https://zh.d2l.ai/chapter_recurrent-neural-networks/text-preprocessing.html
运行8.2.1时报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xc9 in position 1440: invalid continuation byte
已经解决了, 是由于学校内的校园网络问题网络问题
2 Likes
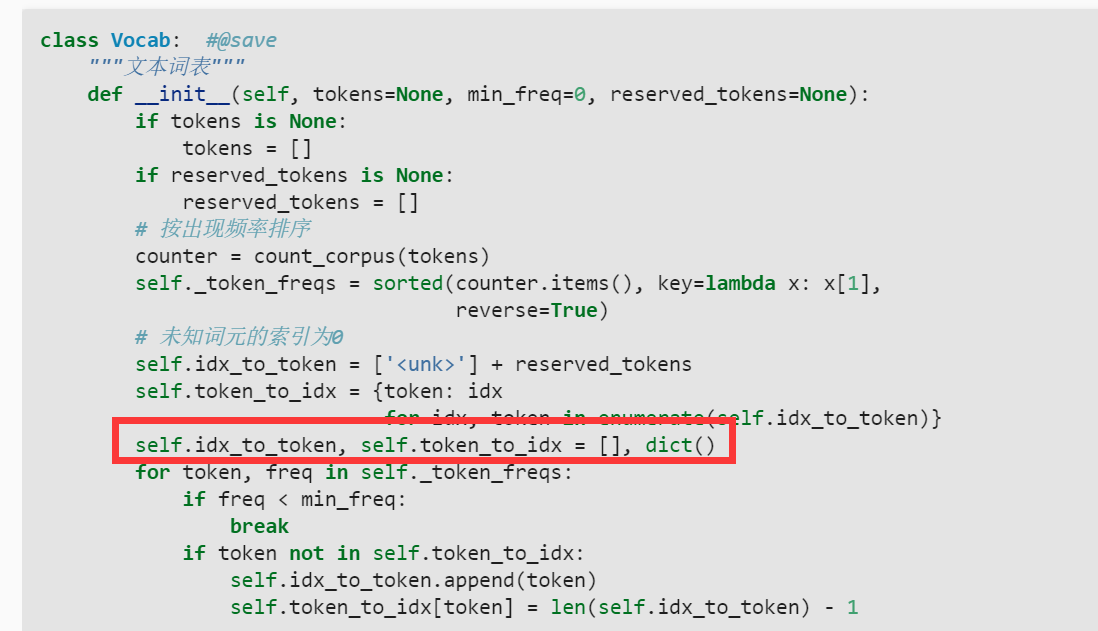
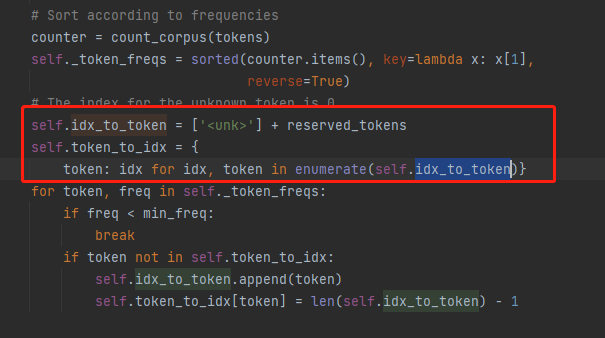
这里确实重复定义了,这句话是多余的。加这句话 unk 实际上没有存进去,改的方法最简单的是直接删除这句话,工具包的源代码就没有这条语句(如下图)。另一种会麻烦很多,就是用别的变量来记录和操作(李沐大神课堂里放的代码用的是这种方法)
1 Like

前面有排序,词频从大到小排序,也就是当出现第一个词频小于min_freq时,后面的全部会小于min_freq
3 Likes
个人认为比较优美的代码
self.idx_to_token = uniq_tokens
self.token_to_idx = dict(zip(uniq_tokens, range(len(uniq_tokens))))
2 Likes
print(‘索引:’, vocab[tokens[i]]) 请问这里vocab()在调用什么函数,该怎么理解这个命令?多谢
啊,刚好是最近的呀~ 我刚刚也在想这个问题,我记得之前有人在学CNN的时候问 net(X) 是调用的哪个函数,沐神当时说 net(X) 等价于 net.__call__(X),最后实际上调用的是net.forward(X),我觉得应该是是在父类nn.Module中定义了__call__()然后在里面调用了forward(),所以这三个的效果都一样
然后在这里我发现 vocab[tokens[i]] 是等价于 __getitem__(tokens[i]) 的,试了一下二者效果一样,不过具体我也不清楚,可能是默认调用__getitem__() ?
我就是基础太差了qwq,一起加油~
3 Likes
因为已经排好序了,所以后面的频率都小于min_freq了,因此直接break
2 Likes
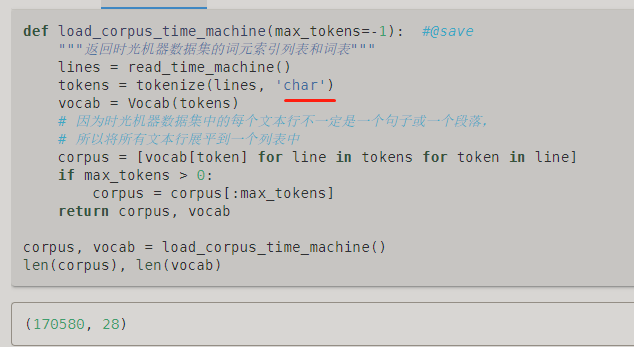
前面例子中用的word, 可以理解,但是这里为什么突然换成char???
8.3节也是这样,举例子的时候和后续正式代码的时候都不一致。
很奇怪的是,举例的时候用word,但是后续整合的时候就变了,不仔细看都不知道,好几篇文章都是这样的清奇  。。。
。。。
1 Like
啊哈哈哈谢谢你!明白了,刚好昨天处理训练数据的时候用了pytorch里面的Dataset类和Dataloader类,Dataset类就要求你继承的时候必须重写__getitem__()方法,然后根据id返回值,跟这里一样滴!
len(tokens) == 0 起到一个什么作用?
2 Likes
可能是为了全面考虑 dim 吧,这样就比较完整了
小白求文另外三种常用的词元 化文本的方法是什么呀 ![]()
你好,我在服务器中有这个问题,在电脑本地没有这个问题?请问是什么原因?
请问同学你是怎么解决的?在线等。。。。。。。