http://zh.d2l.ai/chapter_convolutional-modern/googlenet.html
2 Likes
结合GoogleNet论文实现
论文地址: Going Deeper with Convolutions
定义Inception模块
class Inception(nn.Module):
def __init__(self,in_channels,c1,c2,c3,c4):
super(Inception,self).__init__()
self.conv1 = nn.Conv2d(in_channels,c1,kernel_size = 1)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels,c2[0],kernel_size = 1),nn.ReLU(),
nn.Conv2d(c2[0],c2[1],kernel_size=3,padding=1),nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels,c3[0],kernel_size=1),nn.ReLU(),
nn.Conv2d(c3[0],c3[1],kernel_size=5, padding=2),nn.ReLU()
)
self.conv4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channels,c4,kernel_size = 1),nn.ReLU(),
)
def forward(self,X):
return torch.cat(
(
self.conv1(X),
self.conv2(X),
self.conv3(X),
self.conv4(X),
),
dim = 1
)
实现GoogleNet模型
class GoogleNet(nn.Module):
def __init__(self,in_channels,classes):
super(GoogleNet,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels,out_channels=64,kernel_size=7,stride=2,padding=3),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=1),nn.ReLU(),
nn.Conv2d(in_channels=64,out_channels=192,kernel_size=3,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
Inception(192,c1=64,c2=[96,128],c3=[16,32],c4=32),
Inception(256,c1=128,c2=[128,192],c3=[32,96],c4=64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
Inception(480,c1=192,c2=[96,208],c3=[16,48],c4=64),
Inception(512,c1=160,c2=[112,224],c3=[24,64],c4=64),
Inception(512,c1=128,c2=[128,256],c3=[24,64],c4=64),
Inception(512,c1=112,c2=[144,288],c3=[32,64],c4=64),
Inception(528,c1=256,c2=[160,320],c3=[32,128],c4=128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
Inception(832,c1=256,c2=[160,320],c3=[32,128],c4=128),
Inception(832,c1=384,c2=[192,384],c3=[48,128],c4=128),
nn.AvgPool2d(kernel_size=7,stride=1),
nn.Dropout(p=0.4),
nn.Flatten(),
nn.Linear(1024,classes),
nn.Softmax(dim=1)
)
def forward(self,X:torch.tensor):
for layer in self.model:
X = layer(X)
print(layer.__class__.__name__,'output shape:',X.shape)
模型测试
X = torch.randn(size=(1,3,224,224))
net = GoogleNet(3,1000)
net(X)
测试结果
Conv2d output shape: torch.Size([1, 64, 112, 112])
ReLU output shape: torch.Size([1, 64, 112, 112])
MaxPool2d output shape: torch.Size([1, 64, 55, 55])
Conv2d output shape: torch.Size([1, 64, 55, 55])
ReLU output shape: torch.Size([1, 64, 55, 55])
Conv2d output shape: torch.Size([1, 192, 55, 55])
ReLU output shape: torch.Size([1, 192, 55, 55])
MaxPool2d output shape: torch.Size([1, 192, 27, 27])
Inception output shape: torch.Size([1, 256, 27, 27])
Inception output shape: torch.Size([1, 480, 27, 27])
MaxPool2d output shape: torch.Size([1, 480, 14, 14])
Inception output shape: torch.Size([1, 512, 14, 14])
Inception output shape: torch.Size([1, 512, 14, 14])
Inception output shape: torch.Size([1, 512, 14, 14])
Inception output shape: torch.Size([1, 528, 14, 14])
Inception output shape: torch.Size([1, 832, 14, 14])
MaxPool2d output shape: torch.Size([1, 832, 7, 7])
Inception output shape: torch.Size([1, 832, 7, 7])
Inception output shape: torch.Size([1, 1024, 7, 7])
AvgPool2d output shape: torch.Size([1, 1024, 1, 1])
Dropout output shape: torch.Size([1, 1024, 1, 1])
Flatten output shape: torch.Size([1, 1024])
Linear output shape: torch.Size([1, 1000])
Softmax output shape: torch.Size([1, 1000])
7 Likes
GoogLeNet中不同Inception块out_channels的个数和配比把我看蒙了,他们当初是进行了多少实验才找出来的
1 Like
第三块里面这句话为什么这样计算“第二个和第三个路径首先将输入通道的数量分别减少到 96/192=1/296/192=1/2 和 16/192=1/1216/192=1/12”
1 Like
因为第二个模块的输出通道数是192,第三个inception模块的第二个和第三个路径的第一个卷积(也就是中间那两个1×1卷积)的输出通道分别是96和16,所以这样算吧。
1 Like
使用GoogLeNet的最小图像大小是多少?
好像GoogLeNet对于图像最小没有限制,即便是1x1的图像(或者说像素点)在每个卷积层也可以通过padding达到处理的尺寸要求,还是我没理解到题目的意思
将AlexNet、VGG和NiN的模型参数大小与GoogLeNet进行比较。后两个网络架构是如何显著减少模型参数大小的?
后两类模型(NiN & GoogLeNet)通过使用1x1的卷积层代替全连层让模型参数大小显著减少
3 Likes
使用GoogLeNet的最小图像大小是多少?
卷积的过程中,有些层虽然padding填充了,但是stride不是1,导致规模仍然还是会缩小。所以输入的图像规模是有下限的。
将AlexNet、VGG和NiN的模型参数大小与GoogLeNet进行比较。后两个网络架构是如何显著减少模型参数大小的?
NiN确实是通过1x1卷积层代替全连接层让参数数目减少的
但是我个人觉得,GoogleNet这里是通过1x1卷积层先把通道维数降到很小,然后再把通道维数扩大。使得参数总体上个数更少。比如8x2+2x10<8x10这种感觉。
4 Likes
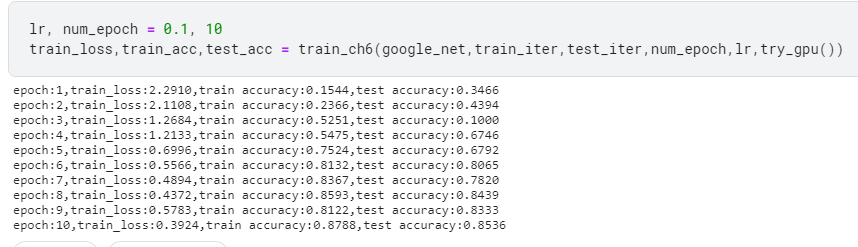
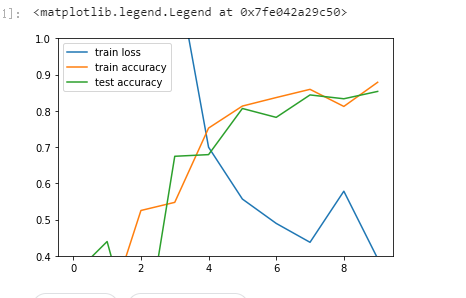
###############################
在模型输入维度或者通道数方面,torch 不如mxnet, tensorflow 那般友好,torch还得手动计算输入维度。
确实,same valid也得自己算padding的数值
1 Like
我改用Adam优化器网络就不work了,这是为什么呢
现在torch不是已经有lazyConv2D这种函数了吗
3 Likes
动手学习深度学习的英文版已经更新为自动识别维度的函数了,可以去看看.
3 Likes
老师同学们好,batch normalization那里有点晕,想拜托大家帮忙理一下我的理解:
结合代码看了看,训练时,是对每一层输出的X求一次均值方差,然后做归一化处理再做偏移和比例缩放,gamma和beta作为超参数的作用是使整个模型每一层的输出数相差不要太大,从而达到模型之间相统一方便收敛,而每层样本的归一化是为了这两个超参数更好的更新而服务的对吗?
期待各位大佬回复
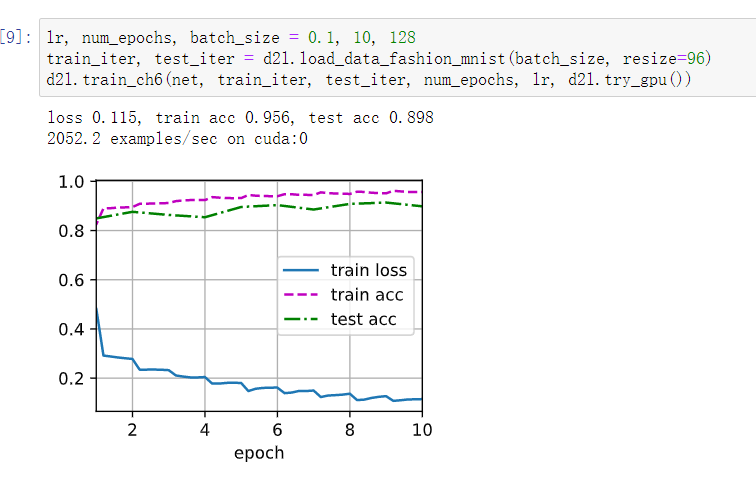
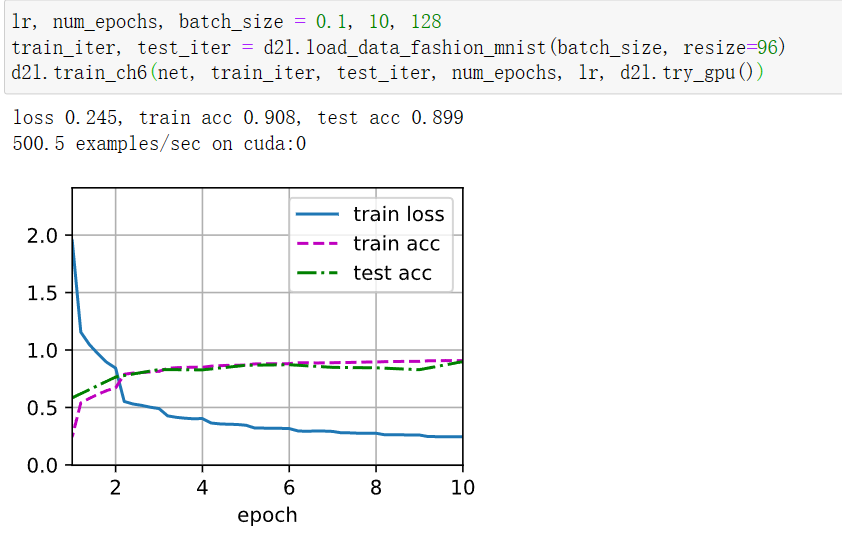
使用GoogLeNet的最小图像大小是多少?
只有前面的block1缩小了图片的大小,则最小图片大小为5x5,经过7x7卷积变3x3,再经过3x3的池化变1x1.
将AlexNet、VGG和NiN的模型参数大小与GoogLeNet进行比较。后两个网络架构是如何显著减少模型参数大小的?
NiN是采用11卷积替换全连接,VGG则是用多个小卷积核替代大的卷积核。(Googlenet也采用了11先降低通道维数减少计算参数的方式)
net一共把特征图缩小了2**5 = 32倍。是不是说net的输入最小是32x32?如果小于这个数,在进入第5个部分前,特征图就已经是1x1了,作用就不大了?
1)Inception合并4条path的输出通道数,不会改变特征图的尺寸
2)第一个7x7conv把特征图尺寸缩小一倍,(x+2*3-7)/2+1 → x/2
3)前4个部分的最后一层都是3x3 max pool,它会把特征缩小1倍,(x+2-3)/2+1 → x/2
4)在最后一层的global avg pool把特征图直接变成1x1
6)网络中其他层不会改变特征图的大小
2 Likes
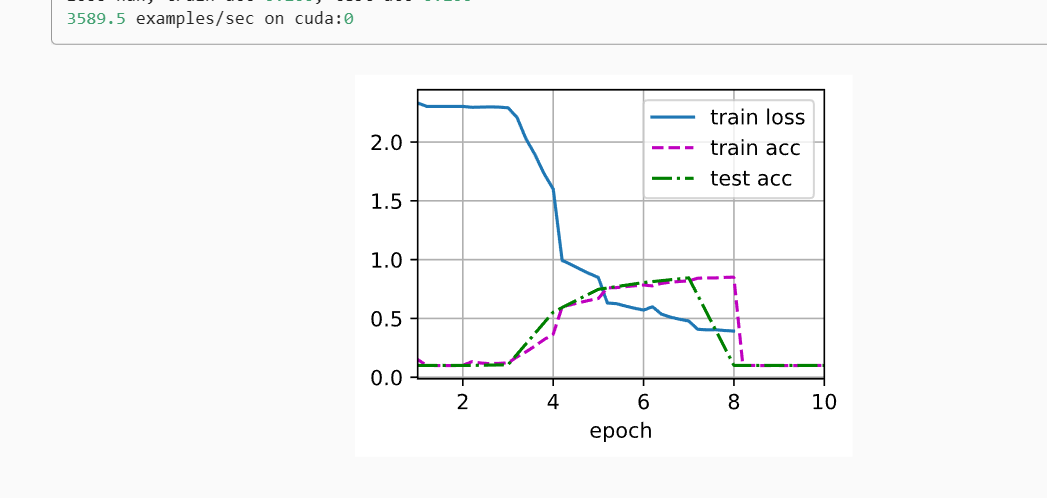
optimizer, lr, num_epochs, batch_size, resize = sgd, 0.1, 10, 128,96
epoch 10, loss 0.240, train acc 0.908, test acc 0.898
optimizer, lr, num_epochs, batch_size, resize = adam, 0.001, 10, 256,96
epoch 10, loss 0.175, train acc 0.935, test acc 0.918