http://d2l.ai/chapter_convolutional-neural-networks/conv-layer.html
Hey @anirudh in section 6.2.4 Learning A Kernel
when printing this at the bottom of our for loop:
if (i+1) % 2 == 0:
print(f'batch {i+1}, loss {l.sum():.3f}')
should it be batch or epoch? I thought it was epoch, could you explain why its batch instead?
1 Like
- When you try to automatically find the gradient for the Conv2D class we created, what kind of error message do you see?
Got Error Message: Inplace operations are not supported using autograd .
- How do you represent a cross-correlation operation as a matrix multiplication by changing the input and kernel tensors?
–> flip the two-dimensional kernel tensor both horizontally and vertically, and then perform the cross-correlation operation with the input tensor
K = torch.tensor([[1.0, -1.0]]) # filter shape: (1, 2)
# flip horizontally
K = torch.flip(K, [1])
# flip vertically
K = torch.flip(K, [0])
print(K)
print(K)
Y = corr2d(X, K)
plt.imshow(Y, cmap="gray")
What is the minimum size of a kernel to obtain a derivative of degree d?
–> I have no idea about this. Can someone clarify?
1 Like
For Exercise 2, l.sum().backward() is already computing the gradient, is it not?
how did you automatically try to find gradient?
yes through backpropagation the leaf tensor gradient is stored in net.grad
Exercises
-
Construct an image X with diagonal edges.
-
What happens if you apply the kernel K in this section to it?
- zero matrix.
-
What happens if you transpose X?
- No change
-
What happens if you transpose K?
- zero matrix.
-
-
When you try to automatically find the gradient for the Conv2D class we created, what kind
of error message do you see?
* I am able to do `net.weights.grad`, when I try `net.grad` I get the error `'Conv2d' object has no attribute 'grad'`
- How do you represent a cross-correlation operation as a matrix multiplication by changing
the input and kernel tensors?
* cross correlation is basically matrix multiplication between slices of tensorfrom X of the shape of kernel and summing.
* It can be done by padding Kand X based on what is needed to multiply
-
Design some kernels manually.
-
What is the form of a kernel for the second derivative?
- okay in order to compute one way would be to manually compute the second derivative and then let see a kernel be made using backpropogation
https://dsp.stackexchange.com/questions/10605/kernels-to-compute-second-order-derivative-of-digital-image
- okay in order to compute one way would be to manually compute the second derivative and then let see a kernel be made using backpropogation
-
What is the kernel for an integral?
- how do you actually make it manually
-
-
What is the minimum size of a kernel to obtain a derivative of degree d
* dont know.
I think so,epoch is batter than batch.
Construct an image X with diagonal edges.
-
What happens if you apply the kernel
Kin this section to it?
it detects the diagonal edges -
What happens if you transpose
X?
same -
What happens if you transpose
K?
same also -
How do you represent a cross-correlation operation as a matrix multiplication by changing the input and kernel tensors?
transforming the kernal in a matrix
Km = torch.zeros((9,5))
kv = torch.tensor([0.0,1.0,0.0,2.0,3.0])
for i in range(4):
Km[i:i+5,i] = kv
Km = Km.t()
Km = Km[torch.arange(Km.size(0))!=2]
Km = Km.t()
Km = tensor([[0., 0., 0., 0.],
[1., 0., 0., 0.],
[0., 1., 0., 0.],
[2., 0., 0., 0.],
[3., 2., 1., 0.],
[0., 3., 0., 0.],
[0., 0., 2., 0.],
[0., 0., 3., 0.],
[0., 0., 0., 0.]])
transforming the input X in a vector
X = torch.tensor([[float(i) for i in range(9)]])
X = tensor([[0., 1., 2., 3., 4., 5., 6., 7., 8.]])
X @ Km #matrix multiplication
result : tensor([[19., 25., 37., 0.]])
We reprint a key figure in Fig. 7.2.2 to illustrate the striking similarities.
What similarities is Fig. 7.2.2 trying to illustrate? I mean, what is being compared to what?
following this

After all, for a function $$f(i,j)$ its derivative $-\partial_i f(i,j) = \lim_{\epsilon \to 0} \frac{f(i,j) - f(i+\epsilon,j)}{\epsilon}$$
I got difference operator for the second derivative is [-1, 0, -1]
CODE
X = torch.ones((6, 8))
X[:, 2:6] = 0
K = torch.tensor([[1.0, -1.0]])
derivative1 = corr2d(X, K)
derivative2 = corr2d(derivative1, K)
print(derivative2)
@#OUT
tensor([[-1., 1., 0., 0., 1., -1.],
[-1., 1., 0., 0., 1., -1.],
[-1., 1., 0., 0., 1., -1.],
[-1., 1., 0., 0., 1., -1.],
[-1., 1., 0., 0., 1., -1.],
[-1., 1., 0., 0., 1., -1.]])
K = torch.tensor([[-1.0, 0.0, -1.0]])
derivative2 = corr2d(X, K)
print(derivative2)
@#OUT
tensor([[-1., -1., 0., 0., -1., -1.],
[-1., -1., 0., 0., -1., -1.],
[-1., -1., 0., 0., -1., -1.],
[-1., -1., 0., 0., -1., -1.],
[-1., -1., 0., 0., -1., -1.],
[-1., -1., 0., 0., -1., -1.]])
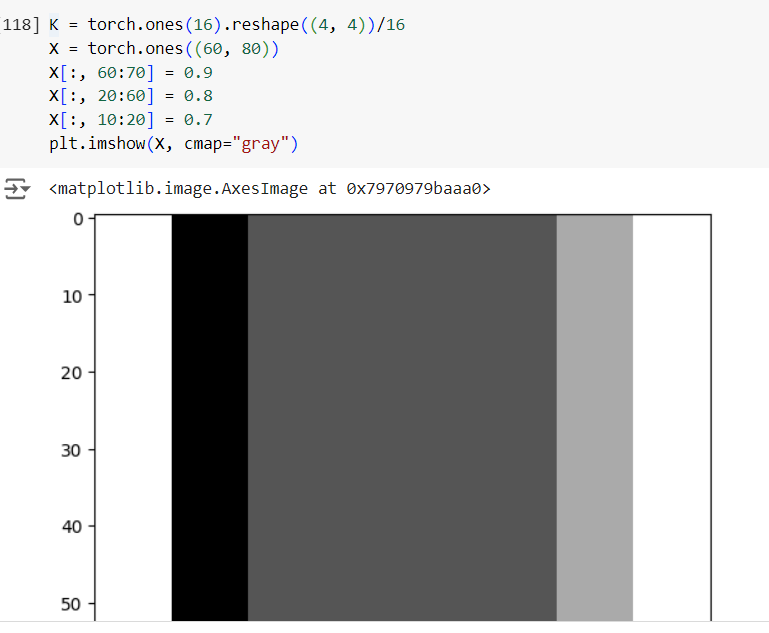
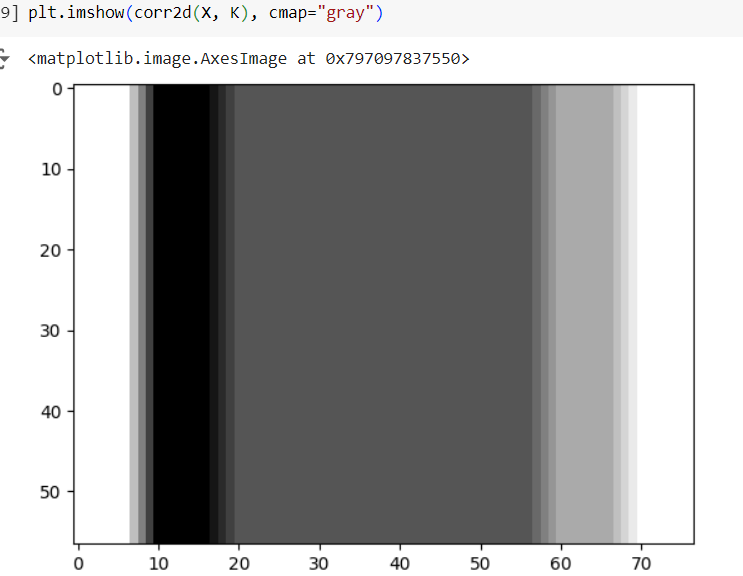
- How would you design a blur kernel? Why might you want to use such a kernel?
-
blur_deg = 4
-
K = torch.ones(blur_deg2).reshape((blur_deg, blur_deg))/blur_deg2
- What is the minimum size of a kernel to obtain a derivative of order $d$?
- d+1
Hi, thank you for the intuition on this. I can see different results but make sense that the second derivative is:
Y2 = corr2d( cordd2d ( X, K), K)
Applying this manually for the first tree elements of X I can see this:
kernel: 1.0, -1.0 | 1.0, -1.0
X[0, :3] = 110
naming elements:
a, b, c = X[0, 0], X[0, 1], X[0, 2]
the first derivative reduces the expresion to two elements
e, f = a - b, b - c
similarly the second rerivative generates one final element
g = e - f = (a - b ) - (b - c) = a -2b + c
hence the kernel will be [1, -2, 1]
Code:
X = torch.ones((1, 8))
X[:, 2:6] = 0
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(corr2d(X, K), K)
Y
tensor([[-1., 1., 0., 0., 1., -1.]])
KK = torch.tensor([[1.0, -2.0, 1.0]])
YY = corr2d(X, KK)
YY
tensor([[-1., 1., 0., 0., 1., -1.]])