https://zh.d2l.ai/chapter_convolutional-neural-networks/lenet.html
为什么模型,在展开之后,用了三个Linear层,有什么说法吗,
如果直接从 Linear(400,10),效果会很差吗?
3 Likes
Why did the model, after it was expanded, use three Linear layers? Is there any explanation?
If I go directly from Linear(400,10), is this going to be bad?
不会很差。我对此使用以上代码做了一个实验(lr=0.9):
epoch=10:
3个Linear:loss 0.465, train acc 0.824, test acc 0.815
直接Linear(400,10):loss 0.430, train acc 0.844, test acc 0.838
epoch=20:
3个Linear:loss 0.309, train acc 0.885, test acc 0.872
直接Linear(400,10):loss 0.370, train acc 0.865, test acc 0.850
从以上实验可以看出:
在两个网络未收敛时(epoch=10),直接Linear(400,10)的效果其实不差,甚至比3个Linear的模型的效果要好。但是当我们将模型训练更多轮数之后,3个Linear的模型比直接一个Linear的模型效果要高2.2%(epoch=20)。
我直觉上来解释这个现象的话就是3个Linear的模型的模型复杂度更高,所以拟合数据能力更强,在没有过拟合的情况下,效果更好。
但是我想在设计模型的思路上来说的话,Lenet没有直接Linear(400,10)出来结果的原因是他想在CNN提取完特征后,先用MLP分类器(也是Linear)对特征做个分类,而单层的Linear的分类器可能太弱了?3个Linear也就是这个分类器的强度。
6 Likes
本次练习:
- 调节卷积窗口的大小
- 尝试调节为 1,2,3都报错了:
-
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x576 and 400x120)调节为3的报错
- 将 Avg 池化层变成 Max 池化层会怎么样
- train acc 提升了 2 个点,test acc 没有变
- 调整激活函数为 relu 会怎么样?
- 在 max 的基础上加了 relu,train acc 提升到了0.89,test acc 提升到了0.87
- 调节卷积层的数量:尝试在6,16的conv2d之后再加上一个conv2d,但是却出现了报错:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x144 and 400x120)暂未解决 - 调节全连接层的数量:在86,10全连接层之间加入一个
nn.Linear(86,50),train acc 和test acc都提升了。
3 Likes
请问一下,我在运行LeNet的pytorch代码时候,最后训练的时候出现错误: DataLoader worker (pid(s) 16668, 14864) exited unexpectedly,请问应该怎么解决 
我也遇到了同样的问题,发现系统盘突然多了15G的转存文件
1 Like
如果你在conda环境,尝试pip uninstall torch 然后输入conda install pytorch torchvision torchaudio cudatoolkit=11.0 -c pytorch
我的是rtx 3070,目前问题已经解决
image comparation
three linears
-
epochs = 10
loss 0.456, train acc 0.829, test acc 0.773 3290.8 examples/sec on cpu
-
epochs = 20
loss 0.364, train acc 0.866, test acc 0.841 3239.6 examples/sec on cpu
two linears
-
epochs = 10
loss 0.418, train acc 0.845, test acc 0.821 3180.9 examples/sec on cpu
-
epochs = 20
loss 0.331, train acc 0.879, test acc 0.863 3208.3 examples/sec on cpu
my try
1 Like
我也出现同样的问题,这个是因为线程数量设置过大导致的。需要修改本课程的 d2l包文件。路径在python安装目录下,我的是anaconda装的python,路径为D:\anaconda\Lib\site-packages\d2l\torch.py
你可以通过右击我的电脑,属性,高级系统设置,环境变量,查看python的安装路径,或者通过cmd命令行,然后python,
import sys
sys.path
找到 torch.py里的 get_dataload_workers()函数,把returen 4 改成 return0
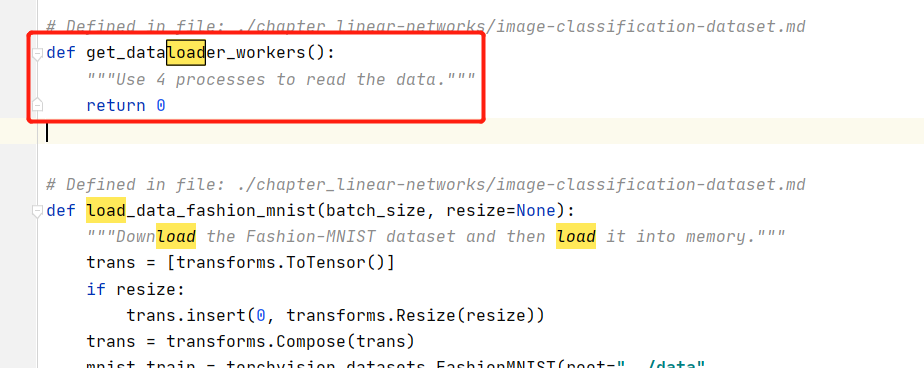
然后重启jupyter,运行就可以了
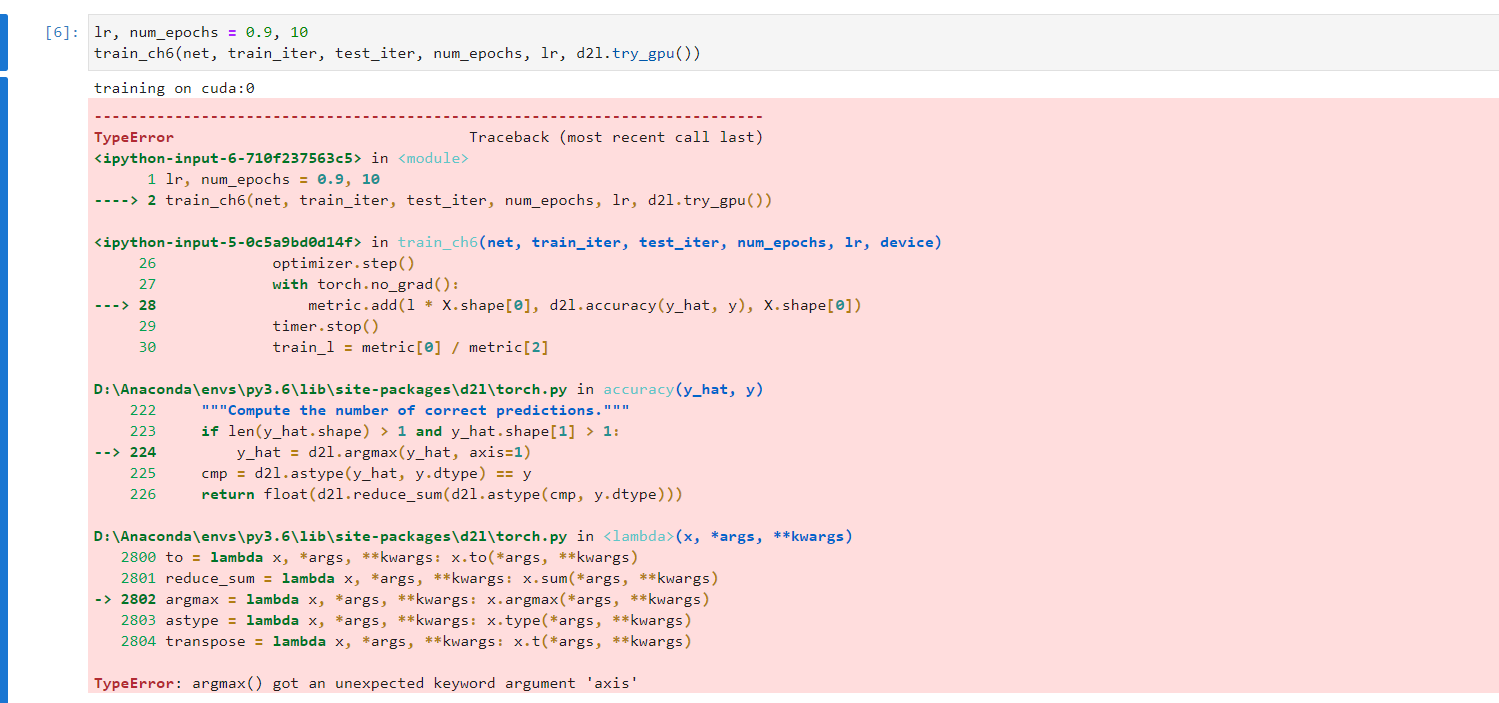
可以通过这条语句验证是否修改成功
from d2l import torch as d2l
d2l.get_dataloader_workers()
4 Likes
卷积层里的偏置项起到什么作用呢?防止过拟合么?
1 Like
我也遇到了这个问题,一运行代码c盘直接满了,请问你的问题解决了吗?
1 Like
我猜是因为没有偏置的话拟合超平面必须要穿过原点。而实际上拟合超平面不一定是穿过原点的。
2 Likes
我尝试着用了最大池化,并且将激活函数全部修改为ReLU,发现结果并不收敛,但我在我更改学习率为0.1之后它就能很快收敛了。可以预见的是就算是相似的网络结构某些超参数的调整仍是非常有必要的
3 Likes
为什么我有警告
UserWarning: Failed to load image Python extension: Could not find module ‘C:\Users\DELL.conda\envs\d2l-zh-gpu\Lib\site-packages\torchvision\image.pyd’ (or one of its dependencies). Try using the full path with constructor syntax.
咋办啊
pycharm中运行的话想要显示图形,需要加上plt.show()
1 Like
我尝试修改过d2l.train_ch6里面的代码,在里面加上了ply.show(),还是无法得到老师在jupyter里面的效果。
我也遇到同样的问题,请问应该怎么处理呢?