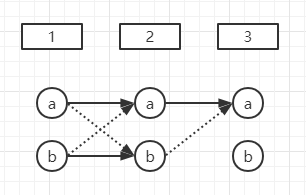
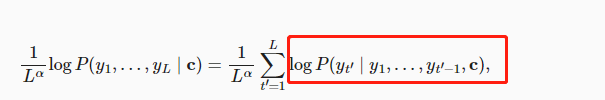是的, 在视频里面有说明:
我觉得束搜索和Viterbi其实都是可以的。
这里没有采用Viterbi的原因主要是每一步可能的选项太多了,使用Viterbi的开销依然很大。
在我的理解里面, Beam Search只是一种选择序列的方法, 并没有需要学习的参数叭?


beam search是在预测的时候使用,而且不需要进行训练;训练的时候有真实的标签并且可以计算损失函数。

可以通过将序列的softmax输出相乘得到转移概率

some questions:
q1: 作者在介绍greedy search时的反例与 beam search的实现策略并非一致,后者只是从root节点分支,分支后各自独立。所以说beam search并不能解决反例
q2: greedy search的反例是多数情况吗?毕竟训练时也是按照概率大的来选择的,而且RNN本身有state context机制,难道‘名师出高徒’可能性不大于‘庸师出高徒’?
明显是漏了exp,与bleu类似的。。。


把P放到指数上面能说得通,结合上面提到的b站视频这里应该是漏掉了。

尽管求和 $\sum \log P$ 是负值,最大化这个表达式意味着找到概率 (P\left(\mathbf{y}_{t^\prime} \mid \mathbf{y}1, \cdots, \mathbf{y}{t^\prime-1}, \mathbf{c}\right)) 的乘积最大的序列 (\mathbf{y}),即,找到联合概率最大的序列,经过长度归一化后的得分最高的情况。
我觉得还有一个更重要的原因是:常规的自然语言模型不满足马尔可夫性,所以不满足维比特算法适用的前提。
RNN 实现单步计算满足马尔可夫性,但整体序列建模能力超越马尔可夫性,毕竟,通过隐状态传递了历史信息。