二维的tokens如果没有元素的话tokens[0]会报错,需要单独处理
1 Like
Q1:最常用的三种是 BPE(Byte-Pair Encoding),WordPiece和SentencePiece
Q2:
第一个上面是默认min_freq=0,下面是设置min_freq=5。简单来说就是通过设置min_freq参数来过滤低频词(将低频词的索引设置为0),获得高频词.
通过将load_corpus_time_machine中参数设置为默认的’word’可以看到,min_freq对语料库的影响
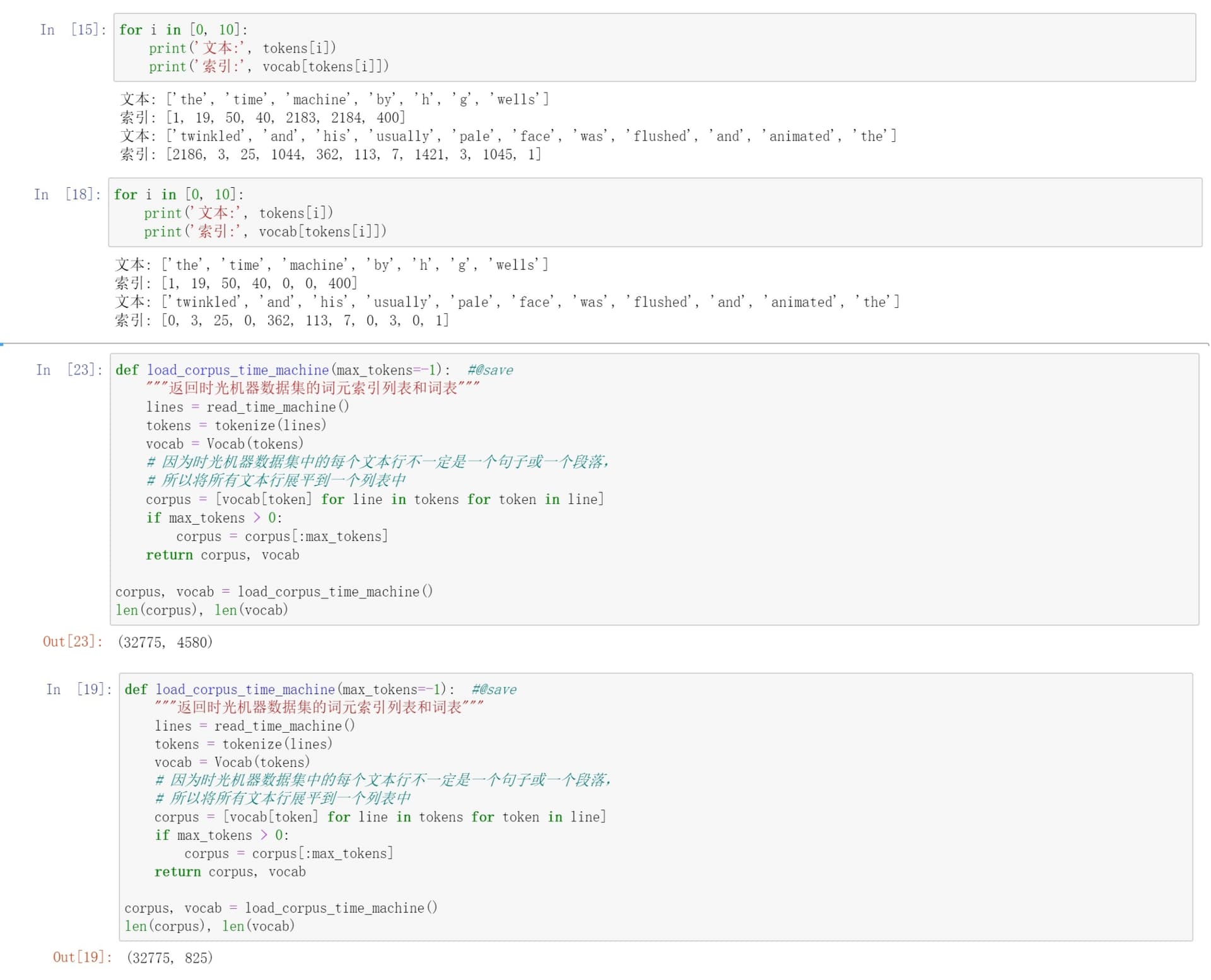
2 Likes
想问一下这个函数该如何运用:
def to_tokens(self, indices)
这是Python语法相关的,详见Python官网文档。__getitem__是一个魔术方法,在使用方括号索引时Python解释器会直接调用此方法,重写此方法可实现类对象的键值对索引机制。

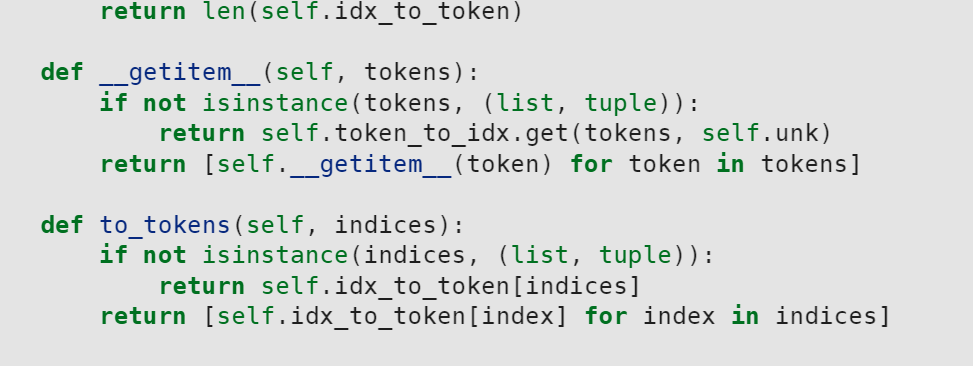
这里没有漏,因为unk函数上面有个@property注解
1 Like
相当于打印vocab类的一个对象,也就是会调用__getitem__这个函数,文中代码进行了函数重载,将__getitem__函数定义为返回对应token的索引

应该是
对象.to_tokens(indices)
吧
在深度学习中,常用的词元化(tokenization)方法包括以下几种:
- 空格分词(Whitespace Tokenization):将文本按照空格进行分割,将每个分割后的词作为一个词元。例如,"Hello world!"会被分割为[“Hello”, “world!”]。
- 分词器(Tokenizer):使用专门的分词器工具,如NLTK(Natural Language Toolkit)或spaCy,在文本中识别和分割单词。这些分词器可以处理更复杂的分割规则,例如处理标点符号、缩写词等。
- n-gram分词:将文本切分为连续的n个词的组合,这些组合称为n-gram。常见的是二元(bigram)和三元(trigram)分词。例如,"Hello world!"的bigram分词为[“Hello world”, “world!”]。
- 字符级别分词(Character-level Tokenization):将文本按照字符进行分割,将每个字符作为一个词元。这种方法对于处理字符级别的任务(如拼写检查、机器翻译等)很有用。
- 子词(Subword)分词:将单词切分为更小的单元,如词根、前缀或后缀等。这种方法可以处理未登录词(out-of-vocabulary)问题,并且对于具有复杂形态的语言(如德语、芬兰语)也很有效。常见的子词分词算法有Byte-Pair Encoding(BPE)和SentencePiece。
这些方法的选择取决于特定的任务和语言,不同的词元化方法可能适用于不同的场景。在使用深度学习进行文本处理时,需要根据具体情况选择合适的词元化方法。
2 Likes
关于第一个问题有一个不理解的地方,就是我们现在进行词元化的文本序列都是英文序列,他一个单词就是一个意思。但是如果我们的文本序列是中文那又应该怎么分词呢?
因为英文的一个单词或一个短语可能对应中文一个字、两个字、三个字都不一定。而且中文是没有空格分割的,所以有什么更好的分词方式呢?
查阅了一下,貌似有个叫作jieba分词的,可以按照词性来进行分词
这样做兼顾了通用性吧,如果是英文这样做,别说语义,连词法都保障不了

这个我一开始也有疑惑,后来去看了一下__grtitem__()的作用,就清楚了,你可以去搜一下__grtitem__()的相关内容
在unk方法的定义上加了property注解的,就会把它变成一个属性;这和java使用注解的方式相反,java是在属性上加property注解,会自动生成这个属性的setter、getter方法
并不会报错,你不信自己试试,我单独把拿出来试了下,反正没报错
请问下载一开始的文本的时候报错PermissionError: [WinError 5] 拒绝访问。: '…/data’怎么解决呀
我把min_freq调成50对len(vocab)和len(corpus)也没啥影响 ![]() ,但是索引是变了的
,但是索引是变了的