http://d2l.ai/chapter_recurrent-neural-networks/text-preprocessing.html
Um, I dont think we have the right pip installs to run this section, the second cell (the first cell after the pip cells) did not work for me right off the bat, but I dont know exactly how I fixed it, I just took the pip’s from the last section and put em in and it ran. To hear about how you guys fixed and and why it works would also be helpful if youre willing 
Yeah, give me a sec.
Okay, so when I leave the code like this:
I get this:
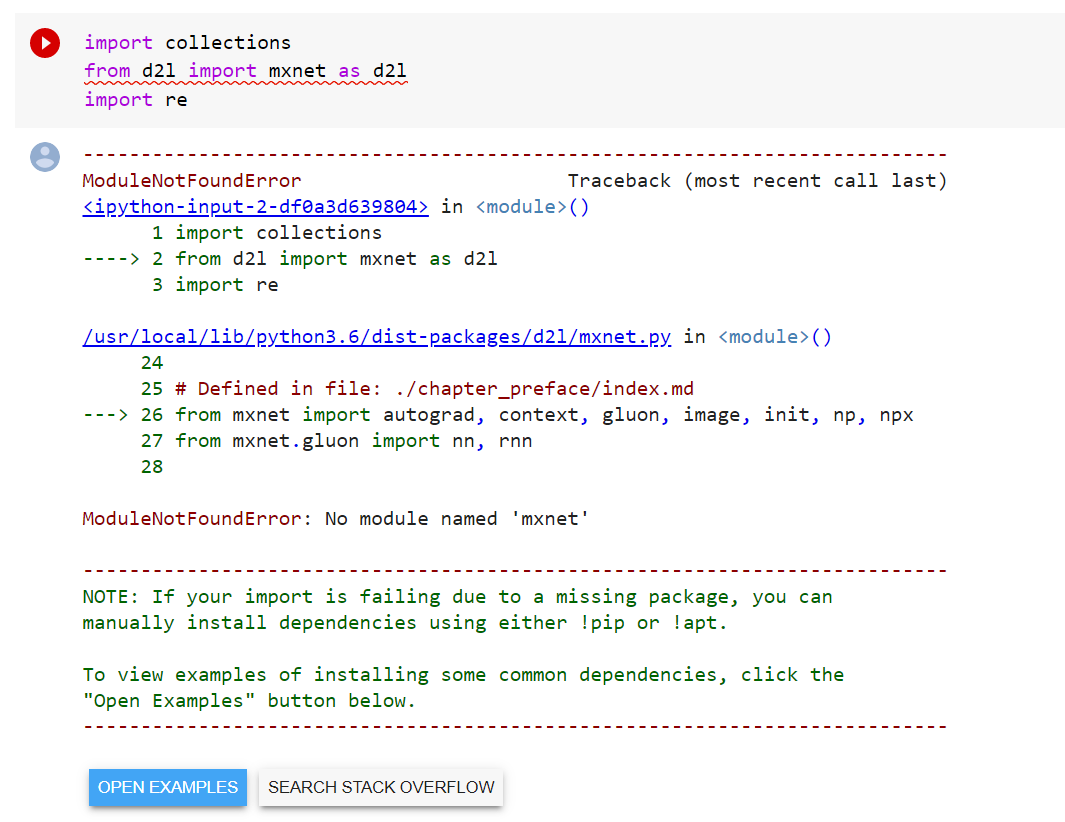
But when I copy this from 8.1:
BOOM, it works:
Hi @smizerex, please make sure your local d2l notebooks folder is up-to-date with our github. You can execute the following code on your terminal to rebase your d2l notebooks:
git fetch origin master
git rebase origin/master
 How could it have gotten out of sync in the first place?
How could it have gotten out of sync in the first place?
what the point of the first sorting?
# Sort according to frequencies
counter = count_corpus(tokens)
self.token_freqs = sorted(counter.items(), key=lambda x: x[0])
self.token_freqs.sort(key=lambda x: x[1], reverse=True)
I think the first sort is unnecessary. The sorting code can be simplified as
self.token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)
1 Like
Why tocken with frequency > min_freq is a unique token??
uniq_tokens += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in uniq_tokens]
I was wondering if we can use nltk package for this.
1 Like
- TreeBankWordTokenizer: It separates the word using spaces and punctuation.
- PunktWordTokenizer: It does not separate punctuation from the word
- WordPunktTokenizer: It separate punctuation from the word
- It decreased exponentially
1 Like
Exercises and my ill researched solutions
-
Tokenization is a key preprocessing step. It varies for different languages. Try to find another
three commonly used methods to tokenize text.Different Methods to Perform Tokenization in Python
Tokenization using Python split() Function
Tokenization using Regular Expressions
Tokenization using NLTK
Tokenization using Spacy
Tokenization using Keras
Tokenization using Gensim -
In the experiment of this section, tokenize text into words and vary the min_freq arguments
of the Vocab instance. How does this affect the vocabulary size?as min_freq increases vocabulary size decreases apparently.
However I agree with Akshays answer!
@fanbyprinciple
Most of those tokenizations you listed from popular packages just have their own custom regex. I think the point of the question was to come up with ways yourself, like, what if you split on all punctuation, or just all whitespace? Do you have to convert everything to lower? How does that affect words like Apple (company) & apple (fruit)?
min_freq increases vocabulary size decreases apparently.
You can see this directly in their code
for token, freq in self._token_freqs:
if freq < min_freq: # ignore the token
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
I re-wrote the section so you can see this clearer
def prune_tokens(self, list_tokens, minimum_frequency = 0):
"""
Assigns the corpus to the remaining tokens (preserving order)
Sorts the frequency dictionary in descending order.
If you're smaller than the minimum frequency,
then the rest that follow must be too.
"""
counter = collections.Counter(list_tokens)
set_tokens_frequent = set()
for token, frequency in sorted(counter.items(), key=operator.itemgetter(1), reverse=True):
if frequency < minimum_frequency:
break
set_tokens_frequent.add(token)
self.corpus = [token for token in list_tokens if token in set_tokens_frequent]
1 Like
Thanks for explaining the semantic difference