https://d2l.ai/chapter_natural-language-processing-applications/natural-language-inference-bert.html
It is saying " These two loss functions are irrelevant to fine-tuning downstream applications, thus the parameters of the employed MLPs in MaskLM and NextSentencePred are not updated (staled) when BERT is fine-tuned."
How to achieve it? could you please share some sample code for this trick?
The model it used didn’t include the mlp layers for MLM and NSP.
Btw, if you want to “frozen” any layer, you can set the parameter requires_grad to False, it’s more like a “transfer learning”, like this:
class BERTClassifier(nn.Module):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
for param in self.encoder.parameters():
param.requires_grad = False
self.hidden = bert.hidden
for param in self.hidden.parameters():
param.requires_grad = False
self.output = nn.LazyLinear(3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_x = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)
return self.output(self.hidden(encoded_X[:, 0, :]))
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model(
‘bert.small’, num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_blks=2, dropout=0.1, max_len=512, devices=devices) TypeError Traceback (most recent call last)
/tmp/ipykernel_7860/847789108.py in
2 bert, vocab = load_pretrained_model(
3 ‘bert.small’, num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
----> 4 num_blks=2, dropout=0.1, max_len=512, devices=devices)
/tmp/ipykernel_7860/325226183.py in load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens, num_heads, num_blks, dropout, max_len, devices)
9 bert = d2l.BERTModel(
10 len(vocab), num_hiddens, ffn_num_hiddens=ffn_num_hiddens, num_heads=4,
—> 11 num_blks=2, dropout=0.2, max_len=max_len)
12 # Load pretrained BERT parameters
13 bert.load_state_dict(torch.load(os.path.join(data_dir,
TypeError: init() got an unexpected keyword argument ‘num_blks’
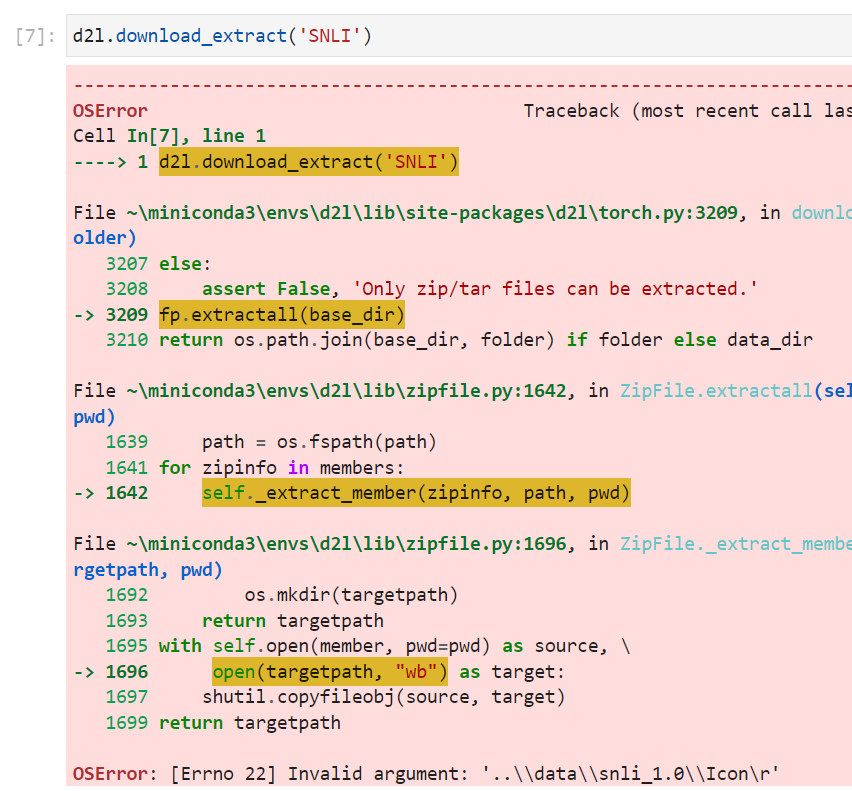
You can manually decompress the SNLI compressed package in the data folder after downloading it.
make sense. actually there are two components not used. so I think both will not be updated automatically, if any you can disable them manually .
certain questions:
- In last section “pertaining bert”, it used continuous sentences-pair in “wikitext-2” to do train model, while here uses NLI sentences pair(may be not continuous ) to do finetune, does it fit for both cases?