我的也是,变快了一点点,但是损失上变化不大,GRU换成LSTM之后变化也不大

我的方法是,除了改rnn算法为LSTM,再加上改Seq2SeqAttentionDecoder里forward的每一步的query = torch.unsqueeze(hidden_state[-1], dim=1) 为query=torch.unsqueeze(hidden_state[0][-1], dim=1),其他不变,好像也行,但不太清楚为啥,有人可以解释一下吗。
调用train_seq2seq,出现Y_hat, _ = net(X, dec_input, X_valid_len)
ValueError: too many values to unpack (expected 2)
这个要怎么解呢?
因为LSTM的输入是X和(H_t-1, C_t-1),输出是Out和(H_t, C_t),其中H_t表示t时刻的隐状态,C_t表示t时刻的细胞状态,那么hidden_state[0][-1]其实就是H_t的最后一个,也就是t时刻最后一层的隐状态,还是比较符合这本书的表达的。
是的,代码里是用最终时间步,我还理解了好久说怎么和表述的不一样
缩放点积注意力会训练得更快-----------
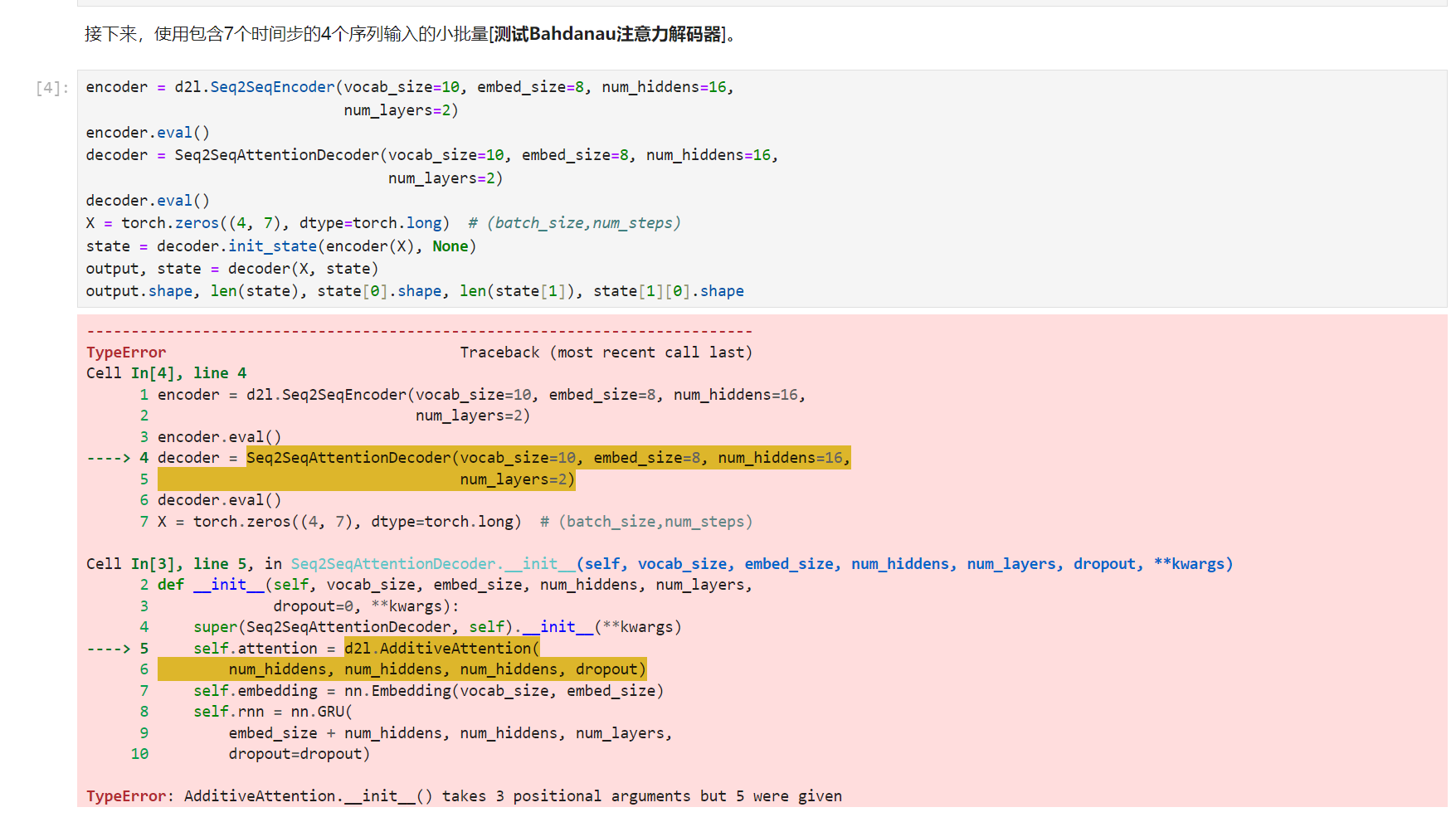
这一节的程序在我电脑上跑不通。。。
按照报错删掉两个num_hiddens倒是可以运行了,但会出现warning:Lazy modules are a new feature under heavy development。不知道咋回事。

尽量使用按照课本写的代码来运行吧,d2l库跟书的中文版上的代码不太一致
for we have used the last layer’s hidden state at last time step which has the shape (num_layers, batch_size,num_hiddens) as the query; and for the same reason with keys, values, which has the feature dimension of num_hiddens
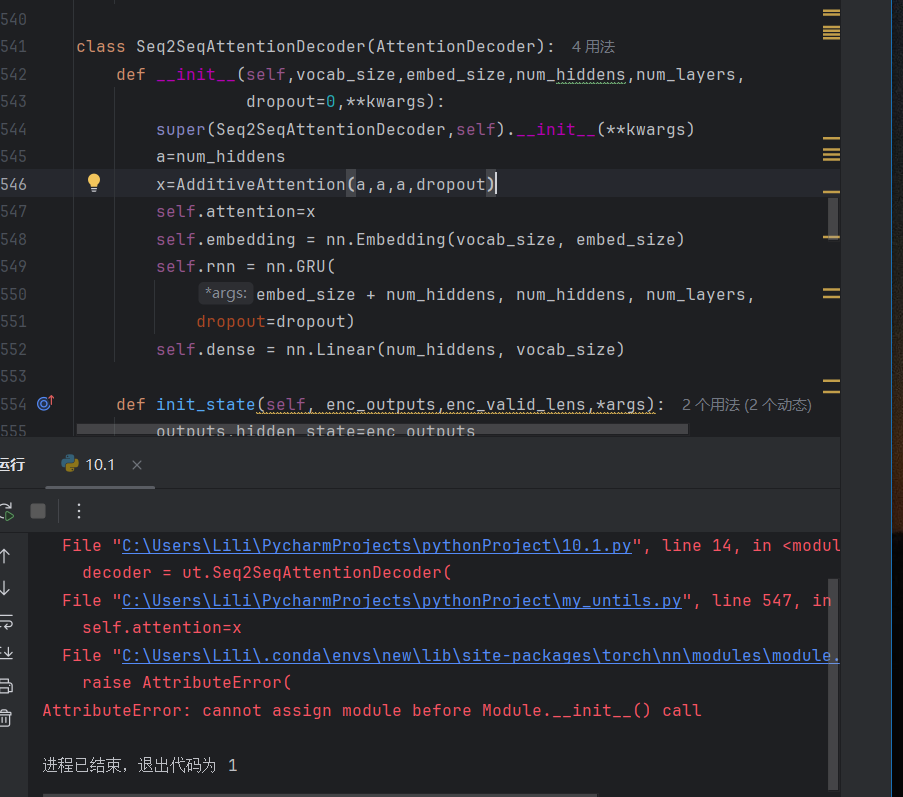
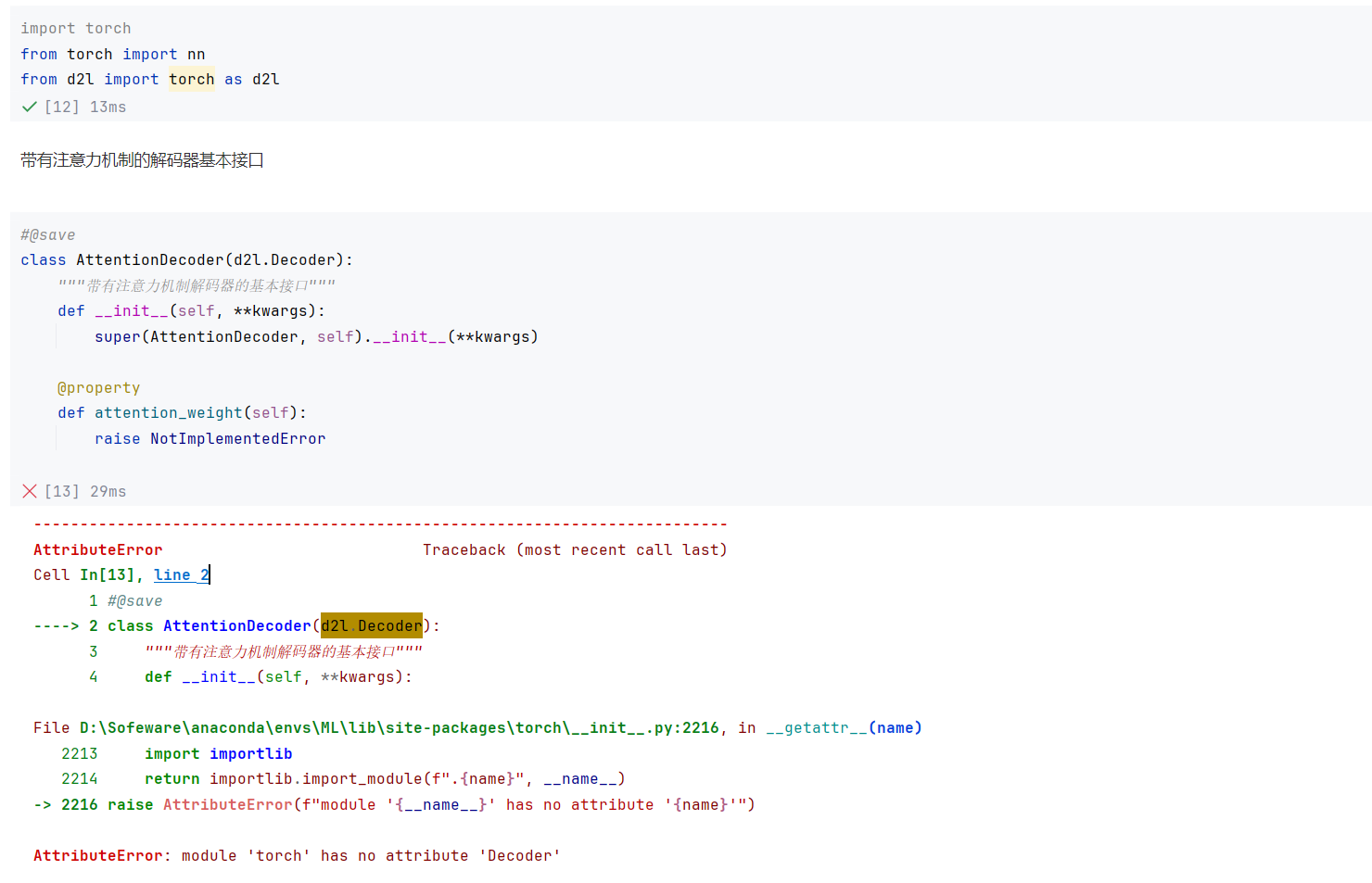
原因是一个值被赋值给多个变量,把d2l包里面的“,_”删除即可

类Seq2SeqAttentionDecoder的forward方法里面,enc_valid_lens应该是指示每个batch里多少个时间步是有效的,但是对X做了permute转置之后,怎么还能用enc_valid_lens给单个时间步里X的批次做mask啊,兄弟们我人晕了,想考公了 ![]()
![]()
破案了,实际上mask掉的是key-value pair,就是把encoder从pad词元学习到的信息mask掉。又不太想考公了,兄弟们。 ![]()
![]()
![]()

output的shape是torch.Size([NumSteps, BatchSize, NumHiddens]),也就是说output本身才是表示小批量内每一组数据在每个时间步最后的隐状态
而hidden_state的shape是torch.Size([NumLayers, BatchSize, NumHiddens]),表示每小批量内对于每一组数据在每一层最后的隐状态
确实有点绕口 ![]()