nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(), # 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过度拟合 nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5),
这里nn.Flatten()是什么作用,为什么经过它之后256变成了6400?
nn.Flatten()就是将矩阵铺平成向量,便于输入全连接层。
6400=256 * 5 * 5,
5 * 5是上一层conv出来feature map的大小
pytorch版本第一个卷积层pad=1,是写错了吗? Mxnet和TF版本都没有。
这里加不加这个padding=1不影响,你可以手算一下尺寸
我的理解时展平成二维张量, 比如输出的张量为[2, 2, 18, 18], 第一个2表示批量数据, 后面三个数据分别表示通道、宽、高,展平后就是【2, 21818】。
然后你说的256是输出的通道数而已,你可在池化后看看输出的的形状,就可以看出6400怎么来的
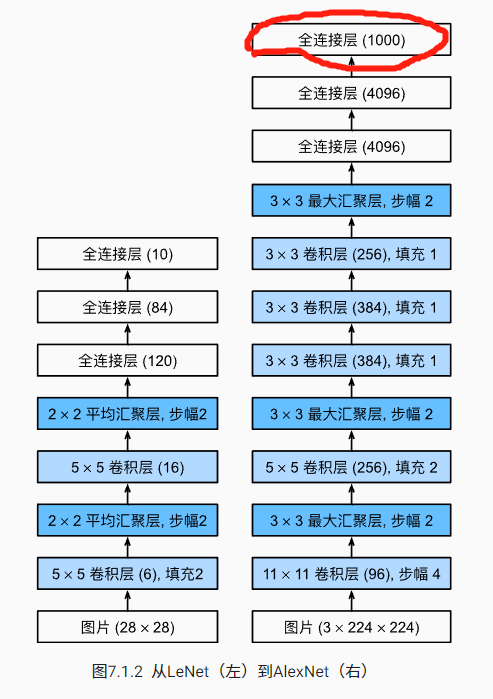
图7.1.2中image为3×224×224,请问代码中为什么没有体现3这个维度呢?
因为图7.1.2的输入是imagenet的shape – 3x224x224(可以从最后 一个全链接的shape是1000看出),而代码的输入是我们reshape后的fashion mnist(shape是1x224x224)
分析了AlexNet的计算性能。
在AlexNet中主要是哪部分占用显存?
这题我的理解是AlexNet里面不同层需要的参数大小决定了占用显存的大小
第一层卷积层卷积核参数个数:11x11x3x96=34848
汇聚层没有参数所以几乎不占任何显存
第二层卷积层卷积核参数个数:5x5x96x256=614400
第三层卷积层卷积核参数个数:3x3x256x384=884736
第四层卷积层卷积核参数个数:3x3x384x384=1327104
第五层卷积层卷积核参数个数:3x3x384x256=884736
第一层全连层参数(权重+偏移):6400x4096+4096=26218496
第二层全连层参数(权重+偏移):4096x4096+4096=16781312
第三层全连层参数(权重+偏移):4096x1000+1000=4100096
所以是第一层全连层占用了最多的显存
在AlexNet中主要是哪部分需要更多的计算?
第一层卷积层计算次数:54x54x96=279936
第一层卷积层的池化层计算次数:26x26x96=64896
第二层卷积层卷计算次数:26x26x256=173056
第二层卷积层的池化层计算次数:12x12x256=36864
第三层卷积层计算次数:12x12x384=55296
第四层卷积层计算次数:12x12x384=55296
第五层卷积层计算次数:12x12x256=36864
第五层卷积层池化层计算次数:5x5x256=6400
第一层全连层计算次数:4096
第二层全连层计算次数:4096
第三层全连层计算次数:1000
第一层卷积层需要最多次数的计算
计算结果时显存带宽如何?
这小题不太明白什么意思
前两小题不确定对不对,希望有大神可以指点下,谢谢!
参数我觉得没问题。但是计算那部分我认为有问题,每个卷积层的计算复杂度应该是O( Nw Nh Kw Kh Ci Co)有六个参数
针对10分类问题,最后一层Dense输出层的神经元设置不是应该也和分类类别数量一直嘛?最后才好在交叉熵损失函数中计算softmax函数的输出与真实标签的loss,这里的AlexNet示意图的最后一层全连接层数的神经元怎么设置为1000了,我看code里面相应位置神经元数量是10,请尽可能地保持代码和图例一直,不然可能会有些误导新手~
后面几页的图也都有类似的问题呦~大家看的时候请注意
第四题可以通过以下代码查看和比较各子层的计算量和参数量
model_name = 'AlexNet'
flops, params = get_model_complexity_info(net, (1, 224, 224), as_strings=True,
print_per_layer_stat=True)
print("%s |%s |%s" % (model_name, flops, params))老师讲的是原始Alexnet模型,是针对imagenet数据集的1000分类问题,为了便于训练,写的代码是fashion-minit数据集的10分类问题
这章跑的很慢。。如果只是测试下代码写的对不对的话,可以把epoch调低点

有用,我记得在 dropout 章节附近
大致验证了下,训练阶段 gpu 上 tensor 内存主要是:模型参数、模型参数对应的梯度、输入输出(包括中间输出和最终输出)

https://colab.research.google.com/gist/forMwish/9e2c1c6b82601631a483ff8ade0caa1d/-gpu.ipynb
这没啥问题,AlexNet 论文里由于 GPU 限制,将模型拆为两块,这里显示的是合并后的 AlexNet。1000 对应 imageNet 数据集的 1000 个分类
权重衰减在优化器中体现而不是在网络结构中体现,可以看下SGD中的代码