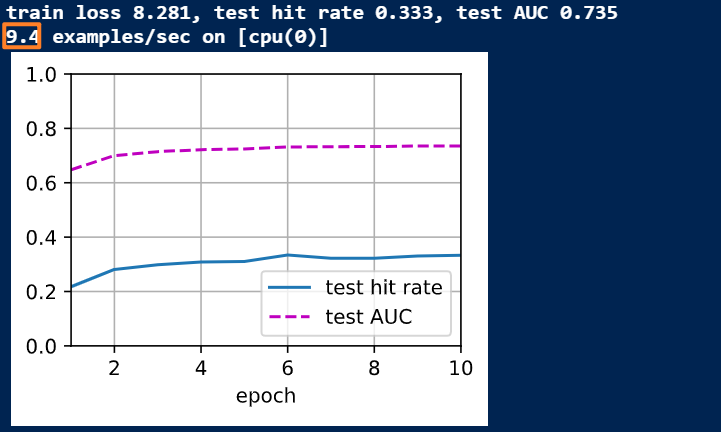

Your examples/second is small because you are running this on CPU, not GPU. Try running it in Google Colab if you do not have access to a GPU. Also, that value is not really indicative of examples per epoch but rather it is the speed at which examples are training the model and that is why it won’t significantly effect your final AUC and hit-rate results.

Hi, The paper didn’t say the W’ in the output layer come from another embedding matrix. It is a purely fully connected layer in the paper. However, in this chapter, the v’ in the output layers comes from embedding matrix? could you elaborate that? many thanks!
Hi, thanks for the tutorial!
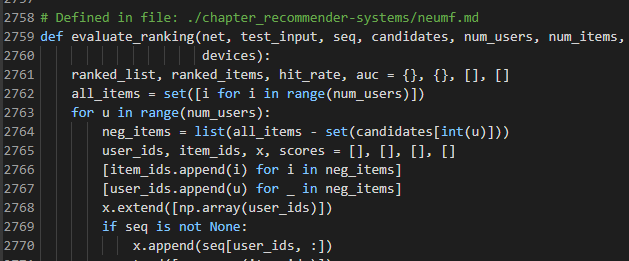
I think there is a typo in line 2762, it should be all_items = set([i for i in range(num_items)]) not all_items = set([i for i in range(num_users)])
In my opinion, the function of the embedding matrix and fully connected layer is exactly the same. The purpose of using the embedding matrix here is likely to cut down the computing complexity. Since when we use an embedding matrix, we can retrieve the embedding of a specific item conveniently. In this way, we can avoid calculating the result of linear layer for every item.
Hi. As far as I understand, the author of this tutorial compared the W’ in the paper to the item embedding matrix V in the tutorial. Because y(u,t) = W’ [z, pu] T+ b’ is similar to the dot product of item vector and user vector with an additional bias term. But the matrix V in this tutorial, which is self.Q_prime in model implementation code, is not a fixed embedding matrix but a model parameter. The value of each element in self.Q_prime is learned in the training process just as the paper indicated.