https://d2l.ai/chapter_attention-mechanisms-and-transformers/bahdanau-attention.html
Hi,
In chapter 10.4.1:
- where the decoder hidden state st′−1st′−1 at time step t′−1t′−1 is the query, and the encoder hidden states htht are both the keys and values,
However, in the code implementation:
- context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
I think that the keys and values are enc_outputs instead of the encoder hidden states h_t. Is it a mistake?
Please correct me if I am wrong!
Yes,I’m confused,too!
I think you have already pointed out the difference: s_{t’-1} is the decoder hidden state. It is the input of
" out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state) "
I don’t think the encoder hidden state h_t is used as a decoder hidden state. It is clearly stated that h_t is a key.


I wonder why there is an arrow pointing from the recurrent layer of the encoder towards to recurrent layer of the decoder. I thought the context variable is already handled by the attention mechanism?
I find out that we can save a lot of GPU memory by using:
hidden_state.detach()
in Seq2SeqAttentionDecoder class, forward function when we loop for each num_steps.
More information: Michael Jungo answer
Change from adaptive attention to dot product attention will increase the training speed. Change from GRU to LSTM will decrease the training speed.
1 Like
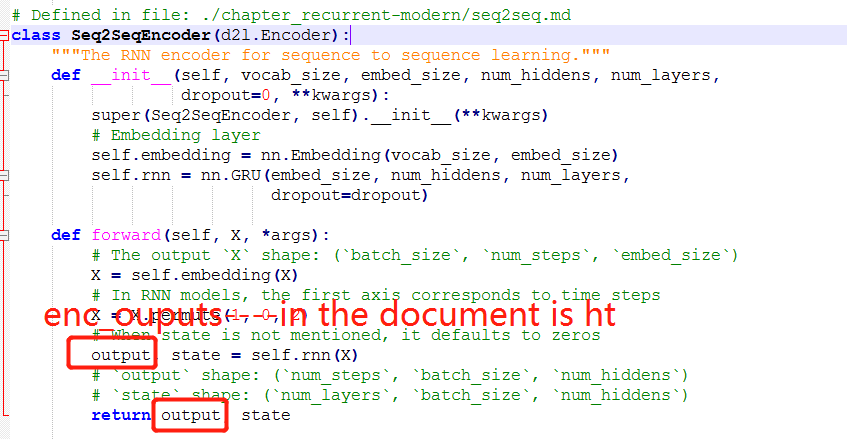
The enc_outputs in the encoder are totally equal to the hidden states, because they haven’t gone into the FC layer.
You can’t use the variable “hidden_state” of encoder since it only record the state of the final time step.
1 Like
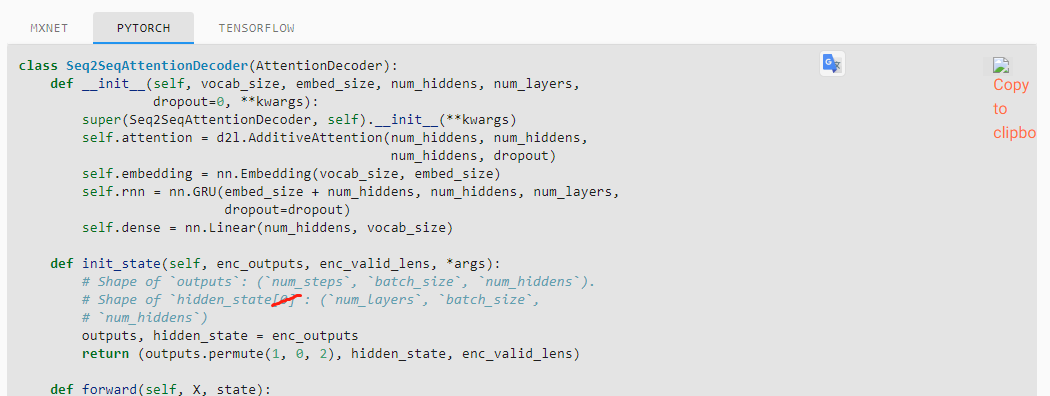
I wonder why state[0] and state[1] have different shapes.
there is a problem in Seq2SeqAttentionDecoder.init_state ‘enc_outputs’ should be changed as ‘outputs’
中文版能上tensorflow的代码吗?
另外,tensorflow对版本有要求吗,我用的是1.15,运行代码有报错
same feeling here. Moreover if you want to have different number of hidden dim in encoder and decoder , then you cannot do this operation.
You are right. I was also confused, then I checked that the final element of outputs and hidden_state are actually equal. Thank you!
The enc_outputs in the encoder actually are a little different from hidden_states, because the enc_outputs is the last layer of hidden_states at each time step. And hidden_states have only kept the parameters on the last timestep.
More specifically, enc_outputs shape is (num_timestep, num_batch, num_hiddens), while hidden_states shape is (num_layer, num_batch, num_hiddens) here.
The enc_outputs[-1, …] equals to hidden_state[-1, …].
Yes, you are right. We should figure out the true hidden state and the variable “hidden_state”. You know, every time step has a hidden state, and it equals to the output if there isn’t a FC layer. Then the variable “hidden_state” just mean the state of last time step.
d2l模块里面没有Decoder呢?大家的都有吗,我去github上看也没有找到呢
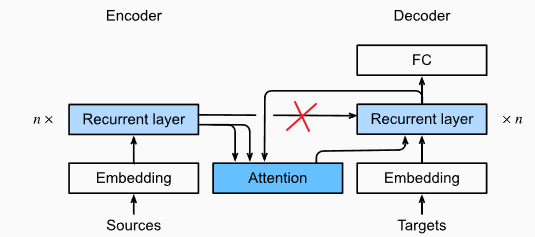
do you mean the arrow with a red cross? same feeling here.
conda activate d2l
在d2l这个env里就有了