https://d2l.ai/chapter_computational-performance/auto-parallelism.html
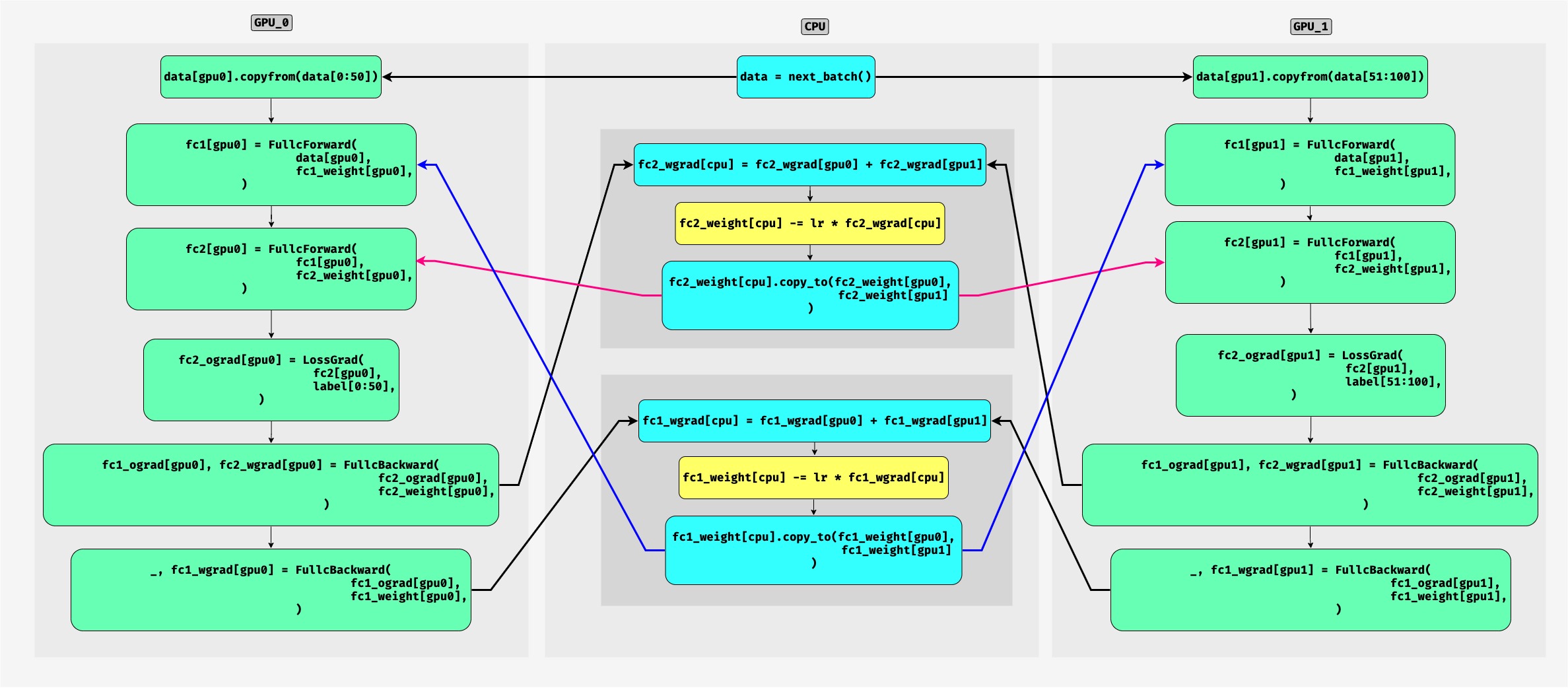
For multi-SPU training, shouldn’t we use the aggregated gradients to update the weights? The 3rd and 6th blue boxes in Fig. 12.3.1 suggest that weight update is based on unaggregated grad from GPU0. Please advise.
1 Like
@Nima_Tajbakhsh, Yes, I was also confused by this. I think its a typo.
I have attached the corrected version below (in yellow boxes).
Hope it helps.