I got a problem when running the training code. I got the following warning message:
*/usr/local/lib/python3.6/dist-packages/torch/nn/modules/loss.py:432: UserWarning: Using a target size (torch.Size([500])) that is different to the input size (torch.Size([500, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.*
* return F.mse_loss(input, target, reduction=self.reduction)*
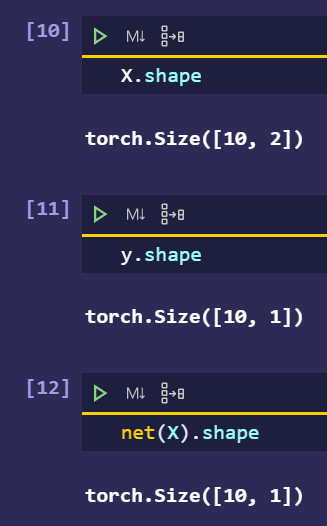
I looked into the code and find that net(X) produces a tensor with shape (500,1) while the label y has a shape (500). I think it should be better to use loss(net(X).reshape(y.shape)) instead of loss(net(X),y)
Thanks for the reply. Why is loss(net(X),y.reshape(net(X).shape)) better? Will it have a faster speed? Cause I think both loss(net(X).reshape(y.shape) and loss(net(X),y.reshape(net(X).shape)) are doing the same thing (i.e. to make sure that X and y are of the same dimension) except they may have different execution time.
Forgive me if I am talking nonsense. I am quite new to deep learning and PyTorch so I am a bit confused.
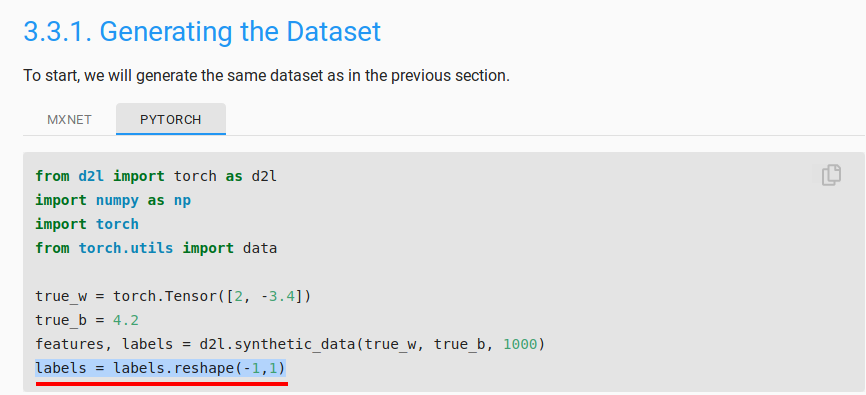
In the very first cell of the page, when were generating the data, there is the line: labels = labels.reshape(-1,1)
This will make the shape of the labels tensor as (1000,1) from (1000) (assuming that you’re using 1000 examples).Since y is a single batch derived from the labels field, it will have a shape of (batch_size,1). Hence, y and the output of net(X) both will have the same shape and there is no need for reshaping.
So the given code is correct and perhaps you must’ve missed this line in your code which caused this warning.
I did not see the line labels = labels.reshape(-1,1)
in the text, to be honest. But I think @Kushagra_Chaturvedy is right. Preprocessing the data before the training will be better right?
I feel puzzled about Q1. If we replace nn.MSELoss(reduction='sum') with nn.MSELoss() and we want the code to behave identically, I think we need to replace ‘lr’ with ‘lr/batch_size’. However, the result seems different. Can anyone tell me what’s wrong here?
I had the same intuition and ran into the same issues on Q1. The question for the MXNET implementation suggested to me that that approach (dividing by batch size) might be correct, but I’ve had no luck so far finding a learning rate that produces results even close to those obtained using the default reduction (mean).
MXNET question, for reference:
If we replace l = loss(output, y) with l = loss(output, y).mean() , we need to change trainer.step(batch_size) to trainer.step(1) for the code to behave identically. Why?
edit to updated with further progress
I wasn’t paying enough attention to the code. Dividing the step size by 10 doesn’t account for the fact that the loss that’s actually printed incorporates all 1000 observations. So I was consistently off by a factor of 1000 by not dividing loss(net(features), labels) by 1000 when using sum and comparing to the loss using mean. After incorporating this change, dividing the learning rate by the batch size had the desired results (or at least the same order of magnitude; I haven’t made a single version of this working on exactly the same data as I’m still pretty uncertain about automatic differentiation).
So my big question now is: am I still missing something big? I was unable to find a way get the same output using mean and sum reduction changing only the learning rate. Is there a way to do so? I experimented with many different values and was unable to find a way.
Another edit with more testing
I ran the comparison after setting a random seed and was able to obtain identical (not just same order of magnitude) results with reduction='sum' by dividing the learning rate by the batch size and by changing the per-epoch loss calculation to l = loss(net(features), labels)/1000.
The results were not identical when I changed the learning rate to any other value. So I’ve mostly convinced myself that this approach is correct, and it makes intuitive sense to me. But I do think the question implied this could be solved by changing only the learning rate, so I still wonder if I’m missing something there.
Hi @dliden, I think the nature of loss function is not changed whatever you set the reduction to ‘sum’ or ‘mean’. And I think the difference between ‘sum’ and ‘mean’ is loss_mean = loss_sum/1000. Such that when the reduction is set to ‘sum’, the loss is sensitive for a little change of weights. In other words, even if you update the weights a little, the loss will change greatly. What’s worse, you could skip the minimum and the training will never converge. Therefore, you should change the learning rate smaller. Try to set the lr=0.001 and num_epochs=10, you will something different.
how can we change the learning rate for the code to behave identically. Why?
I’m very confused why the learning rate is affected when we set reduction = sum. I have read through the thread and seems they were not talking about the learning rate. I made some experiments and found the training loss was increased tremendously when we set it as sum. Could you explain that to me. Thanks