http://zh.d2l.ai/chapter_attention-mechanisms/bahdanau-attention.html
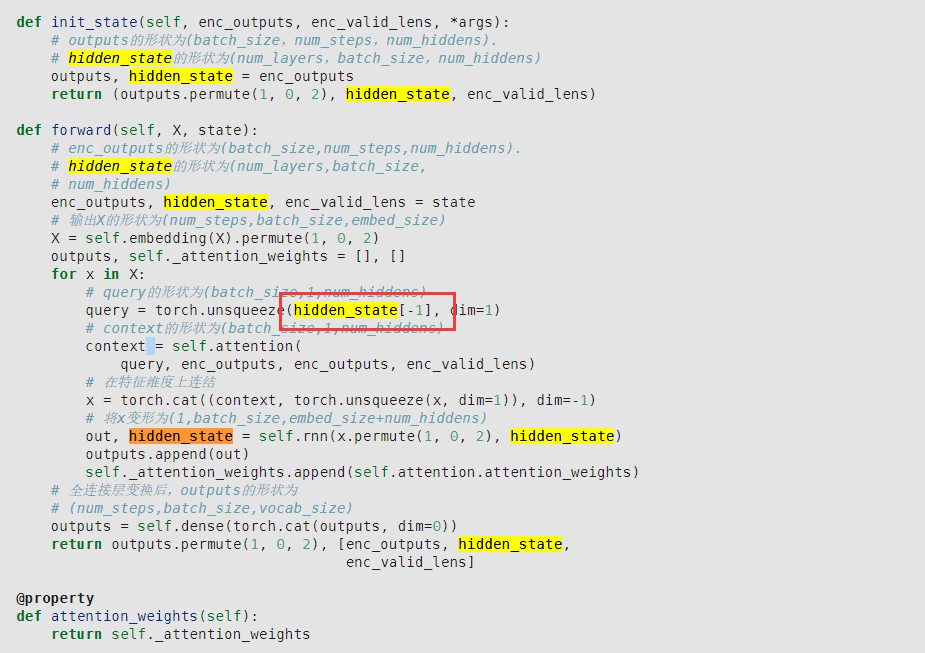
hidden_state 的形状为(num_layers,batch_size,num_hiddens),为什么这里使用的是hidden_state[-1] ,而不是hidden_state
hidden_state大小为(num_layers, batch_size, num_hiddens)。
query大小为 (batch_size, 1, num_hiddens)。
hidden_state[-1]取出了大小为(batch_size, num_hiddens)的矩阵。
query = torch.unsqueeze(hidden_state[-1], dim=1)将hidden_state[-1]大小改为 (batch_size, 1, num_hiddens)然后赋值给query。
2 Likes
Why key_size query_size num_hiddens are all equal to num_hiddens?

2.应该改为“最终“时间步的编码器全层隐状态
1 Like
应该把训练集拆分成训练集,测试集,最后在测试集算下平均BLEU. 我的参数,损失,BLEU如下【有更好的参数设置欢迎加进来】:
embed_size, num_hiddens, num_layers, dropout = 128, 128, 4, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 100, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab, test = d2l.load_data_nmt(batch_size, num_steps, num_examples=10000)
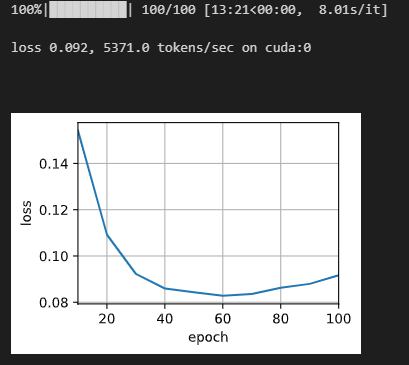
BLEU: 25
拆分数据集程序:
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""Return the iterator and the vocabularies of the translation dataset."""
text = preprocess_nmt(read_data_nmt())
source, target = tokenize_nmt(text, num_examples)
# 改
# source_train, target_train = source, target
# src_vocab = d2l.Vocab(source_train, min_freq=2,
# reserved_tokens=['<pad>', '<bos>', '<eos>'])
# tgt_vocab = d2l.Vocab(target_train, min_freq=2,
# reserved_tokens=['<pad>', '<bos>', '<eos>'])
# src_array, src_valid_len = build_array_nmt(source_train, src_vocab, num_steps) # (n, num_steps), (n, )
# tgt_array, tgt_valid_len = build_array_nmt(target_train, tgt_vocab, num_steps)
# data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
# data_iter = d2l.load_array(data_arrays, batch_size)
# return data_iter, src_vocab, tgt_vocab
# 替换为:
# 拆分训练集,测试集
source_train, source_test, target_train, target_test = train_test_split(source, target, test_size=0.1, random_state=66)
print('len(source_train, source_test)', len(source_train), len(source_test))
# 使用训练集做词表
src_vocab = d2l.Vocab(source_train, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
tgt_vocab = d2l.Vocab(target_train, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
print('len(src_vocab) = ',len(src_vocab))
print('len(tgt_vocab) = ',len(tgt_vocab))
# 训练集
src_array, src_valid_len = build_array_nmt(source_train, src_vocab, num_steps) # (n, num_steps), (n, )
tgt_array, tgt_valid_len = build_array_nmt(target_train, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = d2l.load_array(data_arrays, batch_size)
# 测试集,测试集用训练集的词表
# test_src_array, test_src_valid_len = build_array_nmt(source_test, src_vocab, num_steps)
# test_tgt_array, test_tgt_valid_len = build_array_nmt(target_test, tgt_vocab, num_steps)
# test_src_tgt = (test_src_array, test_src_valid_len, test_tgt_array, test_tgt_valid_len)
source_test = [' '.join(i) for i in source_test]
target_test = [' '.join(i) for i in target_test]
test = (source_test, target_test)
return data_iter, src_vocab, tgt_vocab, testHow to use LSTM Bahdanau decoder?
Isn’t just replace nn.GRU with nn.LSTM?
不能,直接替换会报错。
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state) #报错
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
output, state = decoder(X, state) #报错
RuntimeError: For batched 3-D input, hx and cx should also be 3-D but got (2-D, 2-D) tensors
我用LSTM直接替换了GRU,然后报错了,不知道怎么改。
self.rnn = nn.LSTM(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
# self.rnn = nn.GRU(
# embed_size + num_hiddens, num_hiddens, num_layers,
# dropout=dropout)
self.rnn = nn.LSTM(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
print(self.rnn)
#更换RNN为LSTM
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
你只改了Decoder的RNN,不要忘了LSTM在输入的时候还多了一个长期记忆C。我同时改了Encoder和Decoder(或者不改Encoder,而在初始化Decoder中的记忆C的时候指定C为0?我没试过),在训练时,每一个epoch中,LSTM的训练速度比GRU更快,但loss损失收敛效果不如GRU好,不知道为什么
把加性注意力改成缩放点积注意力之后,训练速度似乎有提升:

调整一下hidden_state的形状就行了。nn.GRU输入和返回值只有隐状态h_0,nn.LSTM的输入和返回值包含隐状态h_0和记忆状态c_0。 这里直接将GRU改为LSTM会报错是因为hidden_state是一个(2,batch_size,num_hiddens)的张量,在输入LSTM的时候,被拆成了两个大小为(batch_size,num_hiddens)的张量,就是错误信息中的(2-D, 2-D) tensors。
下面的代码调整了一下hidden_state的形状,为了方便对比,修改的内容被包括在if-else语句中了。
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
if isinstance(self.rnn,nn.GRU):
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
else:
return (outputs.permute(1, 0, 2), (hidden_state,hidden_state), enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
if isinstance(self.rnn,nn.GRU):
query = torch.unsqueeze(hidden_state[-1], dim=1)
else:
query=torch.unsqueeze(hidden_state[0][-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
1 Like
我被坑了,看了很久才发现编码器引用了d2l包里的,用ctrl+f没找到就没改。
把d2l包里的编码器复制过来之后,把GRU也改成LSTM就直接能跑了。
从d2l里复制过来的s2s编码器:
class Seq2SeqEncoder(d2l.Encoder):
"""The RNN encoder for sequence to sequence learning.
Defined in :numref:`sec_seq2seq`"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# Embedding layer
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
# The output `X` shape: (`batch_size`, `num_steps`, `embed_size`)
X = self.embedding(X)
# In RNN models, the first axis corresponds to time steps
X = X.permute(1, 0, 2)
# When state is not mentioned, it defaults to zeros
output, state = self.rnn(X)
# `output` shape: (`num_steps`, `batch_size`, `num_hiddens`)
# `state` shape: (`num_layers`, `batch_size`, `num_hiddens`)
return output, state
其他两处需要修改的地方
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
#num_layers=2)
# encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
# num_layers=2)
#修改前
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.eval()
X = torch.zeros((4,7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder =Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
# encoder = d2l.Seq2SeqEncoder(
# len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
# 修改前
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
谢谢指点,原代码引用d2l的包,用crtl+f没找到,被坑了一下。
为什么这里使用的注意力的键和值是编码器的输出而不是每一时间步的隐状态呢?还是说最终层隐状态是输出?
确实应该有所提升,但老师说加性注意力有参数可以学习,所以比较好 ![]()
因为是最后一个隐藏层作为初始化解码器的state
他(编码器)的输出其实就是隐状态,第9章我记得说过,rnn没有全连接层那么输出的其实是h。个人理解,有误请指正
但是pytorch里的GRU输出有两个啊 一个是output 特征形状的输出,另一个是h,这个h不就是隐状态么。书中说的是把编码器的所有时间步的最终层隐状态,作为key、values。但代码里把output作为key和values放进注意力层了。
output是每个step的最终层的输出,和注意力远离没问题啊(没有说隐藏层layer个数为1),h是最后一个时间步所有隐藏的state