https://d2l.ai/chapter_linear-regression/linear-regression-concise.html
I’m trying to understand question 1.
I think the question is somewhere wrong.
When I replaced nn.MSELoss() with `nn.MSELoss(reduction=‘mean’)’, the results were almost the same.
And so I searched the pytorch docs for information and is said that,
the parameter ‘reduction’ has default value of ‘mean’.
To sum it up, the question 1 is asking the difference of same code.
I guess this should be fixed.
Below is the description about parameter ‘reduction’.
reduction ( string , optional ) – Specifies the reduction to apply to the output: 'none' | 'mean' | 'sum' . 'none' : no reduction will be applied, 'mean' : the sum of the output will be divided by the number of elements in the output, 'sum' : the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction . Default: 'mean'
1 Like
Glad it helped!
Thanks for fixing it!
I’m confused of "size_average and reduce are in the process of being deprecated" .
I need to ask you to confirm that I’m right about reduction ( string , optional ) can replace the others.
Yes reduce is deprecated in pytorch and has been replaced by reduction
1 Like
-
CLASS torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean')
- print(net[0].weight.grad())
For more:
Search for accessing the gradient:https://d2l.ai/chapter_deep-learning-computation/parameters.html

I got a problem when running the training code. I got the following warning message:
*/usr/local/lib/python3.6/dist-packages/torch/nn/modules/loss.py:432: UserWarning: Using a target size (torch.Size([500])) that is different to the input size (torch.Size([500, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.*
* return F.mse_loss(input, target, reduction=self.reduction)*
I looked into the code and find that net(X) produces a tensor with shape (500,1) while the label y has a shape (500). I think it should be better to use loss(net(X).reshape(y.shape)) instead of loss(net(X),y)
I think what you say is good but not better.
In example,
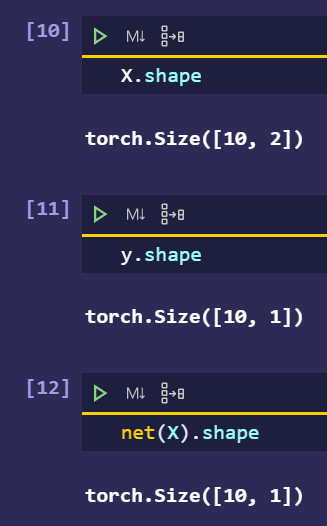
You’d better use loss(net(X),y.reshape(net(X).shape).
?Am I right

Thanks for the reply. Why is loss(net(X),y.reshape(net(X).shape)) better? Will it have a faster speed? Cause I think both loss(net(X).reshape(y.shape) and loss(net(X),y.reshape(net(X).shape)) are doing the same thing (i.e. to make sure that X and y are of the same dimension) except they may have different execution time.
Forgive me if I am talking nonsense. I am quite new to deep learning and PyTorch so I am a bit confused. 
In the very first cell of the page, when were generating the data, there is the line:
labels = labels.reshape(-1,1)
This will make the shape of the labels tensor as (1000,1) from (1000) (assuming that you’re using 1000 examples).Since y is a single batch derived from the labels field, it will have a shape of (batch_size,1). Hence, y and the output of net(X) both will have the same shape and there is no need for reshaping.
So the given code is correct and perhaps you must’ve missed this line in your code which caused this warning.
1 Like
I am quite new too.
Like what Kushagra_Chaturvedy said,
data preprocessing is important for using pytorch API.
I did not see the line
labels = labels.reshape(-1,1)
in the text, to be honest. But I think @Kushagra_Chaturvedy is right. Preprocessing the data before the training will be better right?
?
There is no labels = labels.reshape(-1,1) in the section’s first line.
There is the newest version!:
http://preview.d2l.ai/d2l-en/PR-1080/chapter_preliminaries/autograd.html#grad.zero_()
So in your version, reshape is necessary for net(X) but not for labels.
New too. Wait for pro.
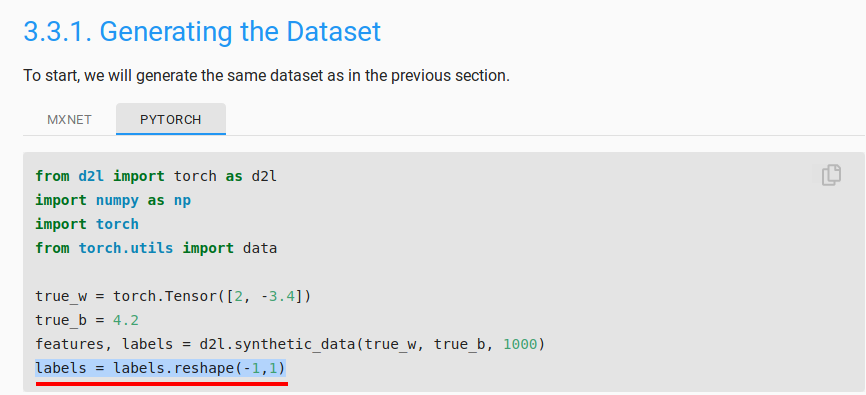
Oh! I was being silly. There IS the line for reshaping. 
Oh. I see it. 
However, which one is quicker ? I think (10,) is quicker than (10,1).
This was better approach, including this line resolved the issue I was having ( loss not decreasing and very high)