https://zh.d2l.ai/chapter_recurrent-neural-networks/language-models-and-dataset.html
“我想吃奶奶” 其实也没有那么令人不安,你们觉得呢? 
6 Likes
stop driving the car, please.
8 Likes
def seq_data_iter_random(corpus, batch_size, num_steps):
减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
请问这里减去一该如何解释,为什么说考虑标签就要减去1呢
这一节的seq_data_iter_sequrntial函数中offset=random.randint(0, num_steps),offset应该等于random.randint(0, num_steps-1),要不然开始index随机取到num_steps的时候,会缺少最前面的那个子序列。如有错误,请更正我谢谢~
2 Likes
因为这里的标签,是移位了一个词元的原始序列。如果不减去这个1,就有可能使得原始序列中的最后一个元素被列进样本中而没有与之对应的标签(数组越界了)。
2 Likes
两种方法的偏移量不一致,请问可以任意取偏移量吗?


1 Like
第二个应该改成num_steps-1, 否则当 offset= num_steps时,会缺失最后一个batch
1 Like
公式总是显示不出来,有人知道怎么解决吗?
觉得是无关痛痒的,此处只是开头砍掉前缀而已。最终控制长度的是下行取整
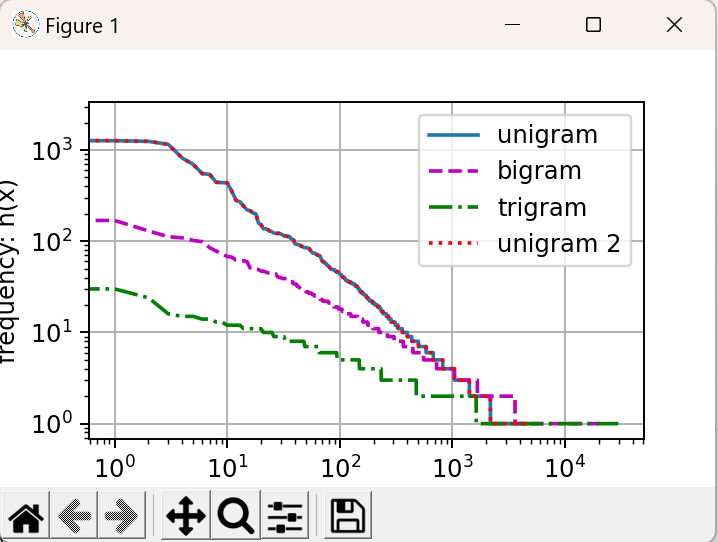
这一节觉得有点乱,开始说laplace smoothing可以解决尾部低频词问题,接着zipf’s law又推翻了前者。。
3 Likes
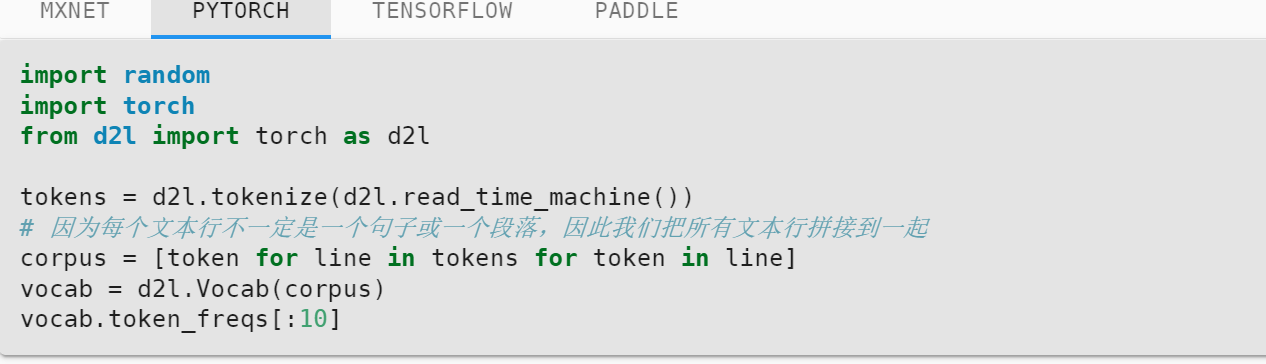
不用吧,这个直接取出来就是一个装着频率值的数组
Preformatted text当设置为二元语法或更多时,每个词元是一个元组或者"UNK",进行排序的时候,如果报错TypeError: ‘<’ not supported between instances of ‘str’ and ‘tuple’
可以在sorded()函数中添加参数key = lamda t:t[0]
参考链接:python - TypeError: '<' not supported between instances of 'tuple' and 'str' - Stack Overflow
具体修改d2l.torch.py 655行:self.idx_to_token = list(sorted(set(['<unk>'] + reserved_tokens + [ token for token, freq in self.token_freqs if freq >= min_freq]),key=lambda t: t[0]))
这一节用了好多这个术语:“时间步”。个人感到非常困惑的一个术语,发现用:“序列长度”来替代这个“时间步”更容易理解。其一,这里处理的是语言序列与股票预测的不一样,前后并没时间因果关系,而有空间的前后关系。其二,这里的序列因为没时间依赖,完全可以GPU空间并行,在并行上也容易理解些。我自己发生了专业术语上的混淆,不知其他朋友怎么理解的,或者坚持用“时间步”还有其它深意?
2 Likes
语言序列和股票预测其实我感觉是差不多的,他也是时间关系。因为对于一段或者一句话来说,前面的单词可能会影响到后续的单词,你可以认为之前的单词就是时间t-1,t-2,…,1的序列,而我们生成的就是时间t上的单词。不过这只是我的个人理解,他的时间和现实的时间可能还是有差异的,他应该说的只是一个序列的先后关系
en。另外有个疑问是:8.3.6中长度是4的序列可以通过1~4元语法建模,但具体到bigram_tokens例子时序列长度为2个tokens时就说是二元语法,感觉也可以说是一元语法吧,为什么肯定是二元呢?如果是这样8.3.6中的应该说是四元语法呀。。。
原文中的token_freqs加了@property注解
所以可以直接当做一个变量来使用
@property
def token_freqs(self): # Index for the unknown token
return self._token_freqs