https://d2l.ai/chapter_natural-language-processing-pretraining/bert.html
1 Like
I don’t quite understand the code below.
# PyTorch by default won't flatten the tensor as seen in mxnet where, if
# flatten=True, all but the first axis of input data are collapsed together
encoded_X = torch.flatten(encoded_X, start_dim=1)
# input_shape for NSP: (batch size, `num_hiddens`)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shape
Might want to change it to something similar to nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :])) in Section 6. Some quotes here:
Hence, the output layer (
self.output) of the MLP classifier takesXas the input, whereXis the output of the MLP hidden layer whose input is the encoded<cls>token.
What is the difference between this encoder
class BERTEncoder(nn.Module):
"""BERT encoder."""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# In BERT, positional embeddings are learnable, thus we create a
# parameter of positional embeddings that are long enough
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# Shape of `X` remains unchanged in the following code snippet:
# (batch size, max sequence length, `num_hiddens`)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
and the huggingface transformers BERT encoder
precisely they don’t seem to care about original tokens list length valid_lens
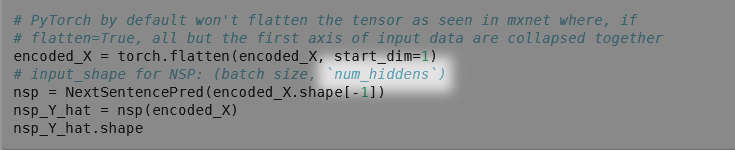
Since X is flattened, I think this should be num_hiddens*max sequence length
Update:
I was wrong, but still quite confused:
- In BERT, we only use the
<cls>inencoded_Xto predict whether the next sentence is correct, so the size of input fornspis indeed(batch_size, num_hiddens)in pre-training.
# The hidden layer of the MLP classifier for next sentence prediction.
# 0 is the index of the '<cls>' token
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
- but as showed in the screenshot above: why do we need to flatten encoded_X in the first place? Shouldn’t it be the same as the code down below:
encoded_X[:, 0, :]?
are you interested to support me on Afan Oromo Text Semantic Role labeling using deep learning model with BERT Algortihm
it seems that you asked similar question twice.
the text is vapid, just focus on the code block is the right way. so the figure you given is only a demo to show how to use NSP.
