I didn’t use nvidia.So I didn’t install GPU version and cuda.
torch.cuda.device('cuda')
AssertionError : Torch not compiled with CUDA enabled
torch.cuda.device_count()
0
Why didn’t AssertionError happen when I run the following code?
torch.cuda.device('cuda:1')
<torch.cuda.device at 0x16349fb2488>
5.6.5. Exercises
- you should see almost linear scaling? I’m confused what is linear scaling.
‘Linear scaling’ is that the computation speed is proportional to the number of GPUs you use.
e.g., With one GPU, two tasks take 2 sec, and with two GPUs, two tasks (each on one GPU) takes only 1 sec.
I am confused about most of the questions here
Exercises and my silly answers
- Try a larger computation task, such as the multiplication of large matrices, and see the difference in speed between the CPU and GPU. What about a task with a small amount of calculations?
-
marked difference at 100 tensors milli and micro seconds
-
at 1 tensor they are comparative 1.63 ms vs 1.59 ms
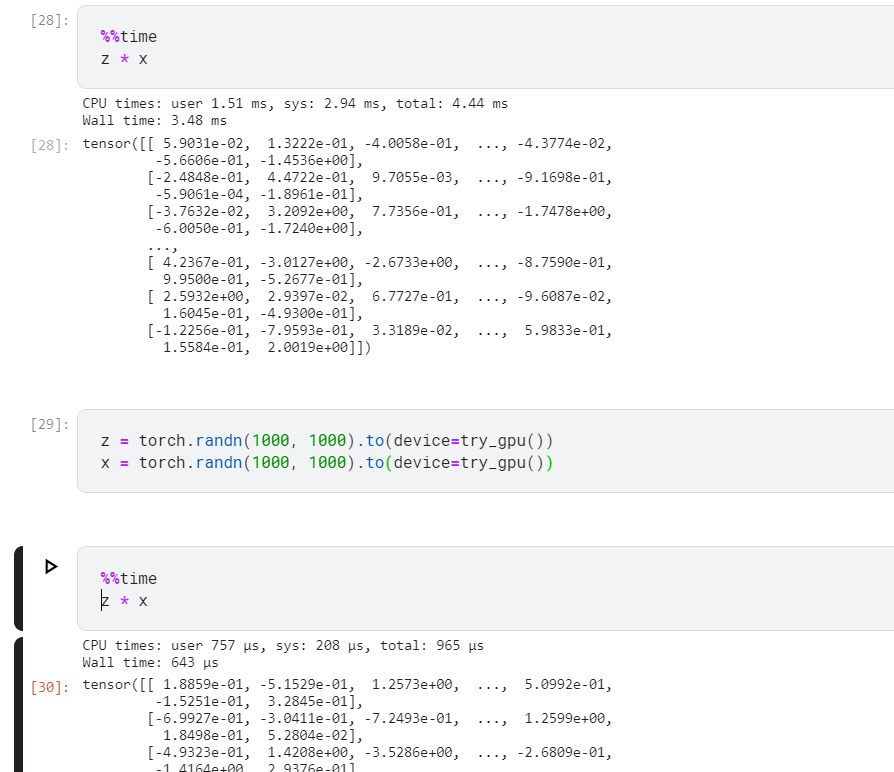
- How should we read and write model parameters on the GPU?
- by using
net.to(device=torch.device('cuda'))
- Measure the time it takes to compute 1000 matrix-matrix multiplications of 100 × 100 matrices and log the Frobenius norm of the output matrix one result at a time vs. keeping a log on
the GPU and transferring only the final result.
- I did not get it but the difference between time in cpu and gpu is 40ms.
- Measure how much time it takes to perform two matrix-matrix multiplications on two GPUs
at the same time vs. in sequence on one GPU. Hint: you should see almost linear scaling.
- I have one GPu