in the training function above, why do we need to sum the loss before we do the backward?
l.sum().backward() # Make the loss scalar for backward`
Also, why do we do the clipping?
d2l.grad_clipping(model, 1)
another observation, it wasn’t clear to me why we effectively throw out the output of the encoder, we just use the state to initialize the decoder. What’s the intuition for this?
Hi @swg104, the backward() is applied on the final loss, see more details in the backpropagation section.
Section 8.5 talked about why. ![]()
why do we need to eval() when we test the s2sencoder or s2sdecoder?
but at predict stage there is no such opearation.
PyTorch has two modes, eval and train. eval mode should be used during inference. eval mode will disable dropout (and do the appropriate scaling of the weights), also it will make batch norm work on the averages computed during training. Btw predict_seq2seq has net.eval, you can check the preview version. This fix should be reflected in the next release.
In predict_seq2seq()
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
Here dec_state is recursively returned from and used by the net.decoder.
I feel this doesn’t match the Fig. 9.7.3 where all the dec_X is concatenate with the last encoder state.
In other word, the dec_state should alway be kept as the same as the code below does.
Y, _ = net.decoder(dec_X, dec_state)
But, the new code makes a problem that in net.decoder, dec_state is also used to init the state for next timestep. Therefore, in current framework, maybe the original code could be the best solution. Or we could need to adjust the code of class Seq2SeqDecoder(d2l.Decoder)?
Please help to point out if I am right.
Thanks!
@shaoming_xu Hi! I think you are right – the code looks buggy. One way to fix this is to pass two state variables, enc_state as additional context and dec_state as the decoder’s hidden state, into the decoder during forward propagation, and return only dec_state along with output as enc_state is only copied but not processed:
class Seq2SeqDecoder(Decoder):
...
def forward(self, X, enc_state, dec_state):
X = self.embedding(X).permute(1, 0, 2)
# `enc_state` as additional context
context = enc_state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
# `dec_state` as the hidden state of the decoder
output, dec_state = self.rnn(X_and_context, dec_state)
output = self.dense(output).permute(1, 0, 2)
return output, dec_state
class EncoderDecoder(nn.Module):
...
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state, dec_state)
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
...
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
enc_state = dec_state.clone().detach()
...
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, enc_state, dec_state)
...
Did you and @shaoming_xu notice the Ecoder’s state is used and then returned by the Decoder’s init_state method?
9.6.3. Putting the Encoder and Decoder Together
class EncoderDecoder(nn.Module):
"""The base class for the encoder-decoder architecture."""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
9.7.2. Decoder
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
...
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
...
Anyone have ideas on Question 6? (Other output-layer design ideas).
Hi,
I am not understand why there is no opt.zero_grad() after the opt.step() call? My understanding is the grad will accumulate if no zero_grad() called.
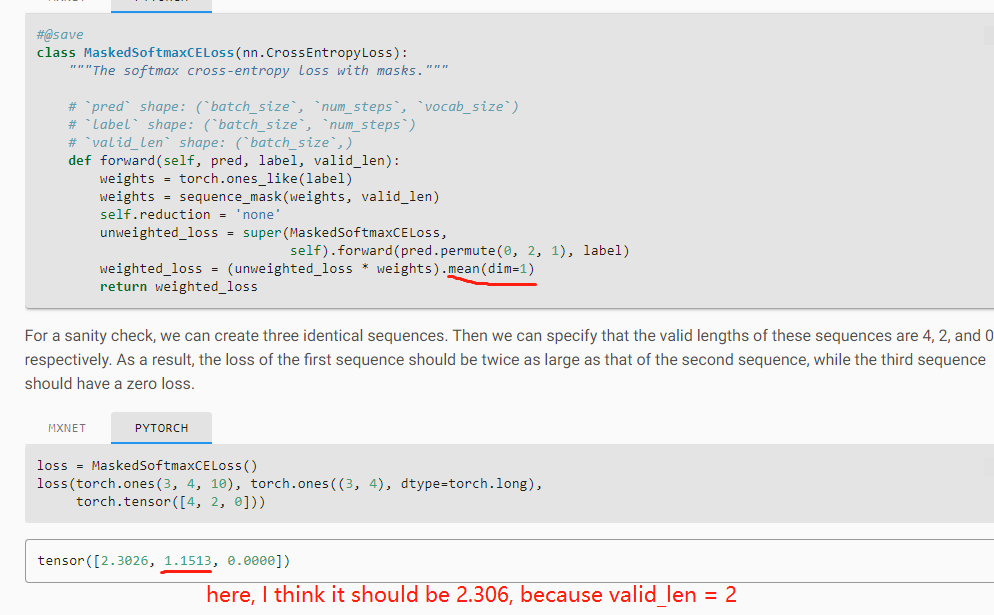
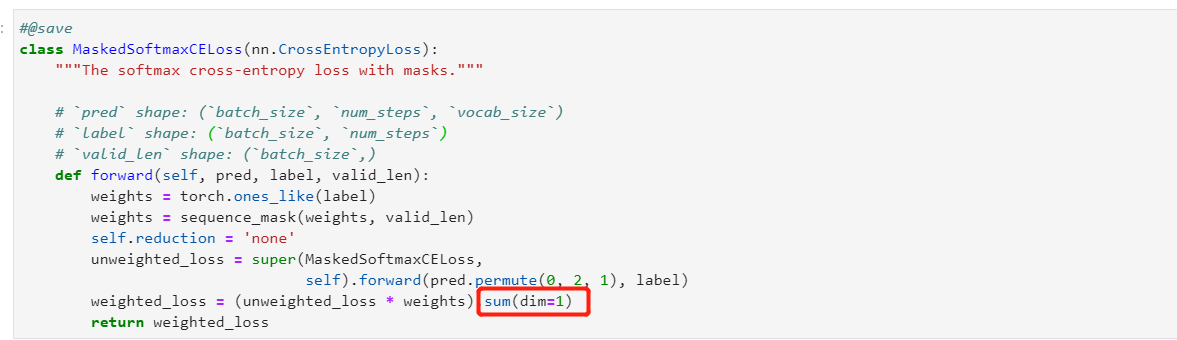


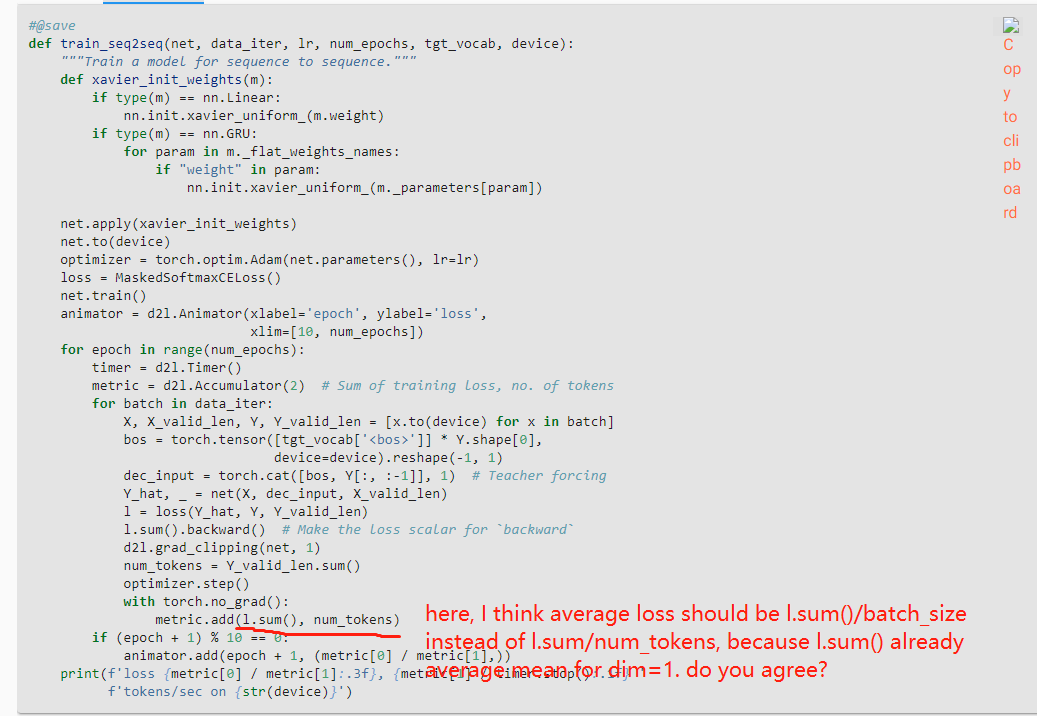
thank you for your reply!
in my opion:

l.sum() is all the loss of batch_size*vaild_len. num_tokens is all the tokens of the batch_size too. so i think wo don’t need to /batch_size. this is my opinion. thank you!
enc_outputs = net.encoder(enc_X, enc_valid_len)
how enc_valid_len is used in encoder forward method?
here i don’t see how enc_valid_len is used in the forward method of Seq2SeqEncoder class
Blockquote
def forward(self, X, *args):
# The output `X` shape: (`batch_size`, `num_steps`, `embed_size`)
X = self.embedding(X)
# In RNN models, the first axis corresponds to time steps
X = X.permute(1, 0, 2)
# When state is not mentioned, it defaults to zeros
output, state = self.rnn(X)
# `output` shape: (`num_steps`, `batch_size`, `num_hiddens`)
# `state` shape: (`num_layers`, `batch_size`, `num_hiddens`)
return output, state
Blockquote
me neither. What’s more, in function predict_seq2seq, the enc_valid_len is not used, either.
I think I figured out this mysterious enc_valid_len. In chapter 10 Attention Mechanisms, the seq2seq function is reused, where, the enc_valid_len is used for masked operation.
I think that @ sanjaradylov and shaoming_xu are referring to how the contect variable “c” is implemented in the predict_seq2seq() function.
From Fig 7.9.1, the context variable “c” is the last hidden state from the encoder, which should remain unchanged during the iterations of decoder steps. However, the current implementation of predict_seq2seq() recursively uses the dec_state:
Y, dec_state = net.decoder(dec_X, dec_state)
This is incorrect, at least according to the design.
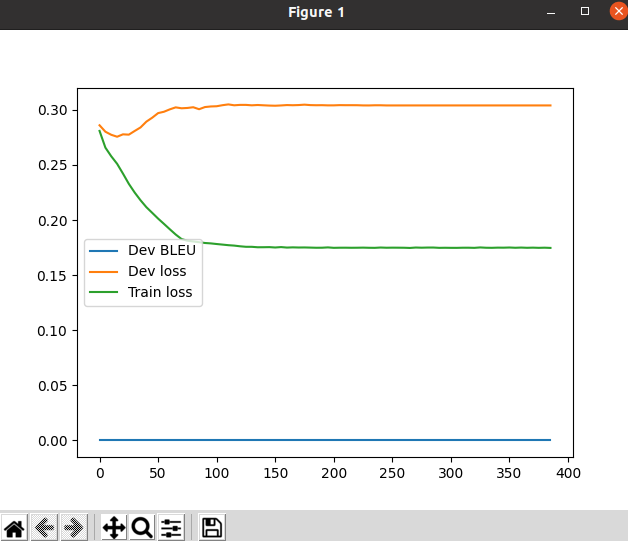
Hi! Has someone been able to make this encoder-decoder get good results? I’ve implemented the mentioned code, improved it (e.g. lr scheduler, different aproaches like remove the concatenated context in the inputs of the decoder), try different parameters, etc. and it’s still not getting good results… It is overfitting using 1000, 10000 and 100000 sentences… I have tried to make a smaller model but still is overfitting. I’m trying to translate from spanish to english with Tatoeba corpus from Opus