https://zh.d2l.ai/chapter_deep-learning-computation/parameters.html
请问练习4中,共享参数的好处是什么?是因为shared层的grad叠加,使得训练的速度更快吗?谢谢!
好问题!
共享参数通常可以节省内存,并在以下方面具有特定的好处:
- 对于图像识别中的CNN,共享参数使网络能够在图像中的任何地方而不是仅在某个区域中查找给定的功能。
- 对于RNN,它在序列的各个时间步之间共享参数,因此可以很好地推广到不同序列长度的示例。
- 对于自动编码器,编码器和解码器共享参数。 在具有线性激活的单层自动编码器中,共享权重会在权重矩阵的不同隐藏层之间强制正交。
12 Likes
从生物学角度,能否把参数类比成脑中的对于事物对结果的影响程度的判断?那对于类似事件,我们可以认为影响程度也相差不多,来减少额外的记忆。
里的强制正交是什么意思?
1 Like
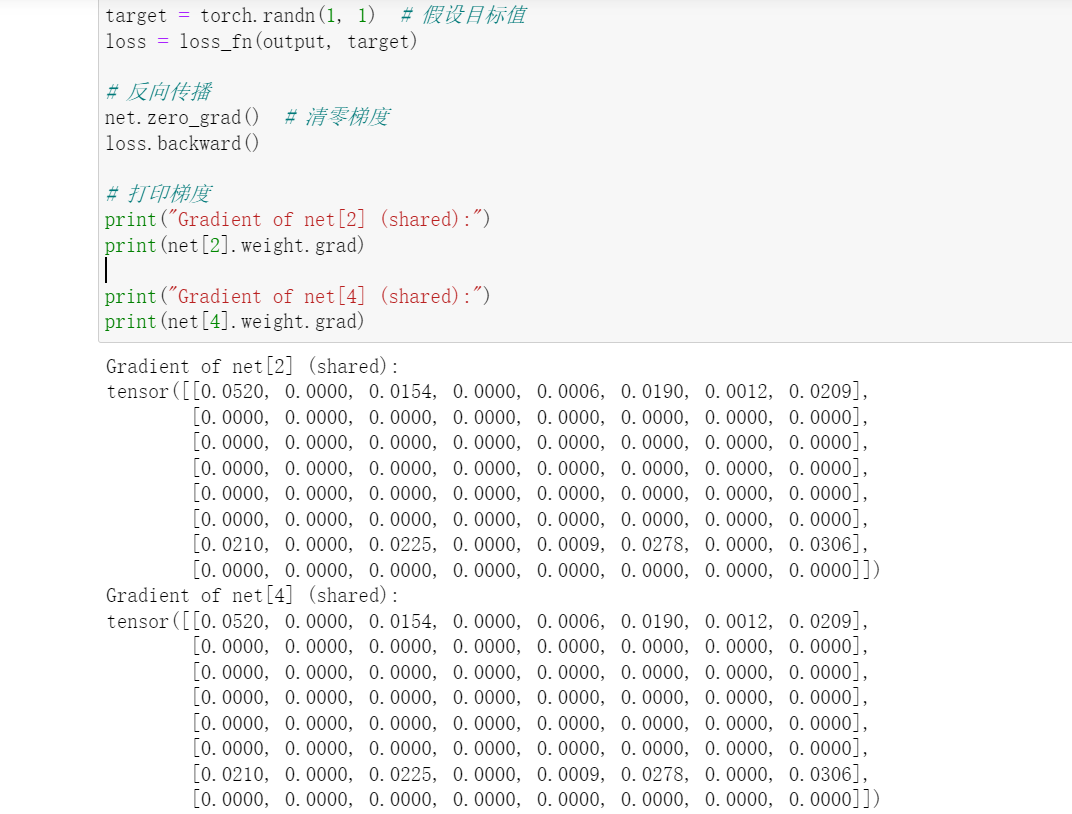
还想请问,一个模型中出现共享层时,一次backward()是否会导致共享层的最终grad是两个共享层梯度的和(因为一次backward()过程中,共享层第一次计算出的grad没有被清零),从而梯度下降时有更大的步幅,收敛的速度也更快呢?
“forces orthogonality”,如果有更地道的说法欢迎纠正。
理论上是的。你也可以选择关掉(frozen)任何一层的grad。
3 Likes
谢谢!字数字数字数字数字数字数字数字数字数
1 Like
第三个练习,请问怎么在训练过程中,观察模型各层的参数和梯度?没有想到合适的方法
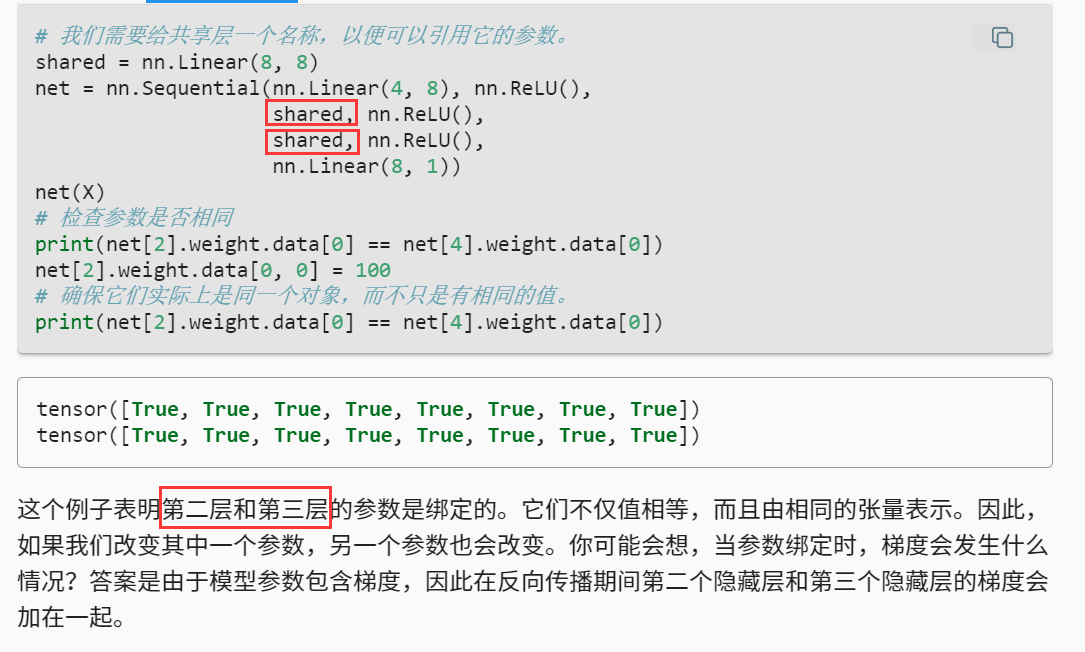
的确,从代码上看应该是“第三层(net[2])和第五层(net[4])的参数是绑定的”。
原文直接来自mxnet版本,估计没有根据pytorch版本的代码做对应修改。
1 Like
MXNET确实是这样(1和2),pytorch代码估计按照net里的层数算的
hi,我是修改了他的训练过程的函数。在每次epoch增加下面的语句 ,不知道你有没有什么更好的方法。
print(*[(name,param.grad) for name,param in net.named_parameters()])
def train_epoch_ch3(net, train_iter, loss, updater):
if isinstance(net,torch.nn.Module):
net.train()
for X,y in train_iter:
y_hat = net(X)
l = loss(y_hat,y)
updater.zero_grad()
l.backward()
updater.step()
print(*[(name,param.grad) for name,param in net.named_parameters()])
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
for epoch in range(num_epochs):
train_epoch_ch3(net, train_iter, loss, updater)
2 Likes
hi,可否请教你一个问题
参数共享在CNN中的体现是不是就是卷积核。(因为一个通道的一张特征图的卷积核只有一个)
1 Like
请问有没有探讨这一问题的相关文献呢?希望研读以下得到更深入理解。谢谢!
请问参数共享时,反向传播期间第二个隐藏层和第三个隐藏层的梯度加一起具体指什么意思呢?
2 Likes

应该是pytorch的linear层在进行矩阵乘法的时候把权重进行了转置。你可以看下后面自定义层的带参数层的部分,自行实现linear层的时候,使用torch.matmul的时候没有使用权重转置,这个时候的权重shape就是和linear层的输入输出是一致的。
1 Like
因为这两个层参数共享,梯度这个参数也共享了,传播的梯度还没有清零 所以累加了