BatchNorm); -
d2l.train_ch6默认优化器(SGD),batch_size = 16,lr = 0.5,num_epoch = 20;
-
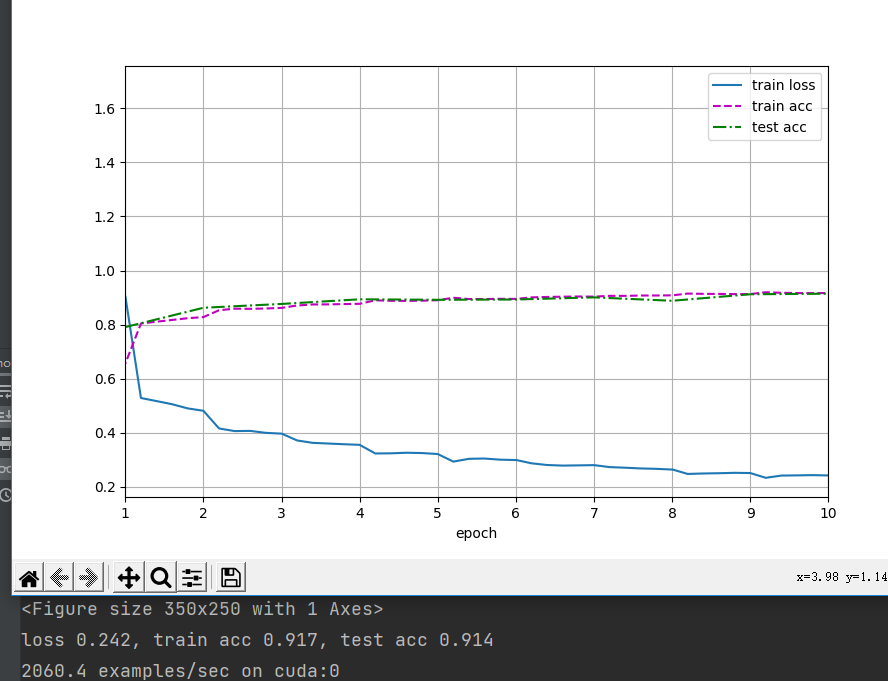
结果:未见明显过拟合现象
loss 0.135, train acc 0.948, test acc 0.921 -
感受:确实玄学
-
网络结构:
nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(start_dim=1, end_dim=-1),
nn.Linear(9216, 4096), nn.LayerNorm(4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.LayerNorm(4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 10)
)