Thanks for the feedback @goldpiggy and @anirudh , I submitted the issue at https://github.com/d2l-ai/d2l-en/issues/1123 - hope it looks alright. Didn’t realise it was an error with the plot function, I was sure I was doing something wrong!
Thanks @Nish , I’ll try to find the reason behind this and get back to you on the issue tracker. I’m not sure but as I said it maybe an error of our plotting function.
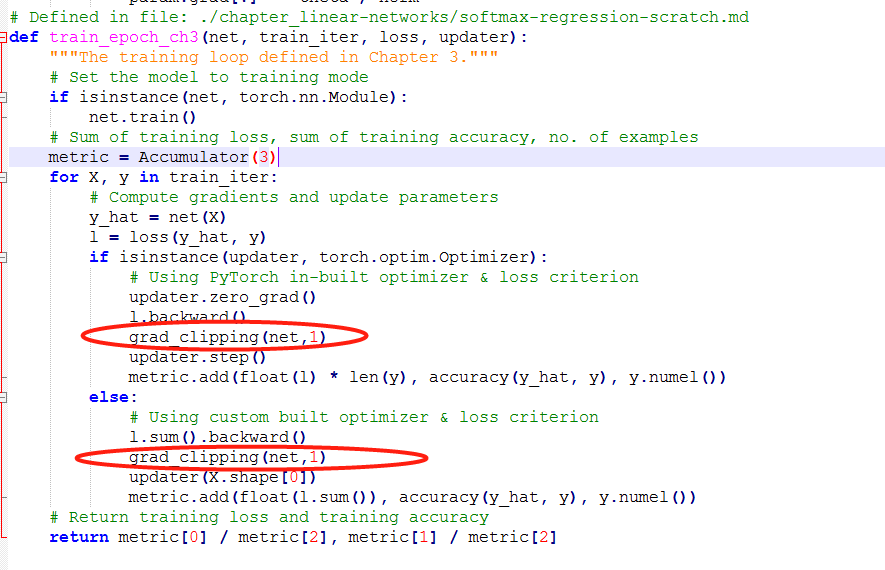
Hi @Nish, thanks for submitting the issue! I suspect it might be the “gradient exploding” problem. We haven’t talked about the “gradient clipping” strategy until chapter 8. Can you try grad_clipping here in http://preview.d2l.ai/d2l-en/master/chapter_recurrent-neural-networks/rnn-scratch.html#gradient-clipping to see if it can solve the issue?
If we happen to have multiple hidden layers, is it conventional to apply the same activation function on all the hidden layers or is it based on our neural network and its intended application?
Yes you are right @Kushagra_Chaturvedy. It is common to see “relu” been applied on varies of hidden layers. For example, in the later part of this book, you will see more advanced model (such as http://d2l.ai/chapter_convolutional-modern/nin.html#nin-blocks) where multiple relu are used!
This model on this dataset seems to be very sensitive to several design choices. Replacing relu with leakyrelu, for example, leads to horrible performance (loss=2.3), which is only somewhat alleviated by reducing the lr to .01. Using Adam instead of SGD has similarly bad performance using lr=.1 but improves with lr=.01.
I guess the “art” of DL comes from knowing how changing one hyperparameter will affect all the others 
1 Like
That’s why some deep learning researcher called themselves “alchemists”. ![]()
2 Likes
Great thoughts on this @StevenJokes! Hyperparameter are a set of parameters which you setup before the training, such as learning rate, layer size, layer number, etc. And yes, the AutoML is one of the techniques to optimize the hyperparameters.
1 Like
I was trying to tinker around with the number of layers and epochs. For example
net2 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)def init_weights(m):
if type(m) == nn.Linear:
torch.nn.init.normal_(m.weight, std=0.01)net2.apply(init_weights)
batch_size, lr, num_epochs = 256, 0.1, 100
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net2.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net2, train_iter, test_iter, loss, num_epochs, trainer)print(‘Train Accuracy’,d2l.evaluate_accuracy(net2,train_iter))
print('Test Accuracy ',d2l.evaluate_accuracy(net2,test_iter))d2l.predict_ch3(net2, test_iter)
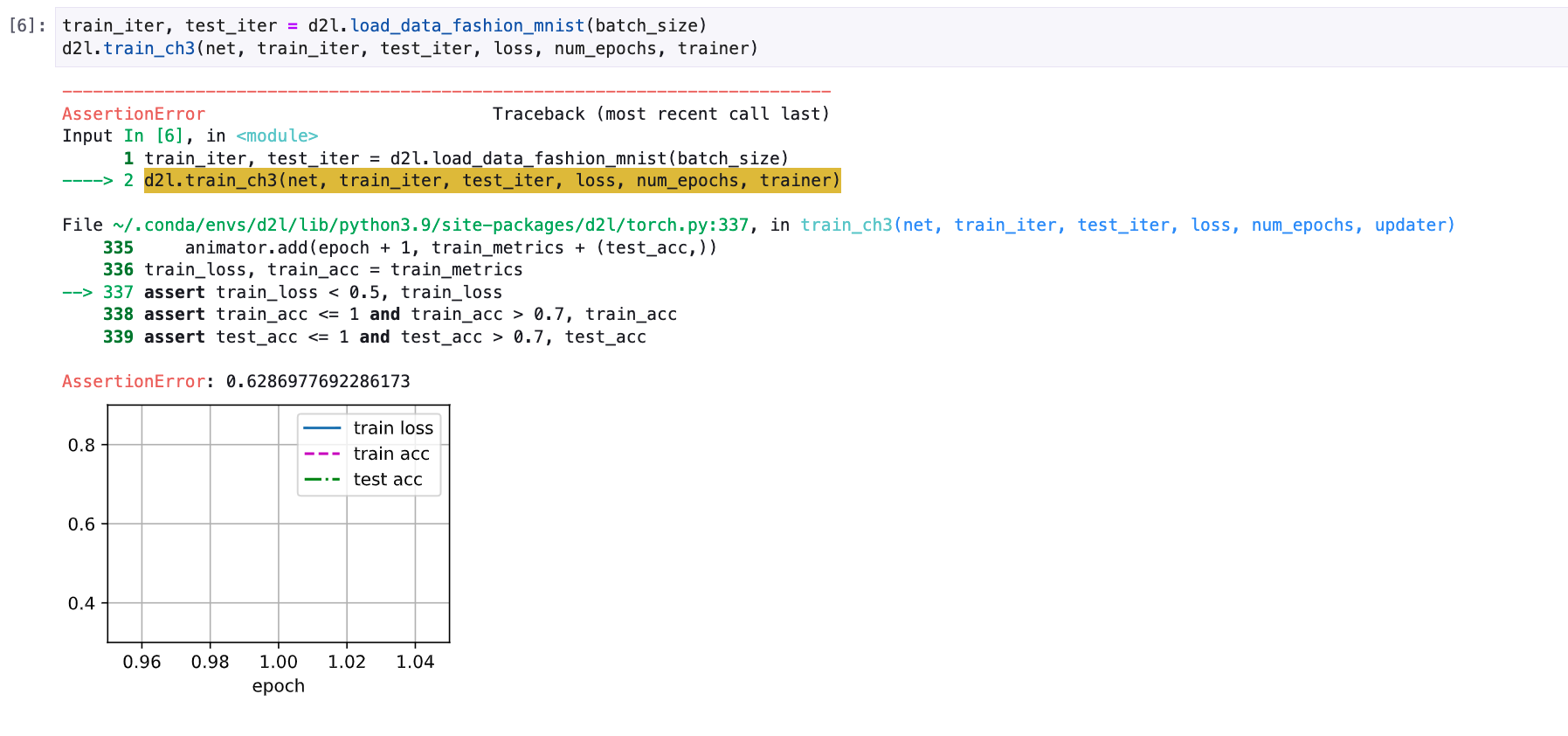
Train accuracy comes around 0.87, Has anyone reached a training accuracy of close to 1.
Hi @Nish, do you solve this problem? I meet the same problem.
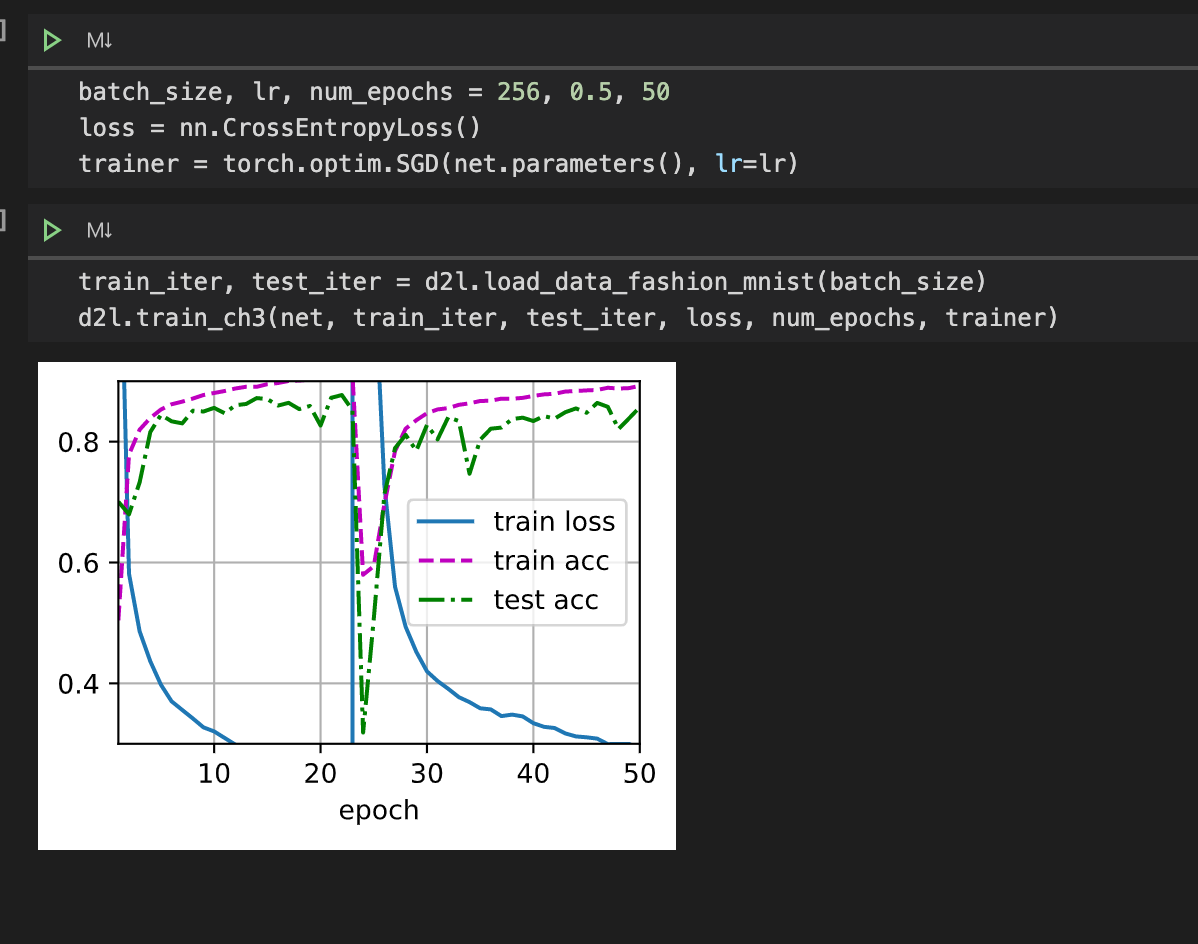
But I think this is normal phenomena as the learning rate increases. Since if the learning rate is too large, the gradient will skip the minimum-point. Such that, the curve will go wild.
1 Like
-
if there is a drop in plot…is that a error…if so y?
-
if my loss is 0 at the end of the training does that mean its “over fitting” or is it a “good model”?
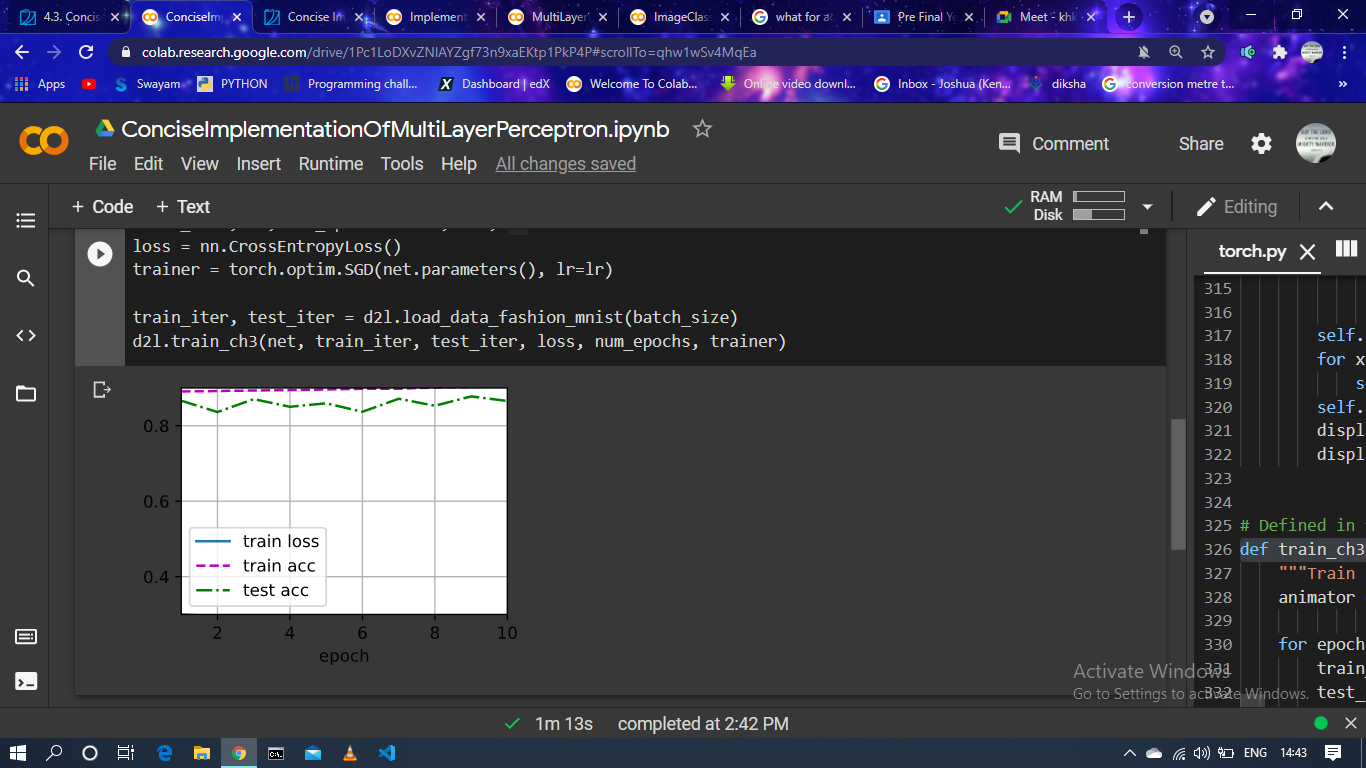
there is no train loss plot…what is the error
this happened to me after running the code or the training loop for four times…what does this mean
@samyfr7
I guess it was caused by that the train loss is too small to show the figure ,which I guess it from high train accuracy.
Oh…You can get my point from my third train:
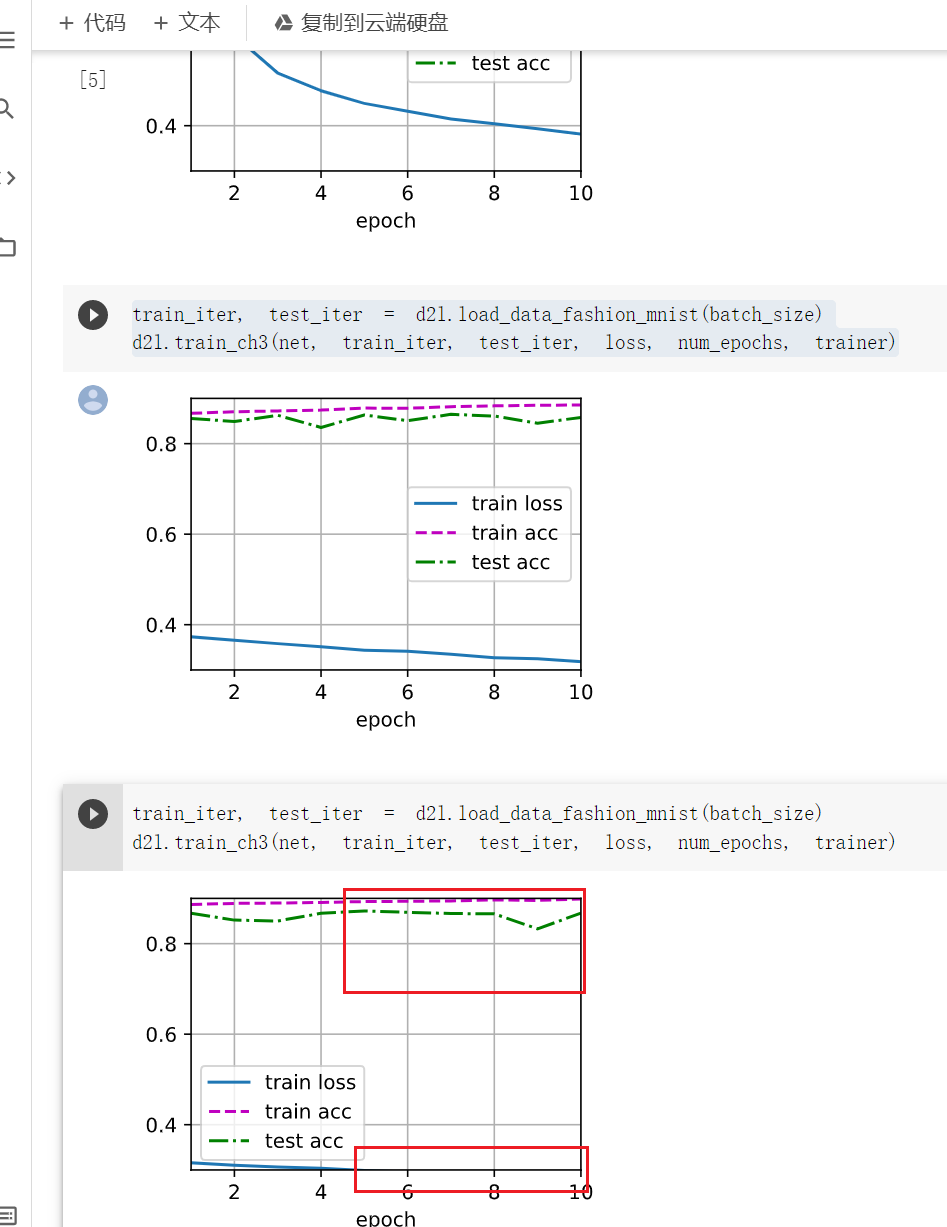
But %%why was your figure so different from mine?**
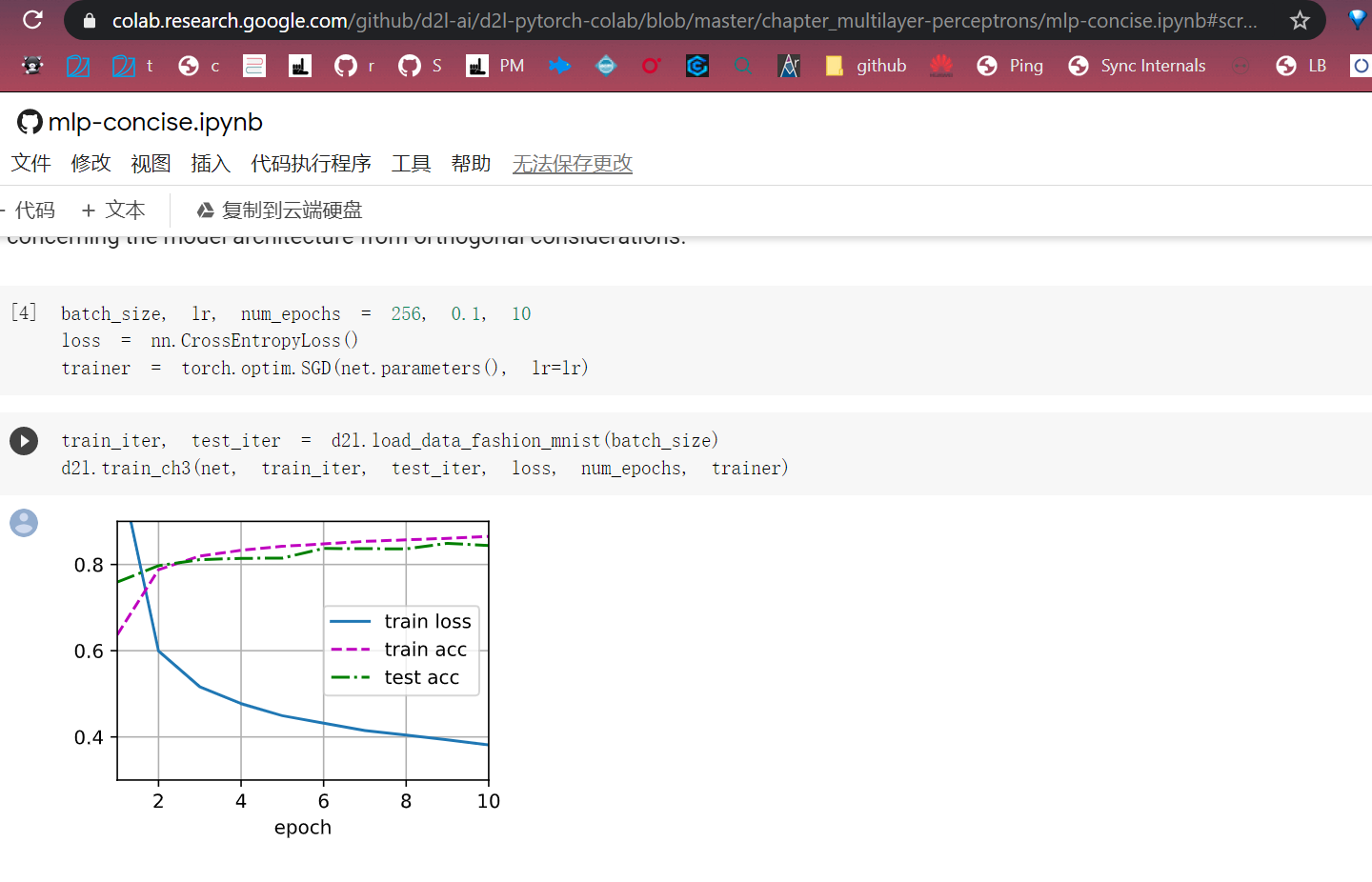
Maybe the different hypemeters?
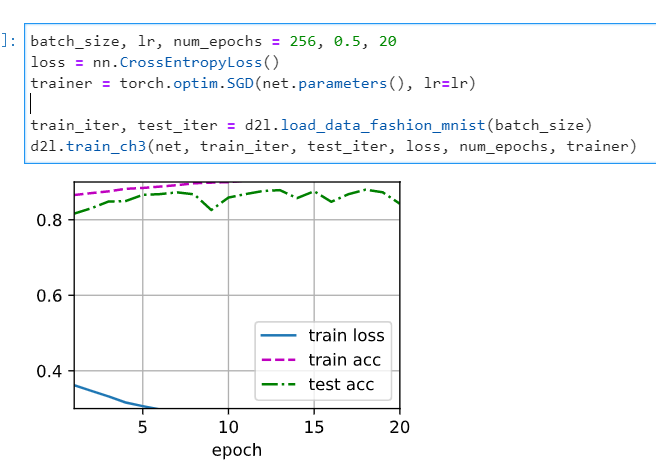
it looks like the grad_clipping can slove this problem, and beacuse the learning rate is bigger than normal, the learning process is faster than normal.
the changing code is
Exercises
- Try adding different numbers of hidden layers (you may also modify the learning rate). What
setting works best?
- it worked for me by just adding one more layer , and with SGD best earning rate was 0.1
- Try out different activation functions. Which one works best?
- I tried ADAM but shd was the best activation.
- Try different schemes for initializing the weights. What method works best?
- tried putting all linear layers to zero, but normal initialisation works best
looks like lr is too large
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
My doubt here is: We are initializing the weights but not passing any parameter to the function.
Morever, I could not find what is the use of net.apply
I found the answer here