https://d2l.ai/chapter_recurrent-modern/machine-translation-and-dataset.html
In preprocess_nmt, should we remove question mark ‘?’ ?
Hi @Songlin_Zheng, great catch! We will make the improvement with the “?” on both mxnet and torch version.
when running this cell:
#@save
d2l.DATA_HUB[‘fra-eng’] = (d2l.DATA_URL + ‘fra-eng.zip’,
‘94646ad1522d915e7b0f9296181140edcf86a4f5’)
#@save
def read_data_nmt():
“”“Load the English-French dataset.”""
data_dir = d2l.download_extract(‘fra-eng’)
with open(os.path.join(data_dir, ‘fra.txt’), ‘r’) as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])
the following error occured:
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xaf in position 33: illegal multibyte sequence
I fixed this by modify this line:
with open(os.path.join(data_dir, ‘fra.txt’), ‘r’) as f:
to:
with open(os.path.join(data_dir, ‘fra.txt’), ‘r’, encoding = ‘utf-8’) as f:
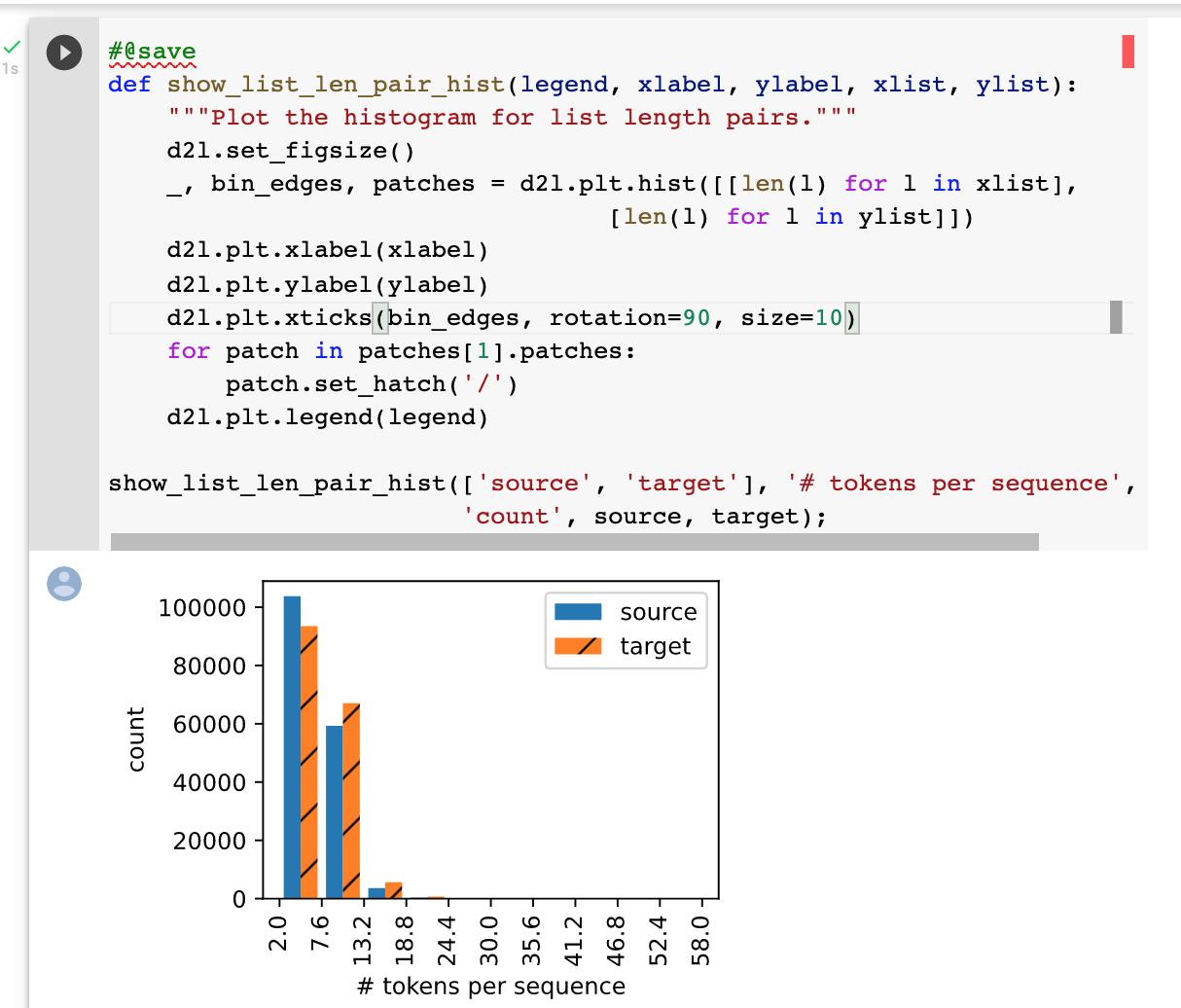
Who can explain “the histogram of the number of tokens per text sequence” to me?
I didn’t understand how the picture was drawn.
I think truncate_pad() should add ‘eos’ when truncate is performed:
def truncate_pad(line, num_steps, padding_token, eos_token):
if len(line) > num_steps:
return line[:num_steps-1] + [eos_token]
return line + [padding_token] * (num_steps - len(line))
otherwise Truncate_pad() may delete ‘eos’.
Perhaps with the tick labels shown on the x-axis it will be clearer… By default there are 10 bins for each bar type. So from the first blue vertical bar and the first orange hatched bar we can see that in the source language (English), there are over 100000 text sequences having between 2 and 7.6 tokens in each of the >100000 text sequences; while in the target language (French), there are between 80000 and 100000 text sequences having 2–7.6 tokens in each of these 80000–100000 sequences.
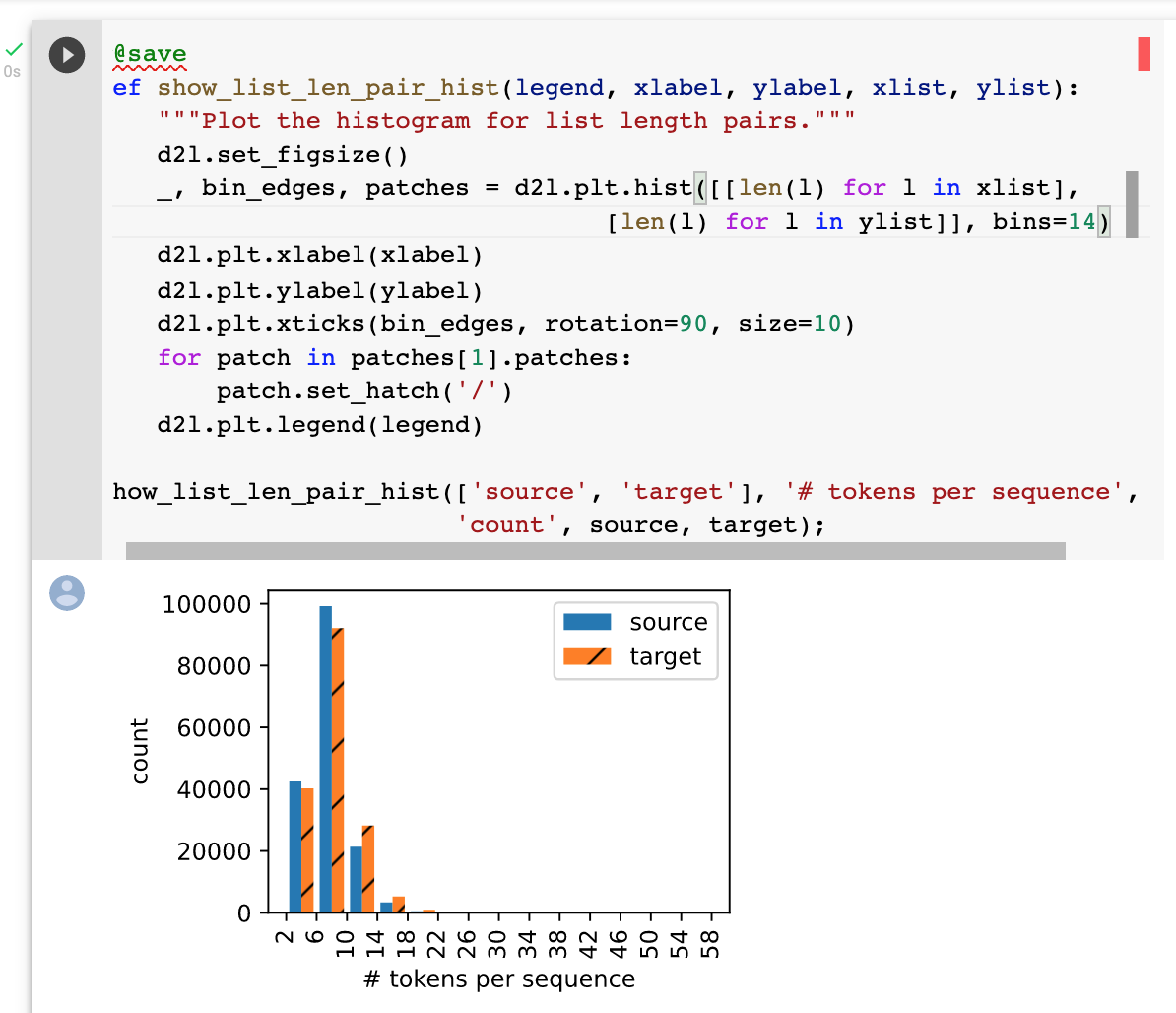
The top picture shows the default number of bins (10) and the picture below shows when there are 14 bins allocated to each bar type.
if you are using windows, you might find the representation of French characters have a numerous amount of letters coming out which you never see it in the French alphabet, this is because your computer is decoding it in the wrong way, you there for might want to fix it to the correct way so the representation will be readable for French speakers, the easiest way to do that is explicitly point out the format ‘utf-8’ in the code. this problem have already been fixed in the Chinese site of this book, here is the link
https://zh.d2l.ai/chapter_recurrent-modern/machine-translation-and-dataset.html
this problem have already been fixed in the code in GitHub, but i don’t know why it haven’t be deployed to this site