https://d2l.ai/chapter_natural-language-processing-pretraining/bert-pretraining.html
Hi,
I am wondering if there is an error in Pytorch´s _get_batch_loss_bert():
mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) * mlm_weights_X.reshape(-1, 1)
mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)
Before, it was defined loss = nn.CrossEntropyLoss(), so it adopts the default reduction=‘mean’. But my impression is that we should use reduction=None instead, in order to average it based on the variable num of real tokens (mlm_weights_X.sum()) and not the real tokens + pad tokens as it currently seems to be doing?
In terms of dimensionality: mlm_Y_hat = {n,tau,v}, mlm_Y={n,tau} and mlm_weights_X={n,tau}. Currently loss(mlm_Y_hat…) seems to yield a scalar, which is then multiplied by mlm_weights_X.reshape(-1, 1) of dim {n·tau} which gives a vector of dim {n·tau}. In the 2nd line it is then sumed up and divided by the num of non-zero components in mlm_weights_X, effectively giving back the original scalar loss(mlm_Y_hat…) which is an average over the real and pad tokens.
I think if for MLM it had been defined loss = nn.CrossEntropyLoss(reduction=None), then loss(mlm_Y_hat…) would yield a tensor of dim {n·tau} which multiplied by mlm_weights_X.reshape(-1, 1) of dim {n·tau} would give a vector of dim {n·tau}. The 2nd line would then sum it up and divide it by the num of real tokens, without the pad tokens affecting the average.
1 Like
I agree. The CrossEntropyLoss object should have been instantiated with the parameter reduction specified as none. Otherwise it will average the loss over both valid and invalid (padded) tokens. The correct instantiation statement is
loss = nn.CrossEntropyLoss(reduction='none')
Also the code filtering out losses for padding tokens
mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) *\
mlm_weights_X.reshape(-1, 1)
should be changed to
mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) *\
mlm_weights_X.reshape(-1)
After this (revised) line of code has been executed, mlm_l would have shape of (5120,) (here, batch size=512, maximum number of masked tokens=10, 512 times 10 = 5120)
2 Likes
Hello, I used this method to pretrain a BERT model on a humungous DNA corpus. The “problem” is that it is finishing pertaining in just 15 minutes for the entire dataset whereas a BERT from scratch would take at least a few days (along with the processing capabilities). Could someone let me know why this is happening and if the model is learning or not?
I agree with you, the original code will output the same loss as loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)).
I’ve revised those to the below:
loss = nn.CrossEntropyLoss(reduction=‘none’)
mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1))*mlm_weights_X.reshape(-1)
nsp_l = loss(nsp_Y_hat, nsp_y).mean()
In that case, I’ve got the result of :
accumulation of mlm loss for 50 steps: 366.18415546417236
accumulation of nsp loss for 50 steps: 37.543556928634644
MLM loss 7.324, NSP loss 0.751
5099.7 sentence pairs/sec on [device(type=‘cuda’, index=0)]
Both accumulated losses were increased by 84.5 and 0.2 respectively.
I am wondering if it is all good.
batch_size, max_len = 512, 64
train_iter, vocab = d2l.load_data_wiki(batch_size, max_len)
When I try to execute the above cell, I get the error message as “BadZipFile: File is not a zip file.” I tried to access the raw URL of Wikitext2 by typing this URL “https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip” directly on the brower, but it shows a message written as “access denied.” Is there anyone who can check issue?? I’m curious whether the URL is temporarily having access troubles, or it’s been permanently closed.
I would appreciate any of your helps. Thanks!
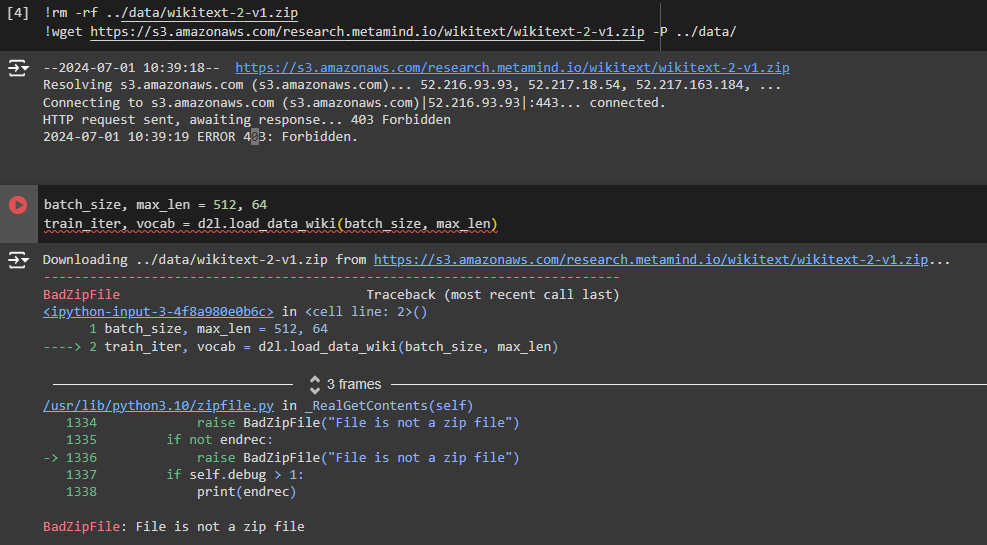
Here we have the problem with downloading the dataset and can’t run the system! Please fix it for me. Thank you!
sure ,that’s a misused case on ‘scalar * vector’ to result in fake vector with same shape