http://zh.d2l.ai/chapter_attention-mechanisms/multihead-attention.html
2 Likes
代码里不同注意力头的 W_q, W_k, W_v 似乎是一样的,注意力机制用的也是同一个,那么每个注意力头产生的输出应该也是一样的,是不是有问题啊?
我也认为有问题。这是单头注意力机制。英文版的讨论里认为这是一个巨大的单头注意力(多个头的参数concat到一起变成一个单头),然后并行计算(相当于多头)。这里的代码实在应该再优化一下。

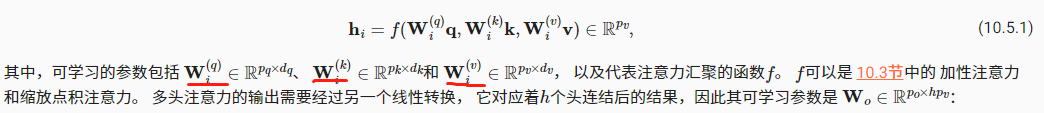
这里的确有点难懂, 这里其实是把所有注意力头里面的参数拼起来, 变成了一个大的全连接层
2 Likes
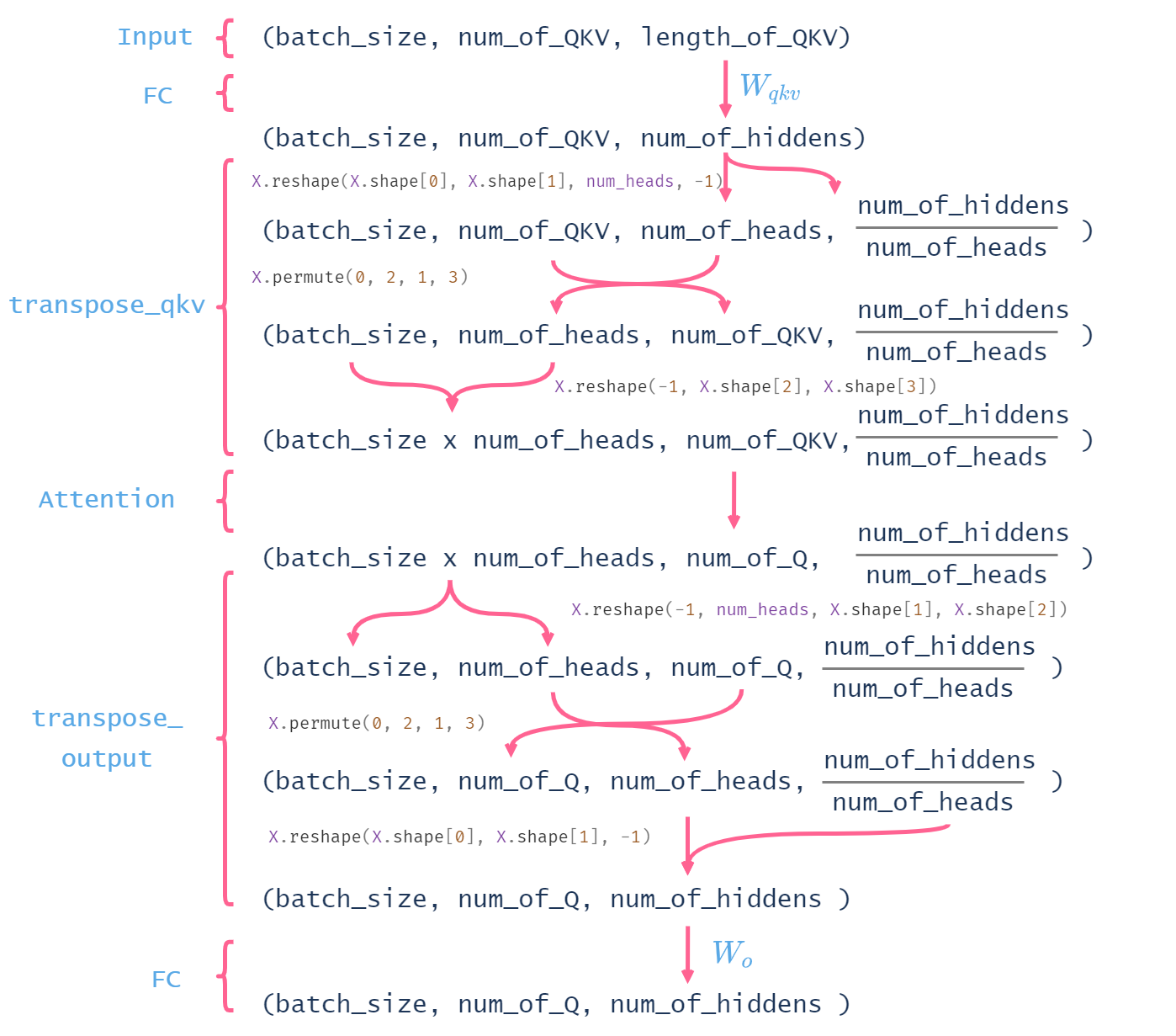
这张图梳理的维度变换过程很清楚,感谢。这节的代码注释里要是有这些维度变换信息就好懂多了。
1 Like
每个注意力头的这三个W都是不一样的,所以公式里的W有下标编号i。只是代码实现里的self.W_xx是把全部注意力头拼接到一起的,如果分开看的话实际上是num_heads个头,每个头的输出维度是num_hiddens/num_heads,拼接到一起就是num_hiddens的维度。
3 Likes
太优秀了!这张图确实恨清楚,配合代码看,一下就理解了
研究了半天,谈谈我的理解:
一开始query的shape是(2,4,100),应该是(2,4,20)复制了5份然后拼在一起的,实际每个batch的query的shape就是(2,4,20);
num_hiddens=100其实也是将5个head的全连接层放到一起初始化了;
transpose_qkv做的事情其实是将拼在一起的query拆开,每个query的shape是变成(4,20),然后将2个5头query共10个query摊开一起算,所以最后送到attention的shape是(10,4,20)
不知道这样理解对不对,最后附上我研究transpose_qkv的草稿:
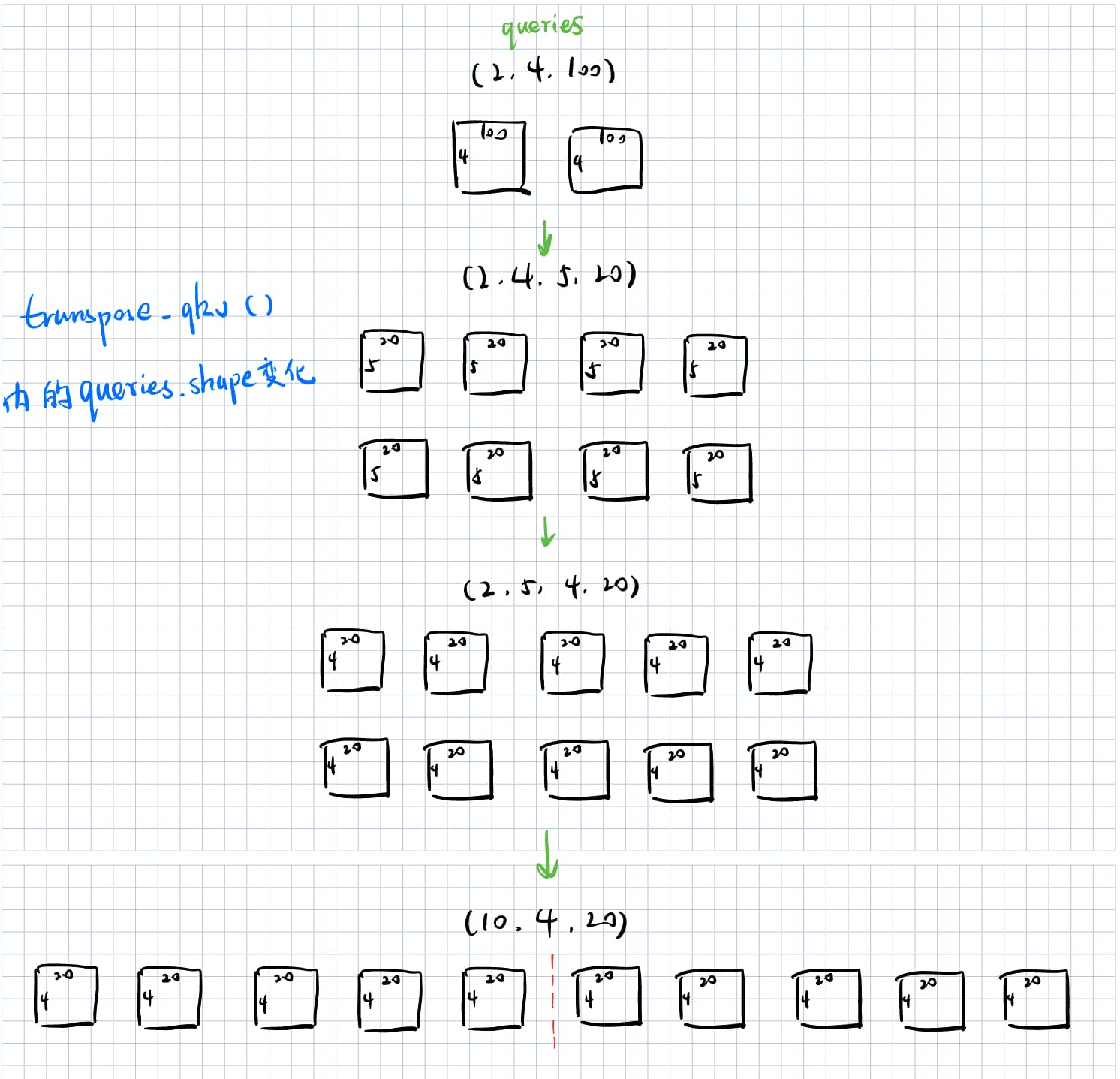
3 Likes
这边多头注意力在transpose_qkv那边做的交换维度的操作主要目的是将计算中可并行的多个head“化作batch_size”和batch_size那个维度放在一起,使输入attention的维度变成(batch_sizehead,num_of_QKV,num_of_hiddens),放入d2l.DotProductAttention(dropout)(缩放点积注意力的实现)中去计算。点积注意力计算过程中是没有参数需要学习,所以可以将多个head需要做的计算当作数量为head的多个batch拆出来和原来的beath拼在一起计算,使得batch数量从原batch_size->batch_sizehead
1 Like

这句话该怎么理解,把queries,keys,values拆成(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)后做点积,最后还原得到(batch_size,查询的个数,num_hiddens)。这样和不拆,直接queries,keys,values(batch_size,查询或者“键-值”对的个数,num_hiddens)做点积,也能得到(batch_size,查询的个数,num_hiddens),这两个结果的区别在哪,“不同的子空间”怎么理解?
请问这里的batch_size 和num_queries的区别是什么 batch_size不应该是代表了一个batch里面查询的数目吗?

![]()
个人感觉想在点积注意力的条件下实现h个并行计算只要满足pq=pk就行了,为何要满足等于其他的呢?设置全连接层的时候只要让n=h*pq就行了呀
赞成你的想法,应该是query_size,估计是写错了
可以结合卷积神经网络里的多通道来理解。拆开后把拆开的部分放入注意力机制,然后通过训练参数W_o,以识别不同的模式,达到多通道的效果。
我也不知道理解得对不对,可以去参考一下沐神讲transformer论文的那个视频~
amazing!!神图啊,感觉图片画的很清楚