https://zh.d2l.ai/chapter_multilayer-perceptrons/weight-decay.html
1.λ 太大后,train和test的loss会变得很大,太小后,train的loss会低,但是test的loss会很高.
2.它是相对于这个训练集和测试机的最优值。如果数据集的大小改变,那么这个λ 值也会随之改变。
5.调节学习率大小。
3 Likes
1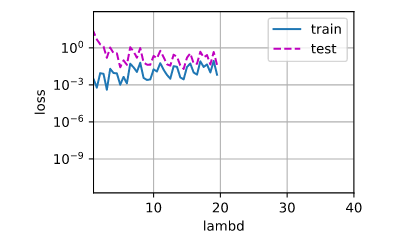 一开始test_loss会随着lambd增大而减小,但是随后就开始震荡
一开始test_loss会随着lambd增大而减小,但是随后就开始震荡
3 Likes
2,不是最优的lambd,因为实际数据也不可能和验证集分布一样,但是是在验证集上表现最好的,泛化性能因为会比较优秀。
3,def l1_penalty(w):
return torch.abs(w).sum()
3 Likes
权重衰减是为了避免过度关注无效特征(如噪声)而导致过拟合,那么如果没有噪声的话是不是就不需要权重衰减了?
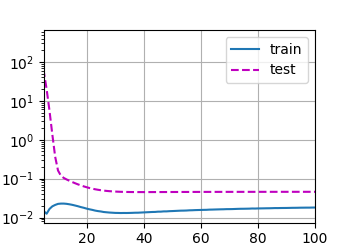
实验不同的Lambd值,同样的实验数据,Lambd 在大概80以后趋于平稳,Loss差几乎不再变化。
1 Like
我想请问下这个代码是如何实现的,我试了好久不会实现, ,我有点不知所措了。
,我有点不知所措了。
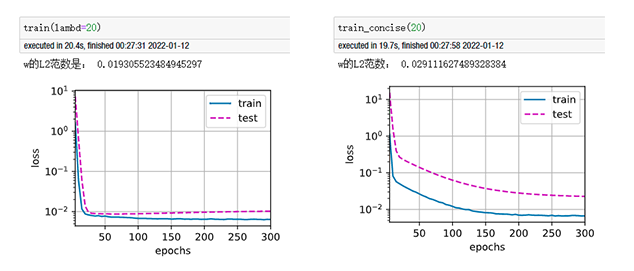
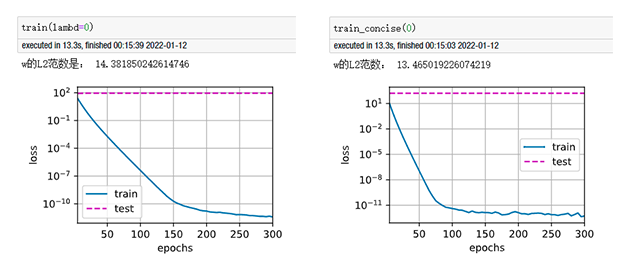
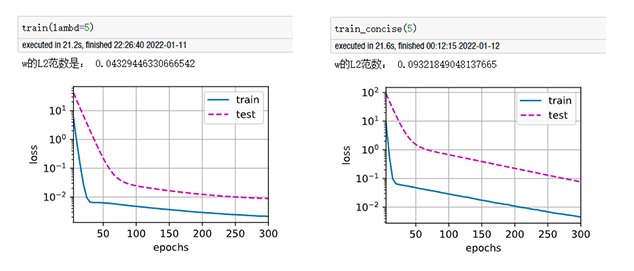
我在对比从零实现版本与简洁实现版本结果区别时,epoch=300,分别设定wd=0、5、10、20,发现当使用权重衰减时,反而简洁实现版本收敛速度慢于从零实现版本,且精度也不如,实验了多次仍是这样,请问这是什么原因?
以下是结果对比图(左图为从零实现,右图为简洁实现):
以下是补充:
1 Like
1 Like
平方范数和标准范数(即欧几里得距离)不是一个东西吗?那里没看懂
一个没开方,一个开了方  。。。。。
。。。。。
1 Like

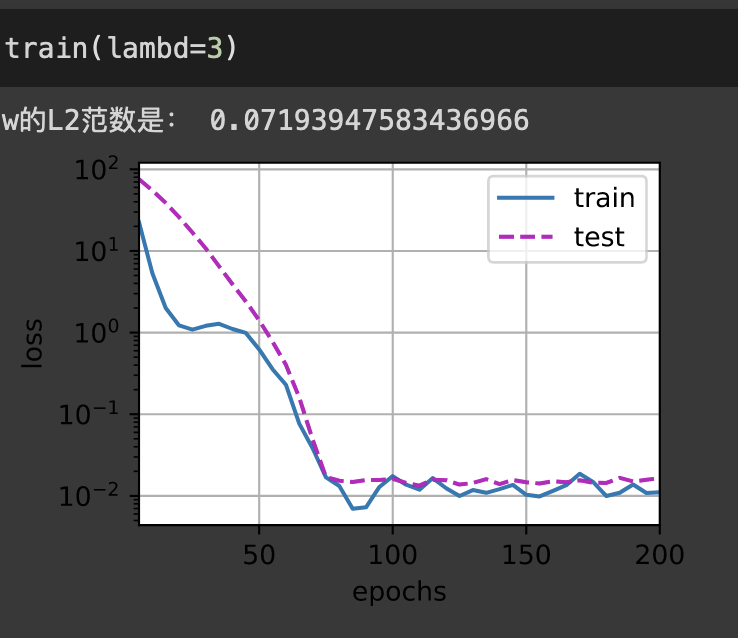
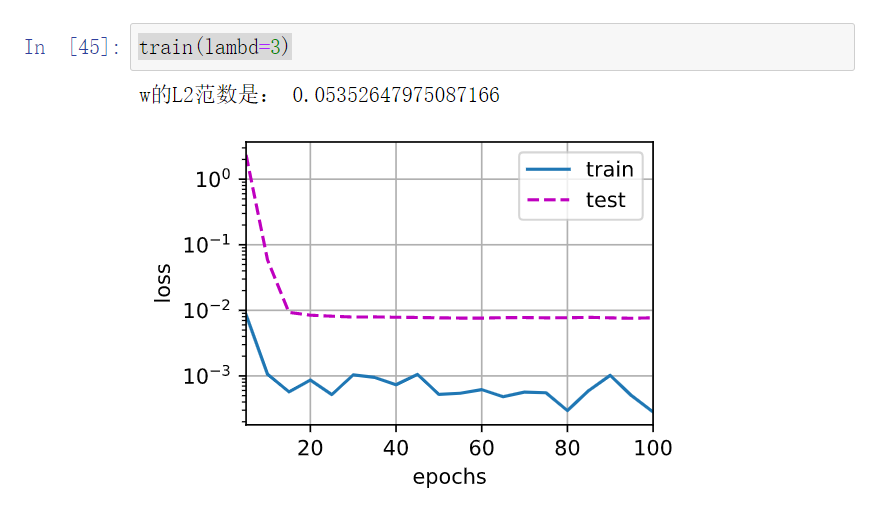
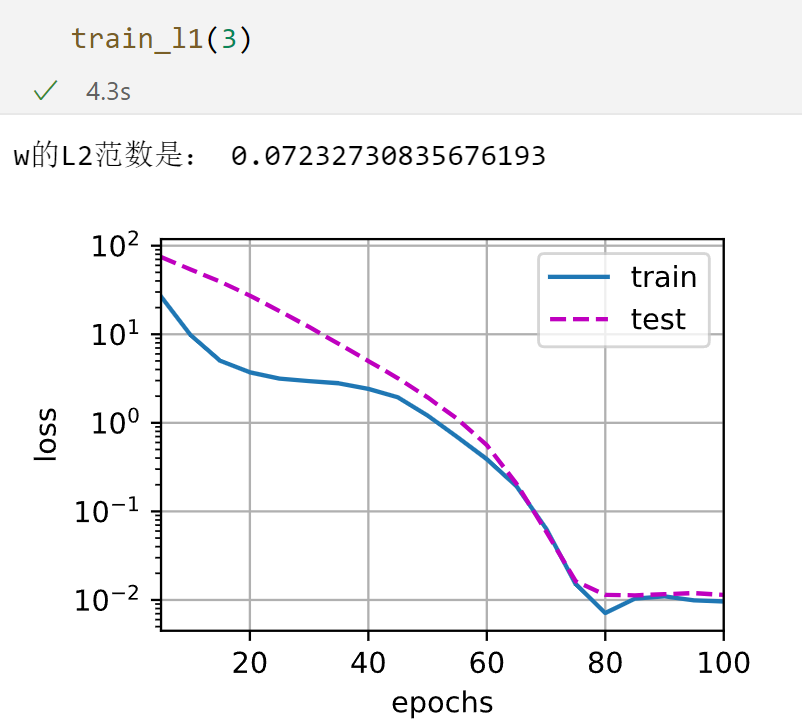
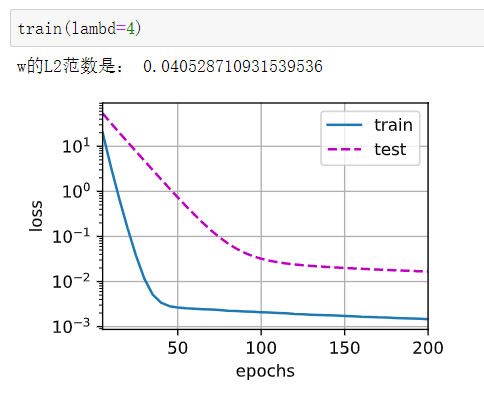
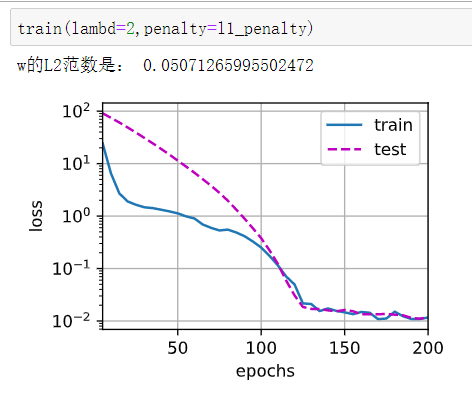
在这个模型中,貌似L1正则表现得更好。
1 Like
你好,想问下你是用的什么编辑器呀,可以提供软件名吗?感谢感谢
在最大化后验概率得到目标函数的问题中。如果先验分布是高斯分布,则对应L2正则化。如果先验分布是拉普拉斯分布,则对应L1正则化。
2 Likes
问题四:$$\Vert \mathbf{X}\Vert_{F}^{2}=trace(\mathbf{X}^T\mathbf{X})$$