https://d2l.ai/chapter_linear-classification/image-classification-dataset.html
I have tested that num_workers parameter in torch DataLoader does work. By selecting num_workers=4 reduce the read time to half.
- batch size = 1, stochastic gradient descent (SGD)
batch size = 256, mini-batch gradient descent (MBGD)
Because using GPU to parallel read data, so MBGD is quicker.
Reducing thebatch_sizewill make overall read performance slower.
 Does my guess right?
Does my guess right?
- I’m a Windows user. Try it next time!
- https://pytorch.org/docs/stable/torchvision/datasets.html
Datasets:
I suggest using %%timeit -r1, which is a built-in function in Jupyter, instead of the d2l timer.
%%time is better. One time is enough 
1 Like
Hi friends,
I dont understand resize argument.
I cant show images after resize.

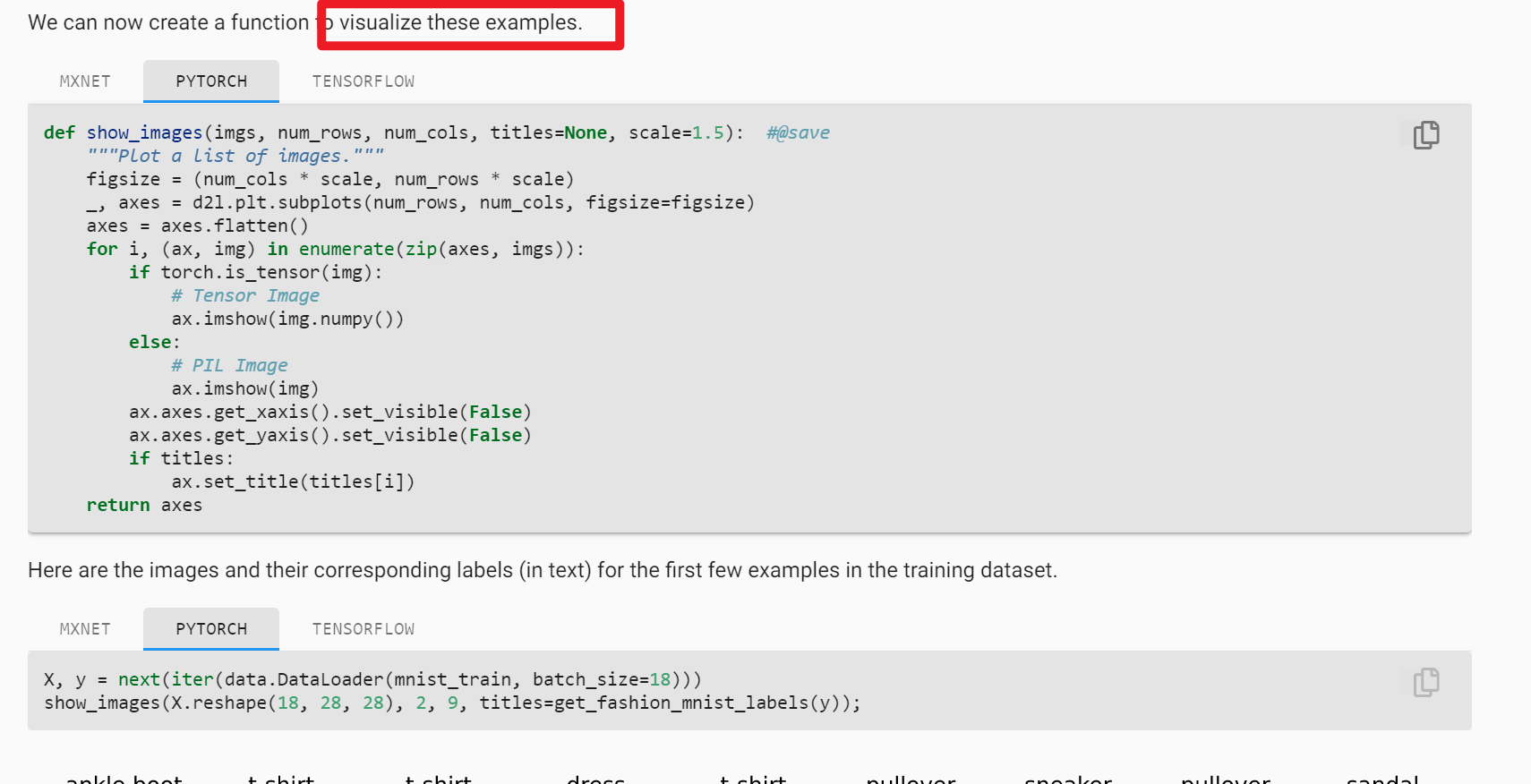
@StevenJokess you need to change the arguments when calling show_images() method according to your chosen batch_size and resize arguments in load_data_fashion_mnist() method
something like this
show_images(X.reshape(32, 64, 64), 2, 9, scale=1.5, titles=get_fashion_mnist_labels(y))
For q1, I don’t think SGD or MSGD would affect the performance of reading dataset, since it has nothing to do with updating params.
However it’s really slower when batch_size is set to 1 to read data. May the I/O limitation of data reading is the reason of difference?

In PyTorch, when loading the dataset, there is a warning. I find I can’t use the dataset.
when running “mnist_train[0][0].shape” would give an error:
TypeError: array() takes 1 positional argument but 2 were given
How to solve this?:
应该是接口变了吧
参考https://blog.csdn.net/weixin_42468475/article/details/108714940
X, y = next(iter(data.DataLoader(data.TensorDataset(mnist_train.data, mnist_train.targets), batch_size=18)))num_workers=get_dataloader_workers()
What does the num_workers mean here? Does it use CPU or GPU. I got a Runtime Error after setting num_workers >0, i.e. 4. No problem with num_workers = 0
RuntimeError: DataLoader worker (pid 30141) exited unexpectedly with exit code
Question 1 is about the efficiency of loading data, so it may be better to explain from the computer system instead of something like’min-batch SGD’ or’SGD’. In fact, mini-batch SGD is mainly used to accelerate the training process in parallel in the GPU. (If you have a lot of TPUs, you can even use batch_size = 1 in all data sets)
The following is my brief explanation, it is based on some assumptions, because I’m not familiar with the architecture of Nvidia GPU or TPU
Assuming that the I/O process used by the code only includes “interrupt”, “DMA” and “channel”, and there are some buffers for temporary storage.
However, when the buffer is full, any of the above methods must handle “interrupt processing”. Processing transfers control from DMA/channel to CPU/GPU/TPU, so I/O is suspended. Setting batch_size smaller will increase the number of hangs, so reducing I/O efficiency.
For more information about I/O, these might be useful
- Computer architecture, a quantitative method
- Computer Organization and Design, The Hardware and Software Interface
- CUDA Programming: A Developer’s Guide to Parallel Computing Using GPU
I got the same problem here. Did you figure out why this would happen?
Here are my opinions about the exs:
ex.1
If I change the batch_size to 1, then it becomes much more time-consuming(‘105.35 sec’), compared to set batch_size to 64(‘5.70 sec’).
data = FashionMNIST(resize=(32, 32), batch_size = 1)
len(data.train), len(data.val)
data.train[0][0].shape
tic = time.time()
for X, y in data.train_dataloader():
continue
f'{time.time() - tic:.2f} sec'
ex.2
I think the performance depends on the hardware I’m using, like memory size, cpu type, gpu memory size…
ex.3
Pytorch official
Or using the code bellow to get a brief introduction.
??torchvision.datasets
And I got a problem here, I iter through the validation set twice, and got same images, why??? ![]()
(ps: it works well on training set)
@d2l.add_to_class(FashionMNIST) #@save
def visualize(self, batch, nrows=1, ncols=8, labels=[]):
X, y = batch
if not labels:
labels = self.text_labels(y)
d2l.show_images(X.squeeze(1), nrows, ncols, titles=labels)
batch = next(iter(data.val_dataloader()))
data.visualize(batch)
batch = next(iter(data.val_dataloader()))
data.visualize(batch)
If you utilize the windows platform, maybe change the
def get_dataloader_workers(): #@save
return 0 #instead of 4
then it’s ok to run
X.squeeze(1)
why do we do this
AttributeError Traceback (most recent call last)
Cell In[8], line 1
----> 1 class FashionMNIST(d2l.DataModule): #@save
2 “”“The Fashion-MNIST dataset.”“”
3 def init(self, batch_size=64, resize=(28, 28)):
AttributeError: module ‘d2l.torch’ has no attribute ‘DataModule’
Anyone has the same error?