.numpy和.from_numpy方法是可以共享内存的,但如果使用torch.tensor(ndarray)由numpy数组生成tensor,就不会共享内存。
1 Like
有时我们想从某个概率分布中随机采样来得到张量中每个元素的值。例如,当我们构造数组来作为神经网络中的参数时,我们通常会随机初始化参数的值。以下代码创建一个形状为 (3, 4) 的张量。其中的每个元素都从均值为0、标准差为1的标准高斯(正态)分布中随机采样。
torch.randn(3, 4)
tensor([[ 2.1173, -0.3256, -0.9538, -0.6639], [ 0.3116, -0.2538, -0.8779, 0.1701], [ 0.8984, -0.1042, -0.7746, 0.3877]])
这里生成的是随机数据,不是正态数据
torch.randn returns a tensor filled with random numbers from a normal distribution with mean 0 and variance 1 (also called the standard normal distribution).
https://pytorch.org/docs/stable/generated/torch.randn.html?highlight=randn#torch.randn
兄弟别搞错了,标准正态分布,不是说数据只能在-1, 0,1之间,数据是有可能落到大于1,小于-1的地方的
2 Likes
然inplace 操作更加符合性能需求,python为何不直接默认了呢?而是搞出一些 X +=Y 和 Z[:] =X + Y 这样的需要甄别的骚操作?在大规模的计算过程中,将矩阵修改为原地操作会是提升性能的一个小trick吗?
默认还得了。。。。原地修改只是一种策略罢了,又不是所有操作都要求原地修改?语言层面的东西因为你一个计算就称为骚操作?
“首先,可以使用 arange 创建一个行向量 x 。这个行向量包含从0开始的前12个整数,它们被默认创建为浮点数。” 不是默认创建为64int吗?
1 Like
可能是作者疏忽了吧,其他创建张量方法一般都是float32,已经写习惯了。
应该是函数的重载吧,主要就是为了方便实用来的,你可以 help(torch.reshape)查看文档,和这个用法差不多
感谢你的回答,我再次总结了一下。看下面的代码
X = torch.tensor([1.0, 2, 4, 8])
print(id(X))
A = X.numpy()
print(id(A))
X.add_(1), A
输出
140487850431104 140487850554928 (tensor([2., 3., 5., 9.]), array([2., 3., 5., 9.], dtype=float32))
虽然,X和A的地址不一样,但共享内存更新X会改变A。而要把一个numpy转为tensor
a = numpy.ones(5),
方法一 b = torch.tensor(a) 相当于创建一个新tensor,不会共享内存
方法二 b = torch.from_numpy(a) 相当于从获取numpy中的值,会共享内存
故.numpy和from_numpy会共享内存,torch.tensor不会共享内存
4 Likes
2.1.6这一句话,确实没怎么懂,到底我们训练模型时,需要使用同一块内存,还是不使用同一块内存呢? 我理解的是相同的数据不使用同一块内存效率更高,不晓得对不对? 同一数据numpy中array格式转化为torch中tensor格式,内存地址确实变了的。
torch.reshape(input, shape)函数中两个参数的类型:
Args:
input (Tensor): the tensor to be reshaped
shape (tuple of ints): the new shape
shape是整数的元组,而元组可以写为(a,b)也可以写为a,b,并且input.reshape(shape)这种形式实际上调用的是torch.reshape(input,shape)。这样应该就可以理解了。

源码:def reshape(self, *shape: _int)。
*shape可以接收元组,也可分开接收。
2 Likes
使用 arange 创建一个行向量 x这里,其实创建的是一维向量吧?无关行向量还是列向量?(根据我查到的资料显示)
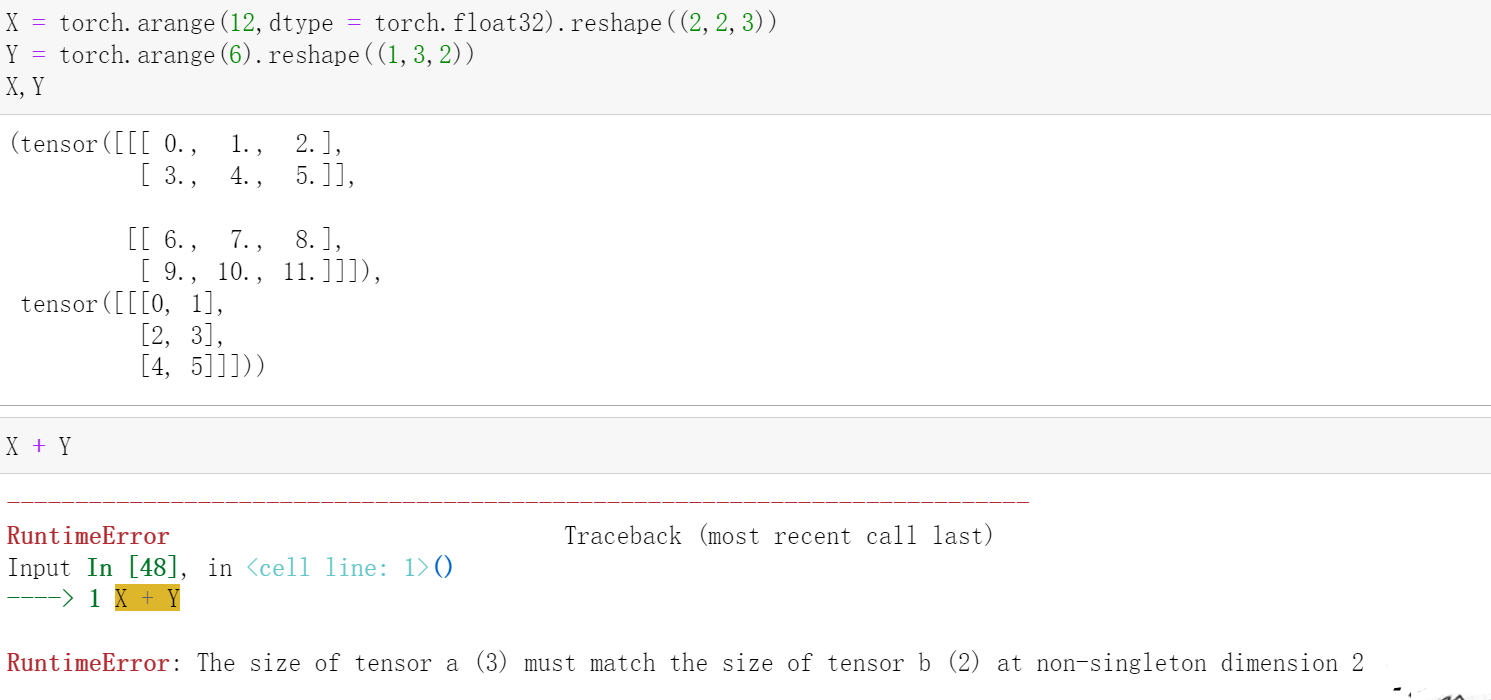
我猜测是因为3不能被2整除导致无法进行广播。如果你将X形状改变为(2,1,3),将Y形状改变为(1,3,1),那么应该可以顺利实现广播。
2 Likes
谢谢,是的,由于广播原则的限制,从直观上也可以理解,扩展的时候无法确定是按照2中的哪个元素复制,所以不可以进行。(原问题已解决)
我个人总结的广播原则:
维度按照右对齐后,需要复制的维度只有一行/列或者为空,其余行/列不需要复制。
这个可以复制成功,因为需要复制的维度全部是1
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a+b
可以复制成功,因为右对齐后第一个维度为空,且要复制的维度为1
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((2))
a+b
这个无法复制,因为要复制的有两列
a = torch.arange(18).reshape((3,6))
b = torch.arange(6).reshape((3,2))
a+b
这种可以复制,因为只有一行需要复制
a = torch.arange(18).reshape((3,6))
b = torch.arange(6).reshape((1,6))
a+b
这种不能复制,因为第一维需要复制的有两行
a = torch.arange(12).reshape((2,2,3))
b = torch.arange(12).reshape((6,2,1))
a+b
7 Likes