想请教一下老师,在使用多层感知机进行分类的时候,有没有什么方法知道我的原始输入中具体哪一些特征对分类的贡献比较大。
是不是可以看一下分类结束时哪一个部分的权重更大?
请教一下第二题的严格证明过程~虽然自己做实验以及能理解是连续多段分段函数,但是没有办法证明~
第四题的题干是什么意思呢= =感觉题目很有意思
对于第二题,我是这样想的。绘制出RELU(x)的图像后,我们可以发现,如果输出值经过下一层隐藏层的计算,如果<0则这个数据被舍弃。相当于一个状态在某一层中会被筛选,而被筛选的条件由下一层隐藏层决定,然而这个状态是连续的,因此就会产生类似于分段的效果。
第三题:证明tanh(x) + 1 = 2 sigmoid(2x)。
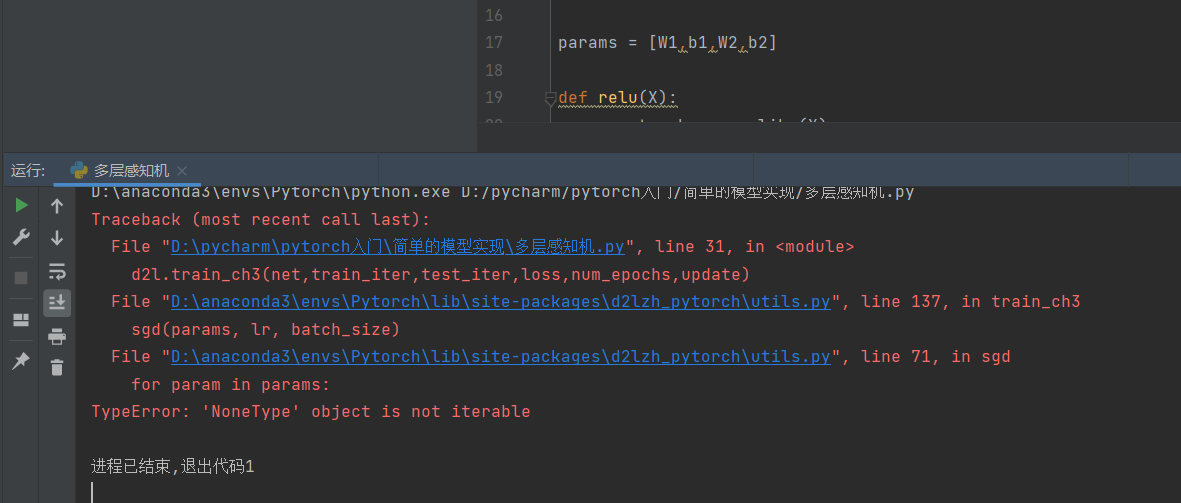
为什么下面这个计算出来不等呢?
z = torch.tensor([1.0,1.5,2.], dtype=float)
b = torch.tanh(z)+1.0
c = 2.0torch.sigmoid(2.0z)
print(b.data,c.data)
c.eq(b)
tensor([1.7616, 1.9051, 1.9640], dtype=torch.float64) tensor([1.7616, 1.9051, 1.9640], dtype=torch.float64)
Out[134]:
tensor([False, False, True])
我在用d2l.plot的时候报错了,但是我搜stackoverflow上说这个不兼容的bug在matplotlib 3.0.1就修复了,而我的环境是python 3.8和matplotlib 3.5.1,请问要怎么解决呢
ImportError: cannot import name ‘_check_savefig_extra_args’ from ‘matplotlib.backend_bases’ (/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/matplotlib/backend_bases.py)
误差哇,计算机中的浮点数不是精确表示的。你看上边print的结果是一样的。
您好,请问您的问题解决了吗,我也遇到了这样的问题
这节课课本的机翻痕迹还是有点重……比如“ 即使在不改变输入或输出大小的情况下, 可能在参数节约和模型有效性之间进行权衡”,还有“可我们能从中得到什么好处呢? 你可能会惊讶地发现:在上面定义的模型里,我们没有好处! ”希望老师可以在后续版本中改进一下文字表述,可能对中文读者会更加友好一些
: )
!pip uninstall matplotlib
!pip install matplotlib==3.0.0
请教老师:下面是一段tensorflow的一段定义NN的代码,它用函数定义了一个NN模型。pytorch能这样吗?如果可以pytorch的等效代码该怎样写(常见pytorch自定义模型都使用的是class)?
def network(x, t):
y = math.stack([x, t], axis=-1)
for i in range(8):
y = tf.layers.dense(y, 20, activation=math.tanh, name=‘layer%d’ % i, reuse=tf.AUTO_REUSE)
return tf.layers.dense(y, 1, activation=None, name=‘layer_out’, reuse=tf.AUTO_REUSE)
用归纳法是不是可以啊,·················
because there is no grad and you don’t need to set it to zero.
解决了
将 loss设置为loss = nn.CrossEntropyLoss(reduction=‘none’)
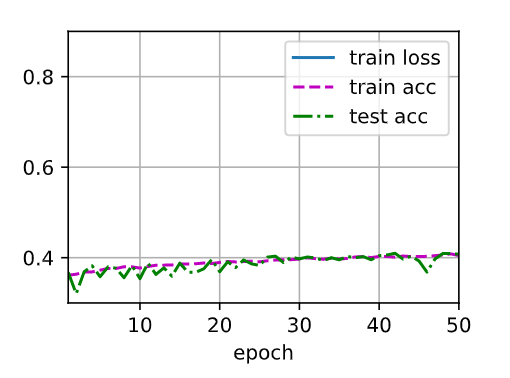
参数全1初始化之后训练明显变慢,训练效果很差,是为什么呢
关于作业题第四题的一些个人想法。
由于数据量样本比较少,可能存在样本的数据都比较集中的问题,如全都小于0,那么用ReLU就全部无法激活了,或者数据都比较大,那么用sigmoid或者tanh等,输出的数据都会趋向于1导致区分度太小了。
