如果只要让代码能运行,最小的输入应该可以是1x1吧。
Q1.1 和 Q1.2
class Inception2(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception2, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
self.bn1 = nn.BatchNorm2d(c1)
self.bn2 = nn.BatchNorm2d(c2[1])
self.bn3 = nn.BatchNorm2d(c3[1])
self.bn4 = nn.BatchNorm2d(c4)
def forward(self, x):
p1 = F.relu(self.bn1(self.p1_1(x)))
p2 = F.relu(self.bn2(self.p2_2(F.relu(self.p2_1(x)))))
p3 = F.relu(self.bn3(self.p3_2(F.relu(self.p3_1(x)))))
p4 = F.relu(self.bn4(self.p4_2(self.p4_1(x))))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
b31 = nn.Sequential(Inception2(192, 64, (96, 64), (16, 64), 64),
Inception2(256, 128, (128, 128), (32, 96), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))net2 = nn.Sequential(b1, b2, b31, b4, b5, nn.Linear(1024, 10))
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net2, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.177, train acc 0.935, test acc 0.909
1024.5 examples/sec on cuda:0
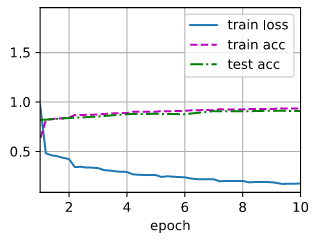
你好,会不会是梯度消失?还是过拟合了呢?
作业提交
- 因为inception module并不会缩小原始图像的像素,但是除了inception module外,有五个conv和maxpool会每次减半像素。因此最小的图像是32*32
- 显然,后面个model是因为没有使用全连接层从而导致参数减少
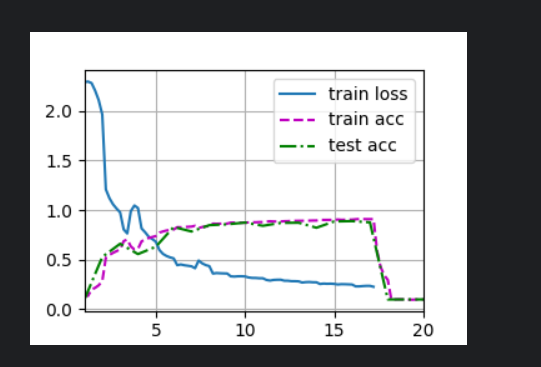
batch_size = 256,num_epochs=20 固定随机种子
loss nan, train acc 0.100, test acc 0.100
3690.9 examples/sec on cuda:0
为什么这样设置后降为了0.1
如果不使用BatchNorm在卷积后面,那么模型是不会收敛的,这很让人恼火!
真服了这个inception-v3看的我眼花(虽然也没怎么全看明白)
最后训练发现学习率一直有问题,查了一下SGD需要设置momentum=0.9(具体什么原理还没有看)
现在还有过拟合,糟心,洗澡 ![]()
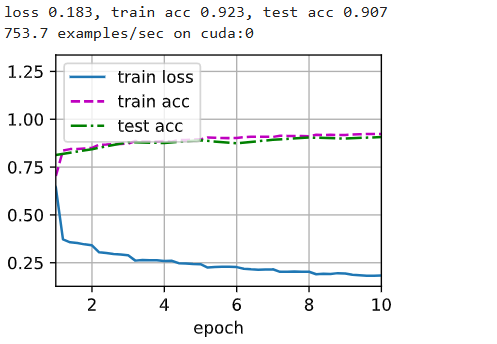
因为bn只能加快收敛速度,不能提高模型上限的