import torch
import torch.nn as nn
in_channel, out_channel = 1, 1
padding = 2
avg_pooling = nn.Conv2d(kernel_size=2, in_channels=in_channel, out_channels=out_channel, padding=0,stride=padding,bias=False)
nn.init.constant_(avg_pooling.weight, 1/4)
print(avg_pooling.weight)
X = torch.range(start=1, end=16).reshape((1,1,4, 4))
y = avg_pooling(X)
print(y)
'''
Parameter containing:
tensor([[[[0.2500, 0.2500],
[0.2500, 0.2500]]]], requires_grad=True)
tensor([[[[ 3.5000, 5.5000],
[11.5000, 13.5000]]]], grad_fn=<ConvolutionBackward0>)
'''
$c*((h+p_h-p_h)/s_h + 1 )((w+p_w-p_w)/s_w + 1 ) (p_h*p_w-1 +1)$ -1是加法个数 后面+1是除法个数
一个是找最大的元素,更侧重于检测响应大的点,求均值则会在一定程度上进行空间位置的融合。
最小汇聚层指的是最小响应的值?这样会造成信息大量丢失?
softmax需要学习参数且计算复杂
我也感觉实现不了
第一题:
import torch
import torch.nn as nn
# 定义一个简单的神经网络,其中包含一个平均池化层
class SimpleNet(nn.Module):
def __init__(self, kernel_size, stride=None, padding=0):
super(SimpleNet, self).__init__()
if stride is None:
stride = kernel_size
self.avg_pool = nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding)
def forward(self, x):
return self.avg_pool(x)
# 示例使用
x = torch.randn(1, 1, 8, 8) # 批量大小1,1个通道,8x8的输入
model = SimpleNet(kernel_size=3, stride=2, padding=1)
output = model(x)
print("输入:")
print(x)
print("输出:")
print(output)
第二题:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MaxPoolAsConv(nn.Module):
def __init__(self, kernel_size, stride=None, padding=0):
super(MaxPoolAsConv, self).__init__()
if stride is None:
stride = kernel_size
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
def forward(self, x):
# Apply max pooling directly using PyTorch's max_pool2d function
return F.max_pool2d(x, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding)
x = torch.randn(1, 1, 8, 8) # 批量大小1,1个通道,8x8的输入
model = MaxPoolAsConv(kernel_size=3, stride=2, padding=1)
output = model(x)
print("输入:")
print(x)
print("输出:")
print(output)
第三题:
第四题:
最大汇聚层(Max Pooling Layer):
工作方式:在每个池化窗口中,最大汇聚层选择窗口内的最大值作为输出。
特点:强调最强的激活,保留最显著的特征。
平均汇聚层(Average Pooling Layer):
工作方式:在每个池化窗口中,平均汇聚层计算窗口内所有值的平均值作为输出。
特点:平滑特征,保留整体信息的平均水平。
使用场景的不同
最大汇聚层的使用场景:
通常用于捕捉图像中的最显著特征,如边缘、角点等。
在分类任务中,可以帮助网络更好地捕捉到关键特征。
平均汇聚层的使用场景:
常用于需要保留更多背景信息的任务,如图像恢复、去噪等。
在一些平滑特征的任务中表现更好,如生成模型或风格迁移。
第五题:
第六题:
有办法只填充左(或者上)边而不填充右(或者下)边吗?
我的看法是:原输入在经过softmax之后,丢失了原本的特征信息,因为softmax的输出是各个输入在总输入中占的权重比例,那么即使原输入不一样,也很有可能,在总输入中的比例相近。那么,softmax就会得出:这两个输入特征一致,但是事实上,他们并不相同
W.Yun
July 2, 2025, 2:39pm
28
不是很确定我对Q1和Q2的题意理解是否正确,但还是改造了一下
# Q1
def corr2d(X, ksize):
Y = torch.zeros((X.shape[0] // ksize, X.shape[1] // ksize))
for i in range(Y.shape[0]):
for j in range(Y.shape[-1]):
Y[i, j] = (X[i*ksize:i*ksize+ksize, j*ksize:j*ksize+ksize].mean()).sum()
return Y
# Q2
def corr2d(X, ksize):
Y = torch.zeros((X.shape[0] // ksize, X.shape[1] // ksize))
for i in range(Y.shape[0]):
for j in range(Y.shape[-1]):
Y[i, j] = (X[i*ksize:i*ksize+ksize, j*ksize:j*ksize+ksize].max()).sum()
return Y
默认步幅与核心形状相同,且默认核心为高宽一致的矩阵
还是翻译成池化层比较好。汇聚层上来把我直接打懵了。
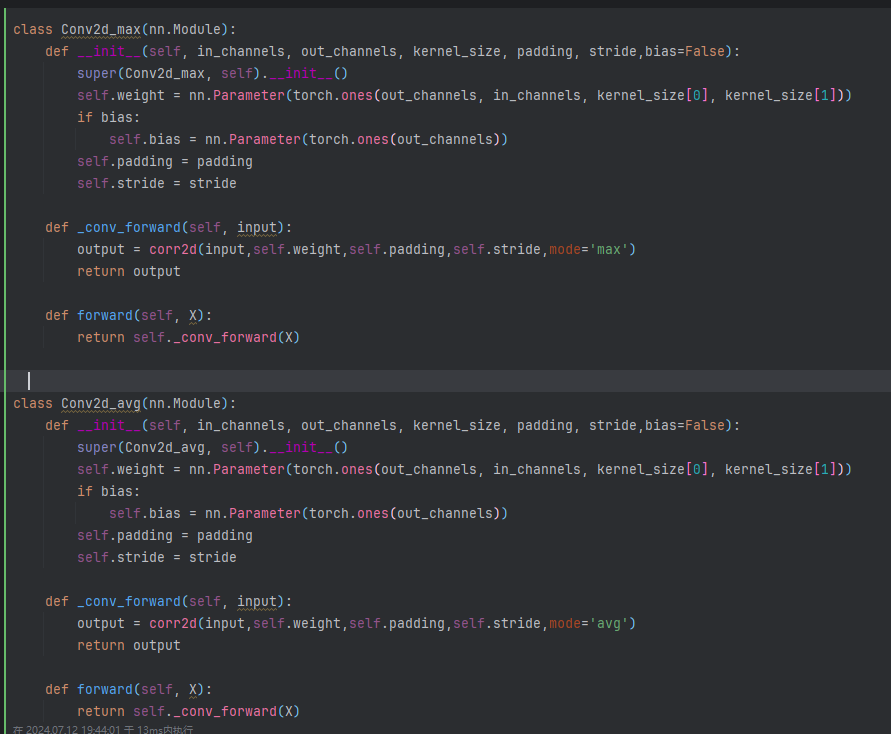
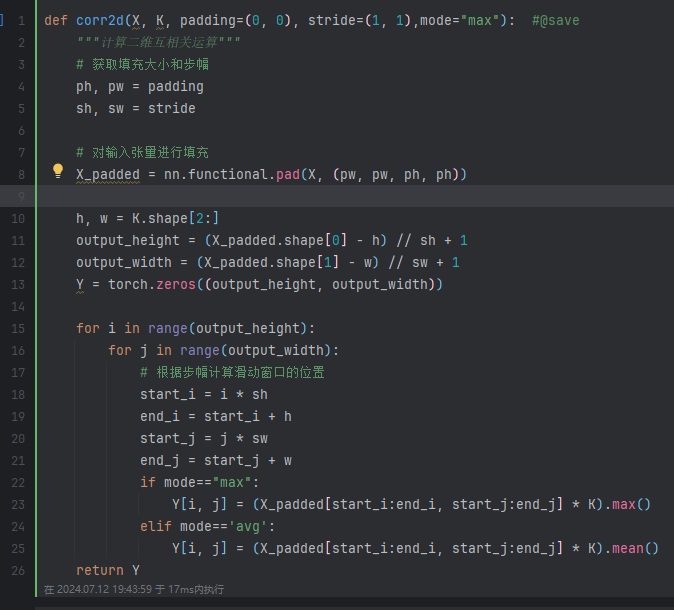
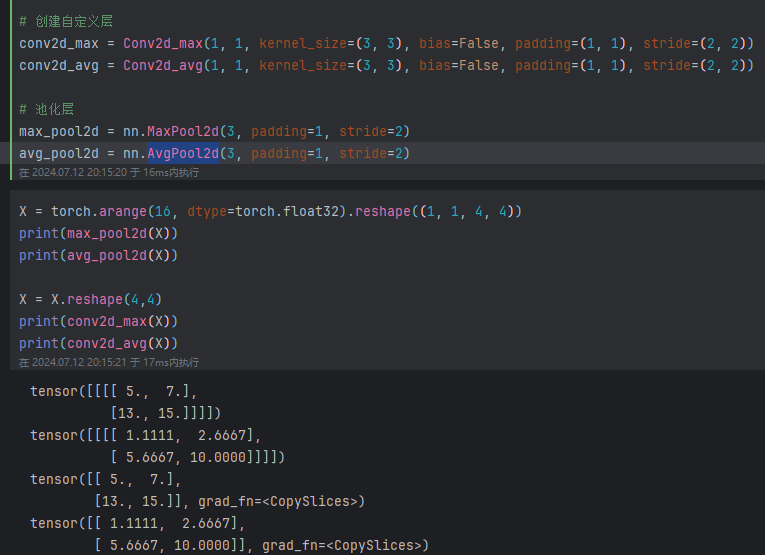
在Q2里,maxpool应该是不可以用卷积层等效实现的,卷积是线性运算而求max不是。Q1可以直接用预先定义好的矩阵作为kernal求出结果,可以作为卷积的特殊情况,但是max是不可以的,所以我认为评论区给出的Q2答案是错误的。
yzhacn
June 21, 2026, 6:05am
31
6.5. 汇聚层 大标题下面的内容的最后一段的最后一句是不是应该翻译成“本节将介绍汇聚(pooling)层,它具有双重目的:① 降低卷积层对位置的敏感性,② 以及对表示进行空间降采样。”? “低对空间降采样表示的敏感性”我无法理解。