lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr)
training on cpu
no other results?
no pic?
so slow?
Please use a GPU for deep nets. A CPU could be 100 times slower than a GPU.
For the AlexNet on Fashion-MNIST, a GPU takes ~ 20 seconds per epoch, which means a CPU would take 2000 seconds ~ 30 minutes.
@ChenYangyao thank for your reply. I don’t have gpus. I’m using colab for learning.
And now I can’t find any exercitations because of my finance undergraduate diploma.
@StevenJokes I think colab lets you use a GPU for free? Tools -> Change runtime type -> choose ‘GPU’ under Hardware Accelerator
@Nish
I have known it. But 12 hours will disconnect. 
And you can find why colab is not so friendly in my discussion:
http://d2l.ai/chapter_appendix-tools-for-deep-learning/colab.html
And there is an issue of python 3.6:
aha, I see. maybe you can try the kaggle.com free kernel? It allows 30 hours a week of GPU use for its contests I think.
Hi!!
If I change Dataset then how do I change the below statement like dataset of Animals?
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
Any Suggestion??
For Exercise 4, I’m guessing the dominant part of computation is the block of fully connected layers at the end. Is the dominant part of the memory footprint the largest convolution layer?
If you are using custom dataset then you might have to use the torch.utils.data.Dataset to create a custom class. Writing Custom Datasets, DataLoaders and Transforms — PyTorch Tutorials 1.9.0+cu102 documentation
Exercises
- Try increasing the number of epochs. Compared with LeNet, how are the results different? Why?
Finally was able to “train” it but it looks more like a heartbeat than anything
- The result is a very noisy function, it is like its not getting trained at all.
-
AlexNet may be too complex for the Fashion-MNIST dataset.
- Try simplifying the model to make the training faster, while ensuring that the accuracy
does not drop significantly.
- done but accuracy has still not improved.
- Design a better model that works directly on 28 × 28 images.
- done.
-
Modify the batch size, and observe the changes in accuracy and GPU memory.
- more batch size more consumption
-
Analyze computational performance of AlexNet.
- any idea how to do it ?
-
What is the dominant part for the memory footprint of AlexNet?
- Linear network and 3 cnns
-
What is the dominant part for computation in AlexNet?
- the neuralnetwork 3 cnns
-
How about memory bandwidth when computing the results?
- more than 100 mb
-
Apply dropout and ReLU to LeNet-5. Does it improve? How about preprocessing?
lenet_5 = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), nn.Linear(16 * 5 * 5, 120), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(120, 84), nn.ReLU(), nn.Linear(84, 10))its not training well as well.
FInally able to train , here is the network summary
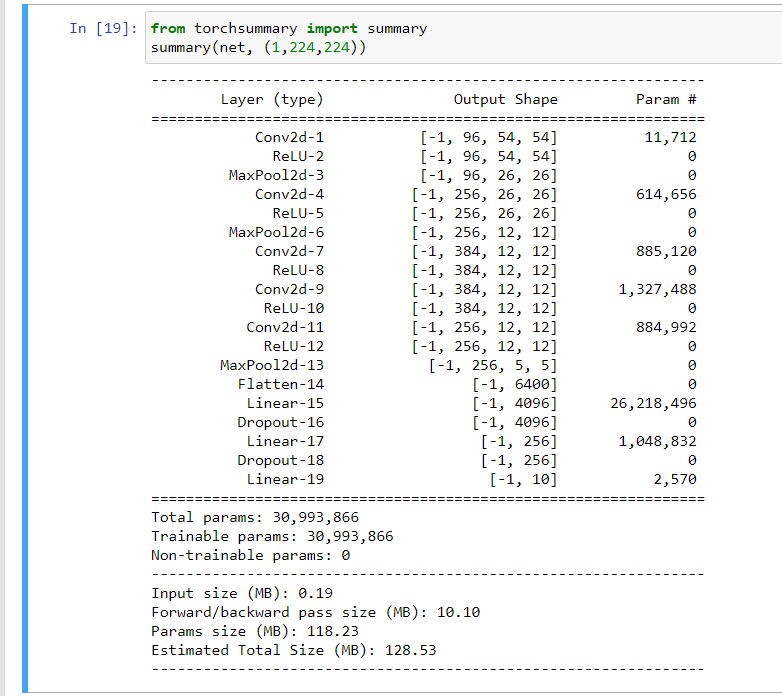
it took me 6m 21 sec to get an accuracy of 88.7, in just 3 epochs.
When i have learned the CNN network, the question always in my mind is how to design the good architecture and also how many filter, layer is enough?
class AlexNet(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(
nn.LazyConv2d(96, kernel_size=11, stride=4, padding=1),
nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2),
...
nn.LazyLinear(4096), nn.ReLU(),nn.Dropout(p=0.5),
nn.LazyLinear(num_classes))
self.net.apply(d2l.init_cnn) # <-----
The last line has no effect since a dry run has not been performed yet and hence the lazy layers have not been reified into regular (non-lazy) layers.
Why ReLU activation is not applied after MaxPool2d?
does it may save memory and computation in forward and backward propagation
what this line “self.net.apply(d2l.init_cnn)” in the AlexNet class do?
is it will not be executed?
self.net.apply(d2l.init_cnn)
It seems that this line will not work, since the layer dimensions are not initialized until input data is passed through the network for the first time.
my solution is :
1. Defining an initial function in the class
def para_init(self):
self.net.apply(d2l.init_cnn)
2. Conducting a forward, then initial the parameters
model = AlexNet(lr = 0.01)
data = d2l.FashionMNIST(batch_size=128,resize=(224,224))
model(next(iter(data.get_dataloader(True)))[0])
model.para_init()