我们还可以[通过提供包含数值的Python列表(或嵌套列表),来为所需张量中的每个元素赋予确定值 ]。 在这里,最外层的列表对应于轴0,内层的列表对应于轴1。
原文解释太难懂了,应该写成,在这里,最外层的列表对应于第一个维度,内层的列表对应于第二个维度。
我们还可以[通过提供包含数值的Python列表(或嵌套列表),来为所需张量中的每个元素赋予确定值 ]。 在这里,最外层的列表对应于轴0,内层的列表对应于轴1。
原文解释太难懂了,应该写成,在这里,最外层的列表对应于第一个维度,内层的列表对应于第二个维度。
默认创建的就是64int啊,源码如下图

因为广播的是大小为1的轴,适用于如形状(3,1)和形状(1,2)矩阵的操作,或者如形状(3,3)和形状(3,1)矩阵的操作
3,4 和 (3,4)都是创建的元组,应该是等价的呀
2.1.5 节省内存 这一节第三块代码段
before = id(X)
X += Y
id(X) == before
建议修改为
before = id(Y)
Y += X
id(Y) == before
以便于和本小节第一块代码段做对比。我理解作者意图是说明Y=Y+X和Y+=X在功能上一致,但前者会创建新的内存地址,后者则不会。所以原文中以X+=Y来说明这样做可以减小操作内存开销会让人很迷惑:Y=Y+X和X+=Y除了赋值对象不同外,这两个操作没有别的差别啊?我这样建议的理由是:这样更容易让人觉察出Y=Y+X和Y+=X虽然功能一致,但内部实现还是有差别的,供大家批评指正
a little mistake but good analysis anyway
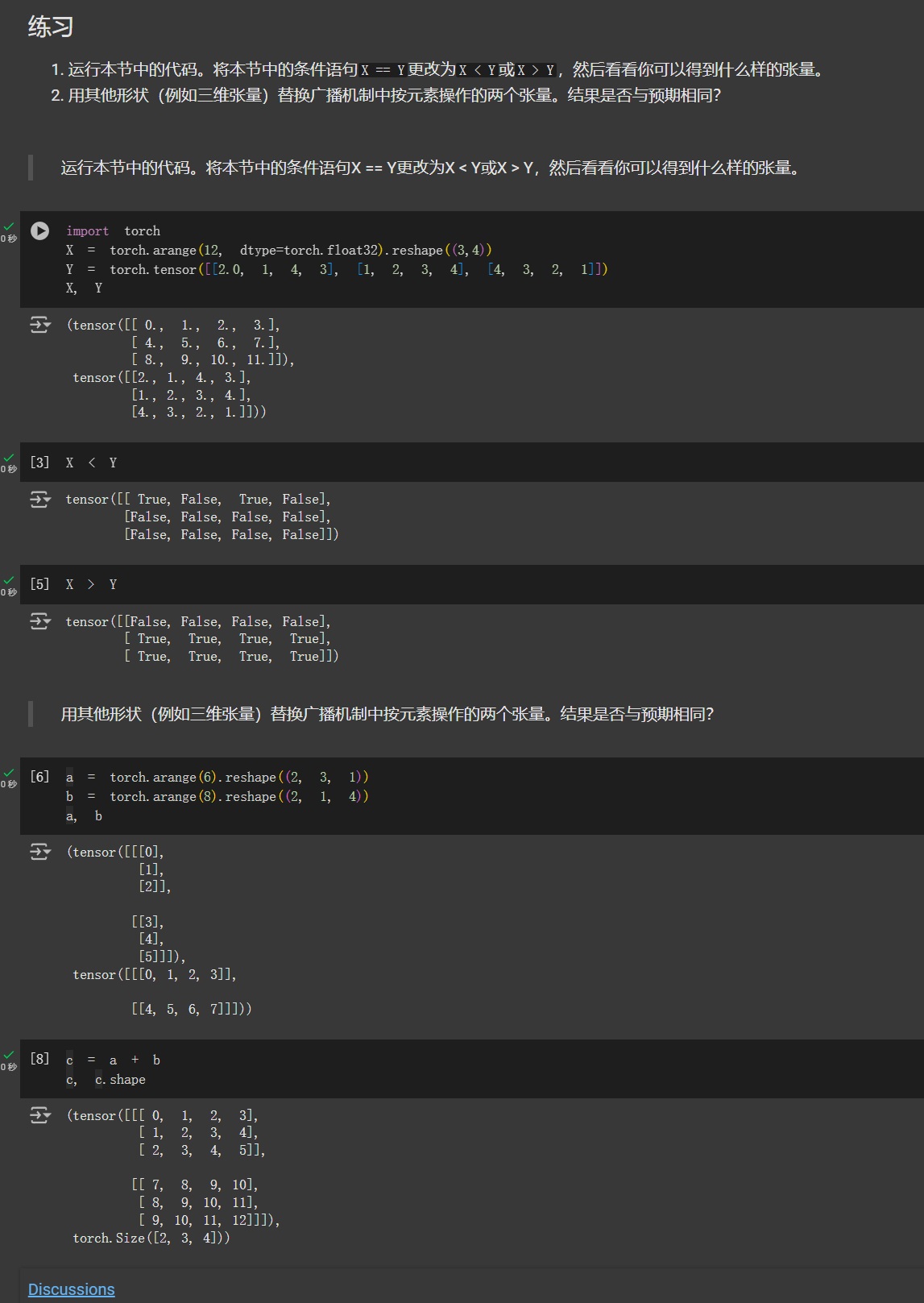
关于这节练习,我的答案:
1、
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(X )
print(Y)
print(X > Y)
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
tensor([[2., 1., 4., 3.],
[1., 2., 3., 4.],
[4., 3., 2., 1.]])
tensor([[False, False, False, False],
[ True, True, True, True],
[ True, True, True, True]])
2、
import torch
a = torch.arange(6).reshape((2, 3, 1))
b = torch.arange(4).reshape((2, 1, 2))
print(a+b)
a:tensor([[[0],
[1],
[2]],
[[3],
[4],
[5]]])
b:tensor([[[0, 1]],
[[2, 3]]])
a+b:tensor([[[0, 1],
[1, 2],
[2, 3]],
[[5, 6],
[6, 7],
[7, 8]]])
自动填充了行和列便于相加,广播机制要求从最后一个维度开始往前,每个维度的数字要不相等要不有一个为1才可以
id(obj)返回的是Python 对象本身的地址,不是obj的实际地址
print(X.data_ptr())
print(A.__array_interface__['data'][0])
查看实际内存地址是同一个