It is so quick and it only spent <5 mins to train on my cpu. 
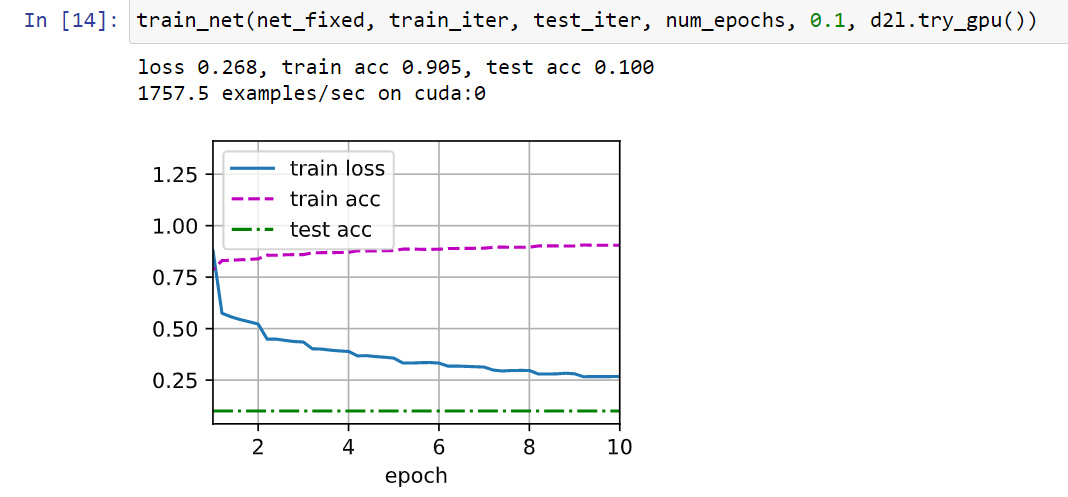
loss 0.246, train acc 0.909, test acc 0.878
3313.6 examples/sec on cpu
Exercises and mysilly answers
- Can we remove the bias parameter from the fully-connected layer or the convolutional layer
before the batch normalization? Why?
- Since batchnorm already includes bias, and also shift by mean any constant would be cancelled out therefore, it makes no sense to add bias.
-
Compare the learning rates for LeNet with and without batch normalization.
-
Plot the increase in training and test accuracy.
- with batchnorm the accuracy = 0.962 at lr 1.0
- without batchnorm the accuracy 0.931 at lr 0.1
-
How large can you make the learning rate?
- tried with 1.0
-
Do we need batch normalization in every layer? Experiment with it?
- okay. tried it is surprisingly giving accuracy of 94.6
-
Can you replace dropout by batch normalization? How does the behavior change?
In the Ioffe and Szegedy 2015, the authors state that “we would like to ensure that for any parameter values, the network always produces activations with the desired distribution”. So the Batch Normalization Layer is actually inserted right after a Conv Layer/Fully Connected Layer, but before feeding into ReLu (or any other kinds of) activation. See this video at around time 53 min for more details.
As far as dropout goes, I believe dropout is applied after activation layer. In the dropout paper figure 3b, the dropout factor/probability matrix r(l) for hidden layer l is applied to it on y(l), where y(l) is the result after applying activation function f.
So in summary, the order of using batch normalization and dropout is:
-> CONV/FC -> BatchNorm -> ReLu(or other activation) -> Dropout -> CONV/FC ->
-
Fix the parameters beta and gamma, and observe and analyze the results.
- okay. If it means fixing moving averages then I did it.
-
Review the online documentation for BatchNorm from the high-level APIs to see the other
applications for batch normalization.
https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html
``Our method draws its strength from making normalization a part of the model architecture and performing the
normalization for each training mini-batch. Batch Normalization allows us to use much higher learning rates and
be less careful about initialization. It also acts as a regularizer, in some cases eliminating the need for Dropout.
Applied to a state-of-the-art image classification model,
Batch Normalization achieves the same accuracy with 14
times fewer training steps, and beats the original model
by a significant margin.```
- Research ideas: think of other normalization transforms that you can apply?
Can you apply the probability integral transform?
in probability theory, the probability integral transform (also known as universality of the uniform) relates to the result that data values that are modeled as being random variables from any given continuous distribution can be converted to random variables having a standard uniform distribution.[1] This holds exactly provided that the distribution being used is the true distribution of the random variables; if the distribution is one fitted to the data, the result will hold approximately in large samples.
How about a full rank covariance estimate?
- did not get it
yeah lenet is refreshingly easy to train.
Do we need to extract the attribute data from two tensors moving_mean and moving_var as in the last line of the function batch_norm ? I understand that the attribute getter data of a torch.nn.Parameter object gives us its backbone torch.Tensor, but in this case moving_mean and moving_var are already torch.Tensor objects. In other words, shoudn’t
return Y, moving_mean.data, moving_var.data
be simply
return Y, moving_mean, moving_var
How the scale parameter 𝜸 and shift parameter 𝜷 are being updated? Does it update the same way as conv layer’s weights?
Yes, they are trainable parameters too, just like every other weight or bias in the network.
In the final section the author leave a few sections about analyzing the convergence and trainabillity of DNN’s in the air.
I reacommend the book: Asymptotic Analysis and Peturbation Theory by William Paulsen.
This covers a range of tequniques for constructing such proofs.
- Compare the learning rates for LeNet with and without batch normalization.
1.1. Plot the increase in validation accuracy.
1.2. How large can you make the learning rate before the optimization fails in both cases?
- I got to lr =3.3, LeNet5 ; with val_acc = 0.8077
- lr=1.3, BNLeNet5 , no bias; val_acc = 0.8933939873417721
based on this https://discuss.pytorch.org/t/the-difference-between-torch-tensor-data-and-torch-tensor/25995/6
it should be
return Y, moving_mean, moving_var