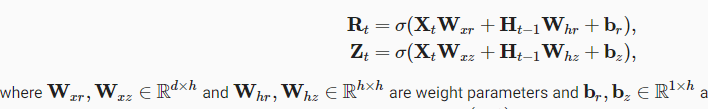
Perhaps I’m missing something, but It looks like there’s a dimensionality disagreement:
Both products of X_tW_x and H_t-1W_h have shapes nxh, yet the biases have a shape 1xh.
Is there an implicit broadcasting being made for the bias terms to enable the summation?
Yes. We also mentioned it in linear regression:

Nonetheless, I’ve just added such explanations: https://github.com/d2l-ai/d2l-en/commit/99b92a706b543cfee03b5f9cd874d4771c97cd37
For optimizing the hyperparams on question 2, do we need to perform k-fold validation (and thus augment train_ch8), or just try out different hypers strait into the train_ch8 function itself?
I think in theory at least it would be correct to optimizer our hypers via the use of hold-out right?
Possible typo at 10. Modern Recurrent Neural Networks — Dive into Deep Learning 1.0.3 documentation
Furthermore, we will expand the RNN architecture with a single undirectional hidden layer that has been discussed so far.
Should it be “unidirectional”?
Yup indeed a typo. Thanks!

A good article on Convex Combinations (mentioned in Section 9.1.1.3 [Hidden State])
This looks lovely, is this wandb?
I think there is a small problem with GRU visualization, -1 should be (x) to h_{t-1} and not the output of tanh gate.
when I want to run the code which trains the model,I find it works so slow(about 2 hours)
is that normal?
since GRU has the power of mitigating gradients exploding, so why here still uses the old code block w/ grad clipping and detach()? how to reveal the value of GRU?
Yes, it depends on your computing resource, the amount of training data, and the size of ur model