Hi, everyone,
Please help me out the below code snippet for weight decay implementation.
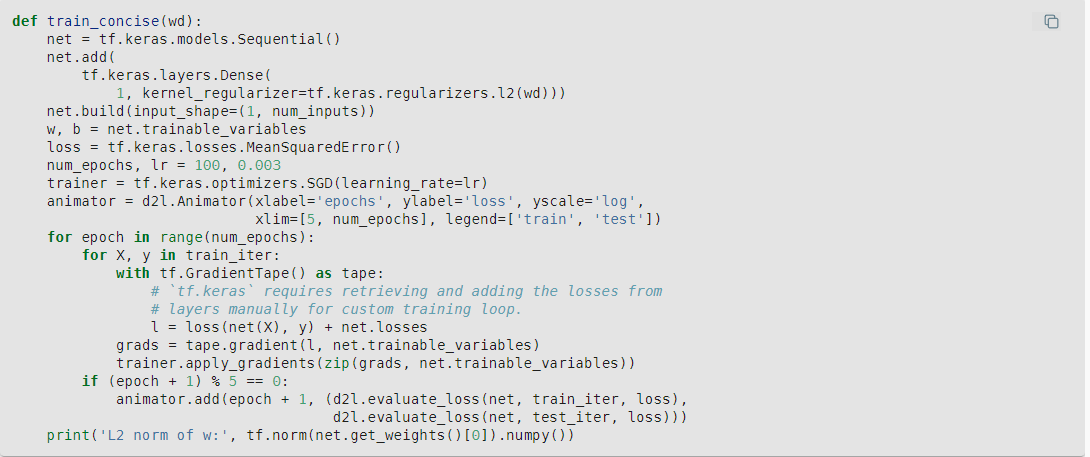
Especially, the part about the new “net.losses” which is not used in the previous implementations of custom training loop.
The previous implementations had just the losses accrued by the backward pass as shown below:
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""The training loop defined in Chapter 3."""
# Sum of training loss, sum of training accuracy, no. of examples
metric = Accumulator(3)
for X, y in train_iter:
# Compute gradients and update parameters
with tf.GradientTape() as tape:
y_hat = net(X)
# Keras implementations for loss takes (labels, predictions)
# instead of (predictions, labels) that users might implement
# in this book, e.g. `cross_entropy` that we implemented above
if isinstance(loss, tf.keras.losses.Loss):
l = loss(y, y_hat)
else:
l = loss(y_hat, y)
if isinstance(updater, tf.keras.optimizers.Optimizer):
params = net.trainable_variables
grads = tape.gradient(l, params)
updater.apply_gradients(zip(grads, params))
else:
updater(X.shape[0], tape.gradient(l, updater.params))
# Keras loss by default returns the average loss in a batch
l_sum = l * float(tf.size(y)) if isinstance(
loss, tf.keras.losses.Loss) else tf.reduce_sum(l)
metric.add(l_sum, accuracy(y_hat, y), tf.size(y))
# Return training loss and training accuracy
return metric[0] / metric[2], metric[1] / metric[2]
Did the previous implementations not have since there was no sequential model involved and in the MLP implementation, there is?
Also, please help me out the phrase "losses occurred " during the forward pass.. I assumed that losses were only applied during backward pass
This is a modification of the previous train(lambd) method defined earlier in the section. In that initial method we add the l2_penalty scaled by the hyperparameter lambd:
l = loss(net(X), y) + lambd * l2_penalty(w)
In this concise implementation that term (lambd + l2_penalty(w)) is calculated automatically for us in the dense layer since we initialized with the kernel_regularizer=tf.keras.regularizers.l2(wd) (note the parameter name changed from lambd to wd [weight decay], but is the same hyperparameter).
We access this l2 norm penalty from the net by calling net.losses and adding it to the MeanSquaredError loss.