https://d2l.ai/chapter_natural-language-processing-pretraining/bert-dataset.html
In bert, replace the word with a random word instead of random number.
red line should be made:
vocab.to_tokens(random.randint(0, len(vocab) - 1))

1 Like

I agree. Contribute if you like.
https://d2l.ai/chapter_appendix-tools-for-deep-learning/contributing.html
@goldpiggy
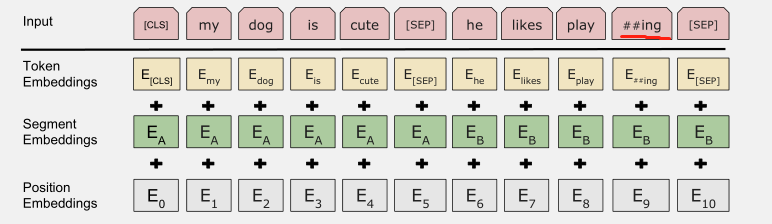



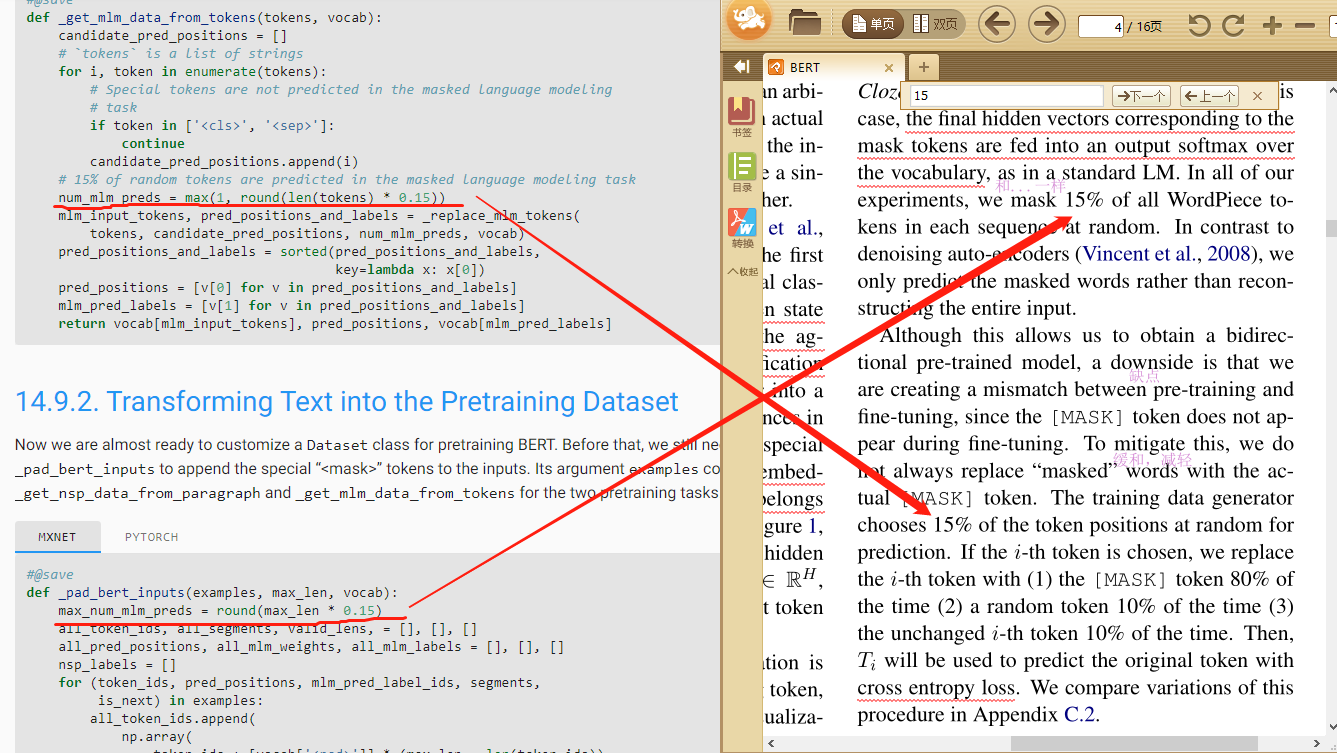
I saw your dataset in the attachment. I also need to build the customized dataset to pretrain for our model. But I don’t understand your way a lot. Could you tell me more detail or provide some sample explanation about your dataset? I’m fresh in this area.