不要用默认的github版本的d2l,限定一个版本号:
!pip install d2l==0.17
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
请问在这部分中,in_channels有变化吗?我理解的python参数传递单个变量是不会修改的,但如果没有变化,第二块开始时输入通道就不再是1了
有没有尝试用mps跑啊,感觉会快一点,不过我当时也花了一个小时左右
1 Like
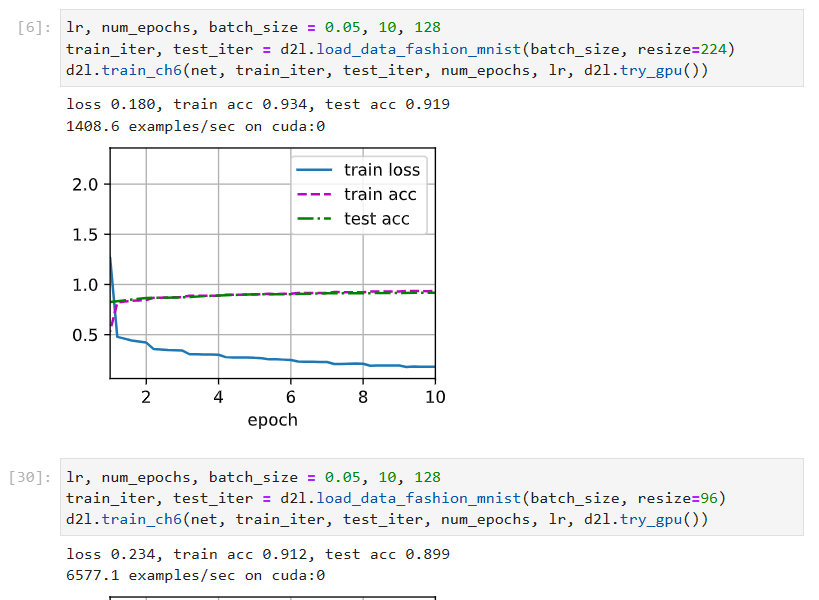
question1:剩余三层包含在后面三个模块里面
question2:参数大小决定了占用显存大小,VGG11与AlexNet区别主要是卷积层和第一层线性层的大小
AlexNet中
第一层卷积层卷积核参数个数:11x11x3x96=34848
汇聚层没有参数所以几乎不占任何显存
第二层卷积层卷积核参数个数:5x5x96x256=614400
第三层卷积层卷积核参数个数:3x3x256x384=884736
第四层卷积层卷积核参数个数:3x3x384x384=1327104
第五层卷积层卷积核参数个数:3x3x384x256=884736
第一层全连层参数(权重+偏移):6400x4096+4096=26218496
参数总数为=3745824+26218496=29964320
VGG11中
第一层卷积层卷积核参数个数:3x3x3x64=1728
第二层卷积层卷积核参数个数:3x3x64x128=73728
第三层卷积层卷积核参数个数:3x3x128x256=294912
第四层卷积层卷积核参数个数:3x3x256x256=589824
第五层卷积层卷积核参数个数:3x3x256x512=1179648
第六层卷积层卷积核参数个数:3x3x512x512=2359296
第七层卷积层卷积核参数个数:3x3x512x512=2359296
第八层卷积层卷积核参数个数:3x3x512x512=2359296
第一层全连接层参数(权重+偏移):7x7x512x4096+4096=102764544
参数总数=9216000+102764544=111980544
可以看出VGG11参数总数是AlexNet的三倍左右,所以需要占用更多显存。
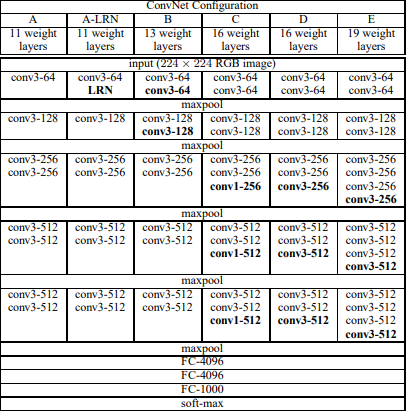
question4:
按照论文构建VGG16网络
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
if out_channels >= 256:
layers.append(nn.Conv2d(out_channels, out_channels, kernel_size=1))
layers.append(nn.ReLU())
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
def vgg16(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
conv_arch = ((2, 64), (2, 128), (2, 256), (2, 512), (2, 512))
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg16(small_conv_arch)
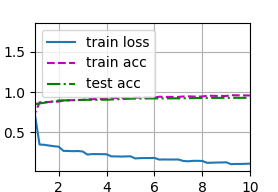
训练结果比VGG11效果要好
loss 0.114, train acc 0.958, test acc 0.929
3 Likes
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
上述代码中,in_channels = out_channels有必要吗,因为每次调用vgg_block,in_channels只用一次,再更新它有必要吗
才 40度炸什么, 80度以下都没什么问题
一个vgg block 里可能有两个卷积层啊 ,又不是一个
我用RTX 4060只跑了6分钟,还是用N卡好点
1 Like
第一个是样本数,也可以说批量数,第二个是通道数
我用4090花了8分钟,感觉有点怪怪的。。。
有没有可能是batch size的问题?4090理论上限应该比4060高,但是如果batch size小了的话并行计算没有达到4090的上限,那可能4090和4060跑的差不太多?
m3 mackbook 用mps也可以跑,只是慢一点,
loss 0.179, train acc 0.933, test acc 0.913
721.5 examples/sec on mps
我的gpu快65摄氏度了,真要炸了就凉了
这里是可以看到所有11层的代码。(conv和linear)
def print_shape(blocks):
X = torch.randn((1,1,224,224))
for block in blocks:
if isinstance(block,nn.Sequential):
print(f"{block.__class__.__name__}:")
for module in block:
X = module(X)
if(module.__class__.__name__ in ["Conv2d","Linear"]):
print(f" \t{ module.__class__.__name__},output: \t {X.shape}")
else:
X = block(X)
print(f"{block.__class__.__name__},output: \t {X.shape}")
#传入一个nn.sequential 类,打印出每一层过后的形状
print_shape(vgg(conv_arch))
你把alexnet的dropout设置成0.6,可能就胜过了vgg16
65度还很正常,平时也得四五十度,别持续90+就ok
我4070花了6分钟多,epoch=10
4060,我差不多10分钟,温度一直60多度