Q1
需要储存100,000个词频与100,000-4+1 = 99,997个相邻词频率
Q2
将一个句子设为一个corpus
Q3
可以通过神经网络回归进行拟合
Q4
使用随机序列长度进行读取,或对长序列进行分段,并在分段中进行随机采样
需要储存100,000个词频与100,000-4+1 = 99,997个相邻词频率
将一个句子设为一个corpus
可以通过神经网络回归进行拟合
使用随机序列长度进行读取,或对长序列进行分段,并在分段中进行随机采样
这里的中文机翻极了,我前面章节和知识都能看懂,这里几乎无法理解
Preformatted text 当设置为二元语法或更多时,每个词元是一个元组或者"UNK",进行排序的时候,如果报错TypeError: ‘<’ not supported between instances of ‘str’ and ‘tuple’
将torch.py对应行改为self.idx_to_token = list(sorted(set(['<unk>'] + reserved_tokens + [ token for token, freq in self.token_freqs if freq >= min_freq]), key=lambda x:' '.join(map(str, x))))即可,这样也保持了字典序排列
可以修改函数d2l.plot,自己定义一个,给它多设置几种线条样式,这样就可以多画几条了。
随机抽样和顺序分区得到的结果有什么不同?顺序分区得到的结果哪里体现了相邻呢?
假设我们有一个序列[1, 2, 3, 4, 5, 6] ,我们想要生成长度为2的子序列。如果我们不减去1,那么我们可以生成3个子序列:[1, 2] ,[3, 4] 和[5, 6] 。但是,对于最后一个子序列[5, 6] ,我们没有额外的元素作为预测的目标。因此,我们需要将原始序列的长度减去1,这样我们就只会生成2个子序列:[1, 2] 和[3, 4] ,每个子序列都有一个额外的元素作为预测的目标,分别是3和5
我这一块如果不做出更改就会显示比较错误(将str和tuple进行比较)
以下是更改之后的能正常运行的
bigram_tokens = ['{}_{}'.format(pair[0], pair[1]) for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
下面的trigram同理,得改一下格式才能运行
trigram_tokens = ['{}_{}_{}'.format(triple[0], triple[1], triple[2]) for triple in zip(
corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
这是AI给出的吧,我觉得还是把上一节notebook中Vocab类的代码直接覆盖掉d2l包的torch版本文件中相应的定义比较好。
注释random.shuffle即为顺序采样
为什么d2l里面没有read_time_machine函数
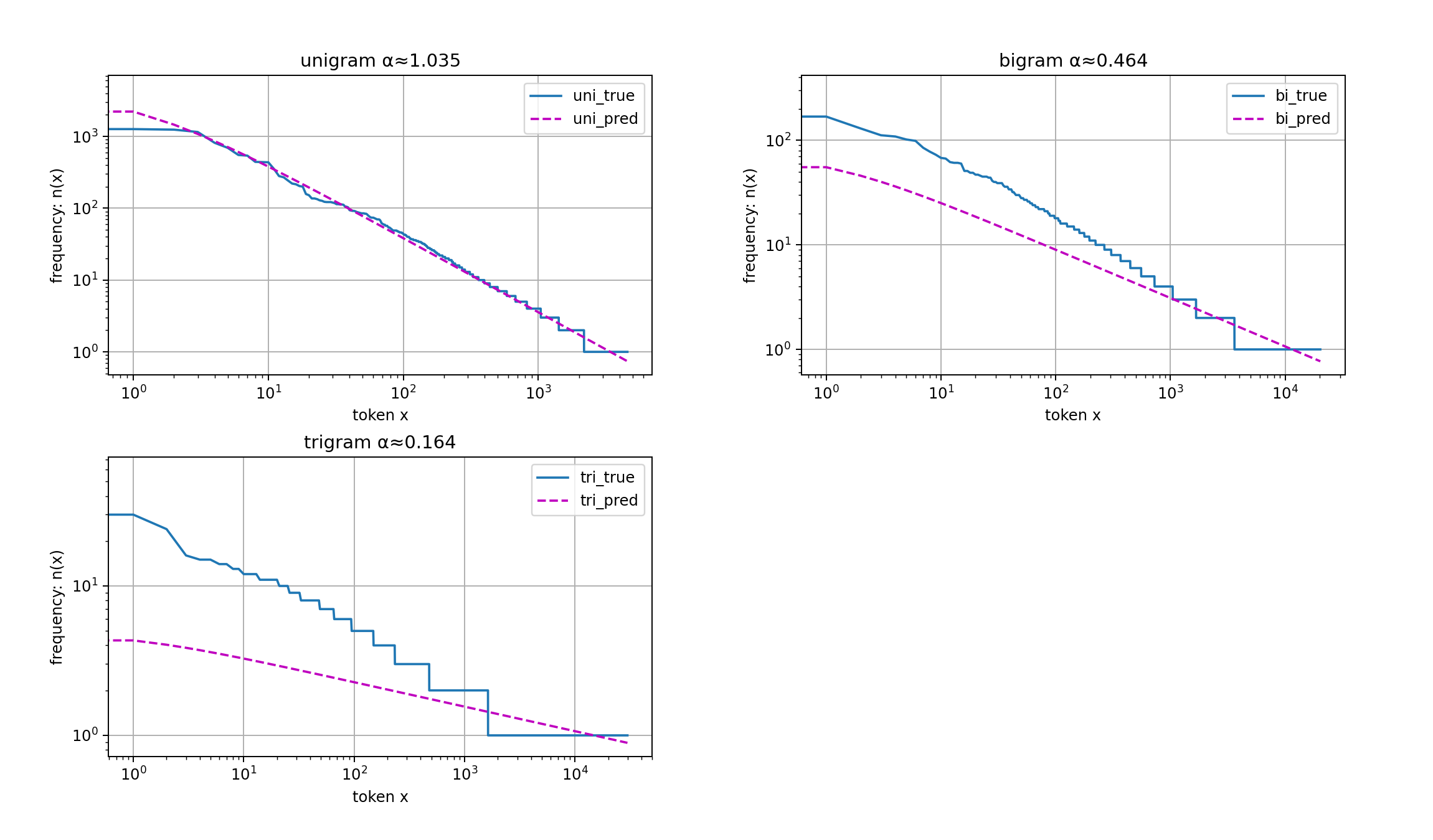
因为zipf’s law表明尾部的长度太长了,拉普拉斯平滑将未见的 n-元组概率过高地抬升,同时降低了常见 n-元组的概率,从而失去了对数据中真正分布的敏感性。
make sense, thank you
我也觉得确实很难理解,语言表达上质量不太好。
不过,刚刚,我整理了一个我觉得更加通顺自然、代码规范、符合最佳实践的笔记:
在100,000词的语料库中,4-gram模型需要存储多少词频和相邻词频?
词频(Unigram)
100,000个相邻词频(N-gram)
几百万(理论最大10^10)几千万(理论最大10^15)几亿(理论最大10^20)如何对dialogue进行建模
我没有任何的头绪
汉尼拔:今晚你想吃心脏还是吃肺 ![]()
![]()
![]()
![]()
![]()
为什么torch库里面存不上read_time_machine()函数啊
对于一段或者一句话来说,前面的单词可能会影响到后续的单词,你可以认为之前的单词就是时间t-1,t-2,…,1的序列,而我们生成的就是时间t上的单词。这样理解对吗?
在上一节的 text-preprocessing里面,把这个函数加到d2l的torch里面
不用的,Vocal进行定义时用@property方法了,可以不加括号,直接用
我理解不需要
seq_data_iter_random内需要num_steps-1是因为后面切片是对索引, 不-1会导致少一个样本;seq_data_iter_sequential是直接对数据切片不会存在这样的情况