in 2.1.4. Indexing and Slicing
X[0:2, :]
this code suppose to take the 1th and 2nd rows, but why it isn’t typed like that -> X[0:1,:]
in 2.1.4. Indexing and Slicing
X[0:2, :]
this code suppose to take the 1th and 2nd rows, but why it isn’t typed like that -> X[0:1,:]
thanks for responding
in the slicing code. we want to take the 1th row (index = 0) and the 2nd row (index = 1) in the example. put the code start from index 0 to index 2 (0:2).
shouldn’t it be (0:1)
Slicing is an indexing syntax that extracts a portion from the tensor. X[m:n] returns the portion of X :
m
n
thanks man, "Up to but not including n" is the key that i was looking for
Hello guys,
In section 2.1.6 [Conversion to Other Python Objects], what do you mean by the line in bold; Unfortunately I can’t get it and I need help. Thanks
Converting to a NumPy tensor, or vice versa, is easy. The converted result does not share memory. This minor inconvenience is actually quite important: when you perform operations on the CPU or on GPUs, you do not want to halt computation, waiting to see whether the NumPy package of Python might want to be doing something else with the same chunk of memory.
Does it mean NumPy and PyTorch are completely independent and may have conflicts with each other?
Edit: According to PyTorch documentation:
Converting a torch Tensor to a NumPy array and vice versa is a breeze. The torch Tensor and NumPy array will share their underlying memory locations, and changing one will change the other.
It says this conversion shares the memory but you said not! Am I right?
This is probably carried over from the MXNET version, where the corresponding operation does create a copy:
asnumpy() : Returns anumpy.ndarrayobject with value copied from this array.
@anirudh should be able to confirm/deny this.
Thanks, @Aaron and @gphilip for raising this. Most part of the book has common text and we are trying to fix issues like these where the frameworks differ in design. Feel free to raise any other issues if you find something similar in other sections on the forum or the Github repo. Really appreciate it!
This will be fixed in the next release.
e = torch.arange(12).reshape(2, -1, 6)
f = torch.tensor([1, 2, 3, 4]).reshape(-1, 4, 1)
e, f, e.shape, f.shape
(tensor([[[ 0, 1, 2, 3, 4, 5]],
[[ 6, 7, 8, 9, 10, 11]]]), tensor([[[1],
[2],
[3],
[4]]]), torch.Size([2, 1, 6]), torch.Size([1, 4, 1]))
e + f
tensor([[[ 1, 2, 3, 4, 5, 6],
[ 2, 3, 4, 5, 6, 7],
[ 3, 4, 5, 6, 7, 8],
[ 4, 5, 6, 7, 8, 9]],
[[ 7, 8, 9, 10, 11, 12],
[ 8, 9, 10, 11, 12, 13],
[ 9, 10, 11, 12, 13, 14],
[10, 11, 12, 13, 14, 15]]])
Hello! I had two questions from this section:
Where does the term “lifted” come from? I understand “lifted” means some function that operate on real numbers (scalars) can be “lifted” to a higher dimensional or vector operations. I was just curious if this is a commonly used term in mathematics. 
Is there a rule for knowing what the shape of a broadcasted operation may be? For Exercise #2, I tried a shape of (3, 1, 1) + (1, 2, 1) to get (3, 2, 1). I also tried (3, 1, 1, 1) + (1, 2, 1) and got (3, 1, 2, 1). It kind of gets harder to visualize how broadcasting will work beyond 3-D, so I was wondering if someone could explain why the 2nd broad operation has the shape that it has intuitively.
Thank you very much!
Lifting is commonly used for this operation in functional programming (e.g. in Haskell), probably it has some roots in lambda calculus.
@hojaelee , During broadcasting the shape matching of the two inputs X, Y happen in reverse order i.e. starting from the -1 axis. This (i.e. -ve indexing) is also the preferred way to index ndarray or any numpy based tensors (either in PyTorch or TF) instead of using +ve indexing. This way you will always know the correct shapes.
Consider this example:
import torch
X = torch.arange(12).reshape((12)) ## X.shape = [12]
Y = torch.arange(12).reshape((1,12)) ## Y.shape = [1,12]
Z = X+Y ## Z.shape = [1,12]
and contrast the above example with this below one
import torch
X = torch.arange(12).reshape((12)) ## X.shape = [12]
Y = torch.arange(12).reshape((12,1)) ## Y.shape = [12, 1] <--- NOTE
Z = X+Y ## Z.shape = [12,12] <--- NOTE
And in both the above examples, a very simple rule is followed during broadcasting:
1 then inflate this tensor in this axis with the OTHER valueHope it helps.
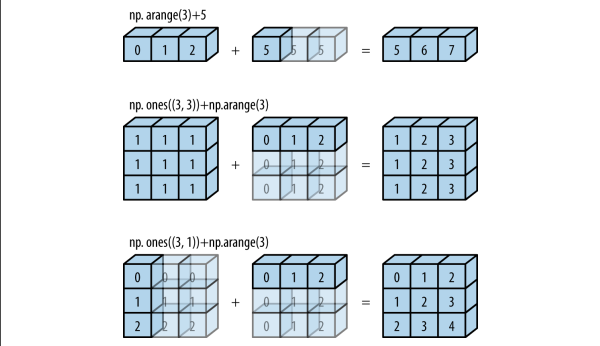
if anyone has any confusion related to broadcasting, this is how it actually looks in Numpy.
taken form python data science handbook
I’ve checked this information, but I have obtained a different result:

X == Y to X < Y or X > Y, and then see what kind of tensor you can get.X = torch.arange(15).reshape(5,3)
Y = torch.arange(15, 0, -1).reshape(5,3)
X == Y, X > Y, X < Y
(tensor([[False, False, False],
[False, False, False],
[False, False, False],
[False, False, False],
[False, False, False]]),
tensor([[False, False, False],
[False, False, False],
[False, False, True],
[ True, True, True],
[ True, True, True]]),
tensor([[ True, True, True],
[ True, True, True],
[ True, True, False],
[False, False, False],
[False, False, False]]))
X = torch.arange(8).reshape(4, 2, 1)
Y = torch.arange(8).reshape(1, 2 ,4)
print(f"{X}, \n\n\n{Y}, \n\n\n{X + Y}")
tensor([[[0],
[1]],
[[2],
[3]],
[[4],
[5]],
[[6],
[7]]]),
tensor([[[0, 1, 2, 3],
[4, 5, 6, 7]]]),
tensor([[[ 0, 1, 2, 3],
[ 5, 6, 7, 8]],
[[ 2, 3, 4, 5],
[ 7, 8, 9, 10]],
[[ 4, 5, 6, 7],
[ 9, 10, 11, 12]],
[[ 6, 7, 8, 9],
[11, 12, 13, 14]]])
Yes, the result matches what I expected as well as with what I learned in this notebook
Exercise-2. Replace the two tensors that operate by element in the broadcasting mechanism with other shapes, e.g., 3-dimensional tensors. Is the result the same as expected?
I understand this error in principle, but can someone clarify objectively what “non-singleton dimension” means?
c = torch.arange(6).reshape((3, 1, 2))
e = torch.arange(8).reshape((8, 1, 1))
c, e
(tensor([[[0, 1]],
[[2, 3]],
[[4, 5]]]),
tensor([[[0]],
[[1]],
[[2]],
[[3]],
[[4]],
[[5]],
[[6]],
[[7]]]))
c + e
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In [53], line 1
----> 1 c + e
RuntimeError: The size of tensor a (3) must match the size of tensor b (8) at non-singleton dimension 0
in: (X>Y).dtype
out: torch.bool
in: X = torch.arange(12, dtype=torch.float32).reshape(3,4)
Y = torch.tensor([[1, 4, 3, 5]])
X.shape, Y.shape
(torch.Size([3, 4]), torch.Size([1, 4]))
Exp for broadcasting
Each tensor has at least one dimension.
When iterating over the dimension sizes, starting at the trailing dimension, the dimension sizes must either be equal, one of them is 1, or one of them does not exist.
This code:
before = id(X)
X += Y
id(X) == before
Does not return true for me. I asked chatGPT it says this does not adjust the vairable in place.
What am I doing wrong?
Thanks!
EDIT: Is seems this only works with lists, not regular variables. Is this where I went wrong. Thanks!
Ex1.
import torch
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
X < Y
Output:
tensor([[ True, False, True, False],
[False, False, False, False],
[False, False, False, False]])
X > Y
Output:
tensor([[False, False, False, False],
[ True, True, True, True],
[ True, True, True, True]])
> and < perform element-wise comparison operations on the two tensors with the same shape, as per the documentation.Ex2.
(3, 3, 3) defined as![]()
where ![]() is determined via
is determined via
![]()
a = torch.arange(9).reshape((3, 1, 3))
b = torch.arange(3).reshape((1, 3, 1))
a, b
Output:
(tensor([[[0, 1, 2]],
[[3, 4, 5]],
[[6, 7, 8]]]),
tensor([[[0],
[1],
[2]]]))
c = a + b
c
Output:
tensor([[[ 0, 1, 2],
[ 1, 2, 3],
[ 2, 3, 4]],
[[ 3, 4, 5],
[ 4, 5, 6],
[ 5, 6, 7]],
[[ 6, 7, 8],
[ 7, 8, 9],
[ 8, 9, 10]]])
# If not that straightforward to see, let's try an explicit broadcasting scheme.
c1 = torch.zeros((3, 3, 3))
for i in range(3):
for j in range(3):
for k in range(3):
c1[i, j, k] = a[i, 0, k] + b[0, j, 0]
c1 - c
Output:
tensor([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])