I never understood why the original paper uses the following notation:

What exactly are the Q, K, V matrices? I have found in some articles “explaining” the paper that these three Q,K,V are actually the same input matrices. But then wouldn’t they just mention it as such in the original paper?
Suppose that the input representation X \in \mathbb{R}^{n \times d} contains the d-dimensional embeddings for n tokens of a sequence.
The output of a self-attention layer is still a matrix X' \in \mathbb{R}^{n \times d'}. I see that the order is still maintained and is given by the row number in X and X'. Then why do we say that the word order is not preserved in self-attention?
I am surely missing something, so I need some help. Thanks!
Hey @sprajagopal, great question! First just for clarification, Q,K and V don’t need to be the same. They might be the same in some specific model or specific task, we most of the time, at least the Q (query) is different to K (key) and V (value). For example, in BERT, query represents the bidirectional context, while key/value is the token itself.
I understand it is confusing at first, but after reading more original paper such as BERT, GPT3, you will get a more universal view on transformer and attention applications! Good luck!
Hi @Sebastian_Ciobanu, I may not fully understand your question, could you point out the specific example/location at the book? (Just a side note, transpose_qkv in 10.5 may help!)
Thanks for your answer, @goldpiggy!
10.6.3. Positional Encoding
Unlike RNNs that recurrently process tokens of a sequence one by one, self-attention ditches sequential operations in favor of parallel computation. To use the sequence order information, we can inject absolute or relative positional information by adding positional encoding to the input representations. Positional encodings can be either learned or fixed. In the following, we describe a fixed positional encoding based on sine and cosine functions [Vaswani et al., 2017].
Suppose that the input representation X \in \mathbb{R}^{n \times d} contains the d-dimensional embeddings for n tokens of a sequence.
I think that the authors suggest that self-attention does not take into consideration word order in a sequence. I also found this idea expressed on the Web:
Transformer Architecture: The Positional Encoding
As each word in a sentence simultaneously flows through the Transformer’s encoder/decoder stack, The model itself doesn’t have any sense of position/order for each word. Consequently, there’s still the need for a way to incorporate the order of the words into our model.
The problem is that I do not understand why self-attention does not take into consideration the word order, since its input sequence is X \in \mathbb{R}^{n \times d} and the output sequence is X’ \in \mathbb{R}^{n \times d’}, where the rows are ORDERED: the first row in X corresponds to the first row in X’, the second row in X corresponds to the second row in X’ etc., so the first row in X’ is the first word in the output sequence, the second row in X’ is the second row in the output sequence etc.
Hey @Sebastian_Ciobanu, I understand your question now! Yeah, if we just take a look of attention itself, we can somehow figure out the sequential information by counting. However, if we put attention in its application (e.g. put attention in the transformer architecture), attention doesn’t “send” sequential information to the next layer (e.g. in transformer, the “add&norm” layer will lose the sequential information).
The above reference you found are both trying to introduce “positional encoding”'s function, so don’t pay too much attention on them.
Yet another question raised concerning the position encoding when I print P:
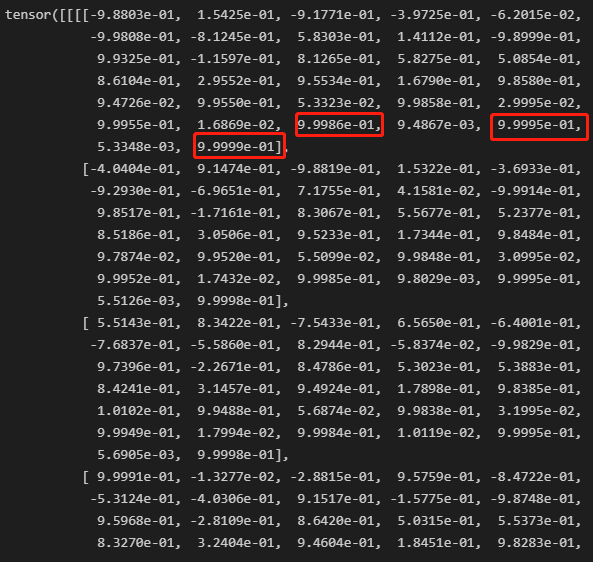
For the 1st token, while each position has unique value, some are very close (red boxes) than others. So the euclidean distances among these 3 position are much smaller than among others.
I am wondering if it poses problems to what position encoding intents, and bias weights towards some specific position than others.
Hi All,
It might be a difference in versioning, but the mxnet positional encoding function breaks when the the P tensor’s third axis dimension is odd. When P.shape[2] is odd, X and P will no longer align. You will need to implement some conditional indexing on X to get the tensor into the right shape.
Completely understand if you are going for minimal code for pedagogical reasons. I just wanted to flag a potential sticking point for more general applications.
Best,
Jimmy
I reply to this old conversation because this response perturbs my understanding of the positional encoding in self-attention and I wish someone corrects me.
I think that self-attention ( without positional encoding) really doesn’t take into consideration the position information.In RNN network, the position of the embedding vector in the seq affects the final output, but in attention operations, the matrices multiplication between queries and keys don’t change depending on the position of the queries vector , hence the need to add a positional encoding.
I think you are right.
a couple concepts should be noticed:
a. ‘position’ should be the context info streamed one by one , but not the vanilla index ,eg. rows number
b. this is the common feature of all attention but not ‘self-attention’ only
c. last, the root cause is the ‘bmm’ which run parallely w/o context info
some questions are still there ,please give some clues:
a. “encode sequences” described in top, does it mean “feature extraction or say do like ‘encoder’”
b. how to derive the complexity of CNN here
c. why the complexity of RNN here consider only the hidden item in formula(9.4. Recurrent Neural Networks — Dive into Deep Learning 1.0.3 documentation) but no input item, and output item
d. does the binary encoding frequency correspond to the positional encoding’s one, and why?