https://d2l.ai/chapter_computer-vision/multiscale-object-detection.html
There are some question I want to ask, please be patient with me.
-
" Since the midpoints of anchor boxes
anchorsoverlap with all the units on feature mapfmap". The overlap happened because the anchor boxes is centered in each pixel, is it right? -
As we know, an element in a deeper layer has more receptive field of the input image than an element in a shallow layer, hence it has a larger size of receptive field of the input image. But in the context of feature map, the small feature map corresponding to wider object while the large feature map corresponding to narrower object, is it right?
Because I saw in Section 13.5, the larger feature map fmap_h=4=fmap_w corresponding to narrower object while the smaller feature map fmap_h=2=fmap_w corresponding to wider object.
In Short, why wider object has smaller fmap than narrower object? Is it because the nature of crosscorr operation? so deeper layer has possibility to output smaller fmap than shallow layer.
I am sorry to ask so many question, but I can’t go to the next section without getting crystal clear in this section. Thank you.
Hi @rezahabibi96, great questions!
Yes the image are divided by fmap into cells uniformly, and the anchor boxes are centered at each cells.
“wider receptive field” refers to a larger convolutional filter, used for larger objects. Let me know if it makes sense to you.
2 Likes
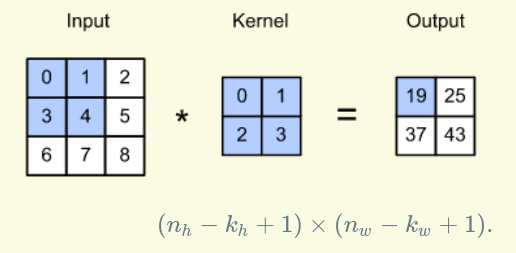
For example, input image has 3x3 shape, kernel 2x2 and feature map output has 2x2 shape.
When feature map size decreases, kernel size increases which leads to a larger size of receptive field of the input image. Correct me if i 'm wrong.
p/s: sorry for my bad english ![]()
1 Like
Are “wider” and “larger” referring to two different things? From what I understand, deeper layers of CNN have larger receptive fields because they consider/aggregate the “bunched up”-earlier layers. So even if we use a Resnet that has constant 3x3 filters throughout, we still achieve the effect of having larger receptive fields as we go deeper in the network. Is this correct?