每次我使用GPU的时候就会蓝屏,但具体原因我不清楚,经过一段摸索后,我发现只要我的副屏开着就会导致蓝屏。我是1050ti的显卡,有人知道怎么解决吗
破案了,nvidia的531.18的驱动的问题,可以选择回退或者再更新
同问,我在pycharm上跑也很慢,不知道哪里出了问题
ROCm有人用过么?家里有台A卡,想利用起来,
我觉得你这个第三题有点问题,题目的意思应该是每次在GPU上计算就输出一次log和在GPU上计算完成后再输出log。
X = torch.rand((1000, 1000))
X_gpu = X.cuda(2)
X_gpu2 = X.cuda(2)
X_gpu2 is X_gpu

time_start = time.time()
for i in range(10000):
X_gpu = torch.mm(X_gpu,X_gpu)
print(torch.norm(X_gpu))
time_end = time.time()
print(f’gpu time cost: {round((time_end-time_start)*1000)}ms’)
time_start = time.time()
for i in range(10000):
X_gpu2 = torch.mm(X_gpu2,X_gpu2)
print(torch.norm(X_gpu2))
time_end = time.time()
print(f’gpu time cost: {round((time_end-time_start)*1000)}ms’)


为什么我的笔记本电脑输入 torch.cuda.device_count() 结果输出:0 ?我的电脑是有独立显卡的啊
你的是n卡还是a卡啊,cuda只有n卡才支持
mac可以使用mps代替cuda,不过index只可以取0
# 下面两行等价
device = torch.device(‘mps’)
device = torch.device(‘mps:0’)
# 可以使用如下代码检测mps是否可用
torch.has_mps
# 一般可以这么写
device = torch.device(‘mps’ if device.has_mps else ‘cpu’)
1 Like
torch.cuda.device_count()输出是0
但是cmd里nvidia -smi是有正常信息的
这是咋回事
1 Like
There maybe something wrong with the pytorch version. I’ve met the same problem.
Check this out: 如何将pytorch的cpu版改成gpu版【实测成功】_测试版cpu改版本怎么改_captain飞虎大队的博客-CSDN博客
可以restart一下jupyter的kernel,执行俩次观察,第一次是gpu比cpu慢很多,第二次是gpu变快了。
问题三terminal或者ide执行脚本gpu速度慢的原因就是cpu到gpu数据传输的latency导致的。
为什么我的CUDA已经安装好了,但是在程序中无法调用。在cmd中输入nvcc -V能正确显示版本号,cuDNN的文件也按照教程配置了。
Q2: 经验证,gpu上的模型可以直接save, load模型参数,操作与cpu完全一致,不需要做模型迁移。
是n卡。为啥回复必须要求至少有20个字符?
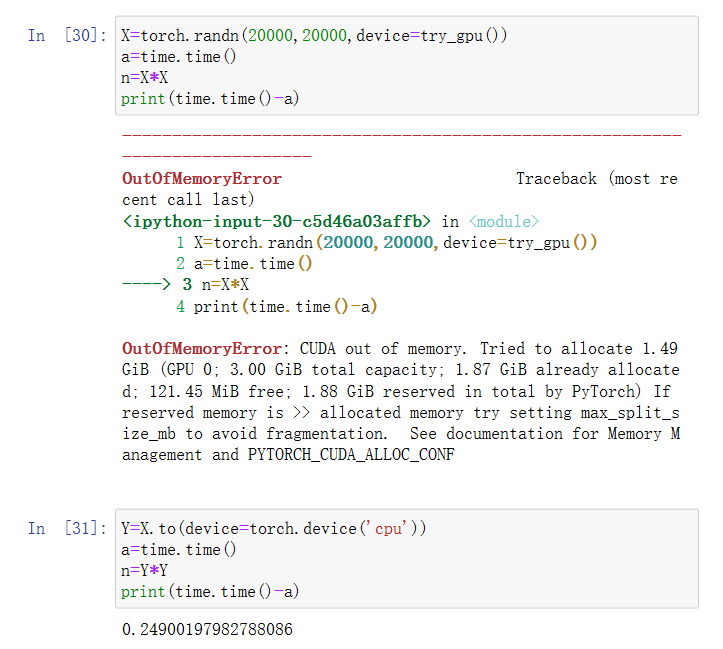
计算还是比CPU快得多的,只是1050的显存2G太小了,它根本装不下这个矩阵。
“一个典型的错误如下:计算GPU上每个小批量的损失,并在命令行中将其报告给用户(或将其记录在NumPy ndarray 中)时,将触发全局解释器锁,从而使所有GPU阻塞。最好是为GPU内部的日志分配内存,并且只移动较大的日志。” 我看现在深度学习Paper里面的实现基本上都是用logging输出到控制台或文件,请问这部分具体怎么在GPU上进行?
不知道你测试的代码是什么,但我用的上面@BabyXin的代码,在vscode的python文件中直接运行,第一次的结果是
cpu 计算总时长: 86.31 ms
gpu 计算总时长: 155.42 ms
然后我看你说jupyter中速度会更快,于是我也搬到jupyter中测试,得到的结果是:
cpu 计算总时长: 92.91 ms
gpu 计算总时长: 146.79 ms
不过我又再次跑了一下,结果变成了:
cpu 计算总时长: 95.03 ms
gpu 计算总时长: 4.95 ms
于是我猜测可能是初时没有调动起显卡,它热身的耗时导致的,于是我又扭头去python文件中测试,第二次运行结果:
cpu 计算总时长: 77.73 ms
gpu 计算总时长: 123.66 ms
似乎没有什么变化,不过我注意到当我关闭了jupyter后,风扇声立马变小,因此我猜测可能是jupyter中一旦调用了pytorch库,就会一直保持运行,因此显卡不必花费时间在热身上,于是我查看了此时显卡的运行情况:
Sat Feb 17 14:49:44 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.29.06 Driver Version: 545.29.06 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1660 Ti Off | 00000000:01:00.0 Off | N/A |
| N/A 41C P8 5W / 80W | 122MiB / 6144MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 619 G /usr/lib/Xorg 4MiB |
| 0 N/A N/A 118995 C ...enjl/miniforge3/envs/d2l/bin/python 114MiB |
+---------------------------------------------------------------------------------------+
最后一行果然如此,jupyter占用了110MB的显存。不过为什么python文件中直接运行,gpu的效果不好,我猜测可能每一次调用python文件执行,都是一次全新的过程,都要重新向gpu申请显存等一些列操作,所以耗时较多。
arc A770有人试过能跑吗,用torch的xpu版本
可以用mps,m3pro粗略测试,速度是CPU的4倍。